 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaVeRL-SQL: Text-to-SQL via Partial-Match Rewards and Verbal Reinforcement Learning
Sep 08, 2025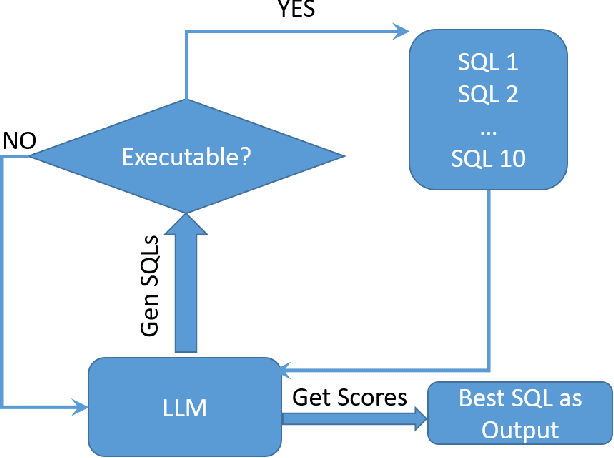
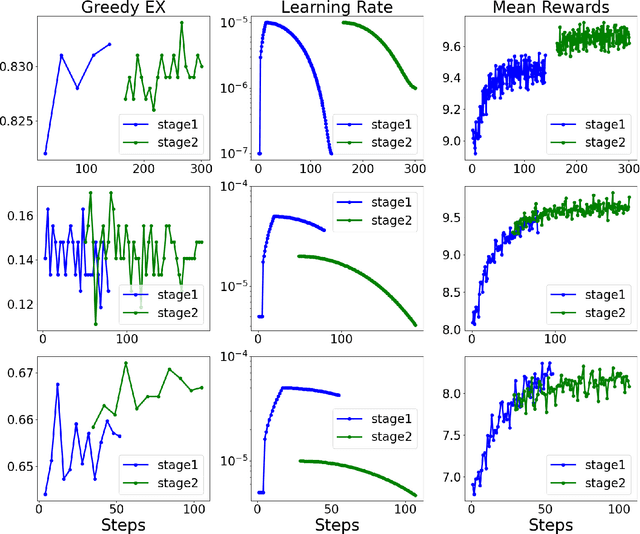
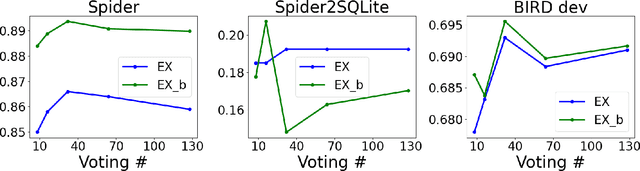
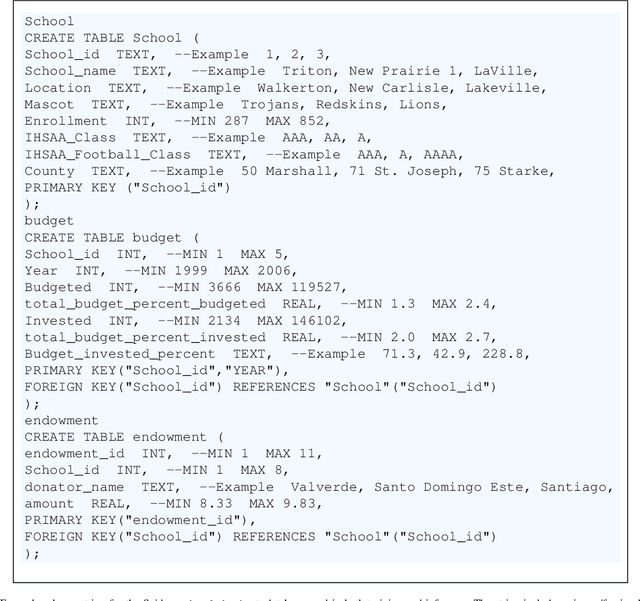
Text-to-SQL models allow users to interact with a database more easily by generating executable SQL statements from natural-language questions. Despite recent successes on simpler databases and questions, current Text-to-SQL methods still suffer from low execution accuracy on industry-scale databases and complex questions involving domain-specific business logic. We present \emph{PaVeRL-SQL}, a framework that combines \emph{Partial-Match Rewards} and \emph{Verbal Reinforcement Learning} to drive self-improvement in reasoning language models (RLMs) for Text-to-SQL. To handle practical use cases, we adopt two pipelines: (1) a newly designed in-context learning framework with group self-evaluation (verbal-RL), using capable open- and closed-source large language models (LLMs) as backbones; and (2) a chain-of-thought (CoT) RL pipeline with a small backbone model (OmniSQL-7B) trained with a specially designed reward function and two-stage RL. These pipelines achieve state-of-the-art (SOTA) results on popular Text-to-SQL benchmarks -- Spider, Spider 2.0, and BIRD. For the industrial-level Spider2.0-SQLite benchmark, the verbal-RL pipeline achieves an execution accuracy 7.4\% higher than SOTA, and the CoT pipeline is 1.4\% higher. RL training with mixed SQL dialects yields strong, threefold gains, particularly for dialects with limited training data. Overall, \emph{PaVeRL-SQL} delivers reliable, SOTA Text-to-SQL under realistic industrial constraints. The code is available at https://github.com/PaVeRL-SQL/PaVeRL-SQL.
Bayesian Active Learning for Semantic Segmentation
Aug 03, 2024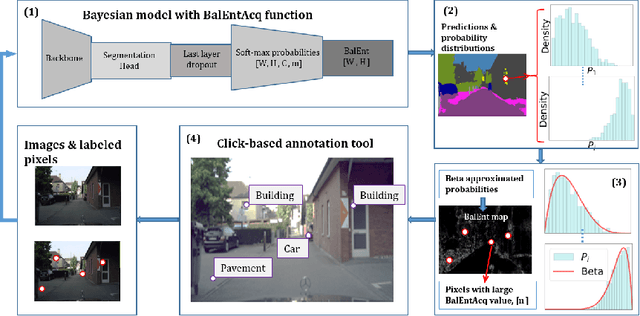



Fully supervised training of semantic segmentation models is costly and challenging because each pixel within an image needs to be labeled. Therefore, the sparse pixel-level annotation methods have been introduced to train models with a subset of pixels within each image. We introduce a Bayesian active learning framework based on sparse pixel-level annotation that utilizes a pixel-level Bayesian uncertainty measure based on Balanced Entropy (BalEnt) [84]. BalEnt captures the information between the models' predicted marginalized probability distribution and the pixel labels. BalEnt has linear scalability with a closed analytical form and can be calculated independently per pixel without relational computations with other pixels. We train our proposed active learning framework for Cityscapes, Camvid, ADE20K and VOC2012 benchmark datasets and show that it reaches supervised levels of mIoU using only a fraction of labeled pixels while outperforming the previous state-of-the-art active learning models with a large margin.
Improving Instruction Following in Language Models through Proxy-Based Uncertainty Estimation
May 10, 2024



Assessing response quality to instructions in language models is vital but challenging due to the complexity of human language across different contexts. This complexity often results in ambiguous or inconsistent interpretations, making accurate assessment difficult. To address this issue, we propose a novel Uncertainty-aware Reward Model (URM) that introduces a robust uncertainty estimation for the quality of paired responses based on Bayesian approximation. Trained with preference datasets, our uncertainty-enabled proxy not only scores rewards for responses but also evaluates their inherent uncertainty. Empirical results demonstrate significant benefits of incorporating the proposed proxy into language model training. Our method boosts the instruction following capability of language models by refining data curation for training and improving policy optimization objectives, thereby surpassing existing methods by a large margin on benchmarks such as Vicuna and MT-bench. These findings highlight that our proposed approach substantially advances language model training and paves a new way of harnessing uncertainty within language models.
BiHPF: Bilateral High-Pass Filters for Robust Deepfake Detection
Aug 16, 2021

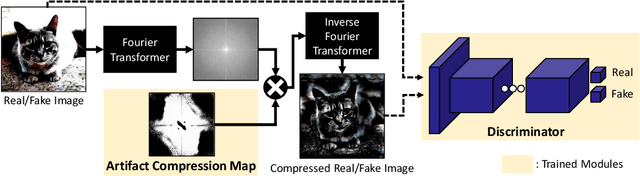
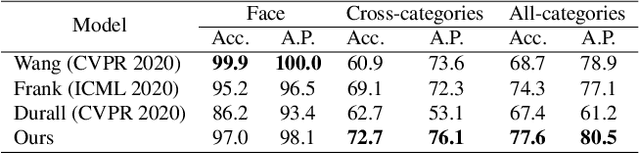
The advancement in numerous generative models has a two-fold effect: a simple and easy generation of realistic synthesized images, but also an increased risk of malicious abuse of those images. Thus, it is important to develop a generalized detector for synthesized images of any GAN model or object category, including those unseen during the training phase. However, the conventional methods heavily depend on the training settings, which cause a dramatic decline in performance when tested with unknown domains. To resolve the issue and obtain a generalized detection ability, we propose Bilateral High-Pass Filters (BiHPF), which amplify the effect of the frequency-level artifacts that are known to be found in the synthesized images of generative models. Numerous experimental results validate that our method outperforms other state-of-the-art methods, even when tested with unseen domains.
KoreALBERT: Pretraining a Lite BERT Model for Korean Language Understanding
Jan 27, 2021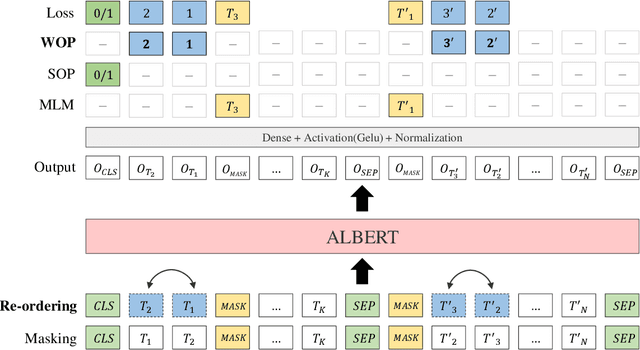
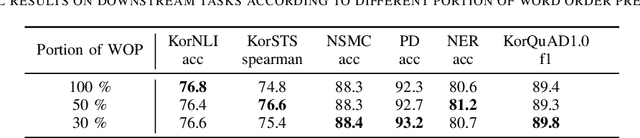

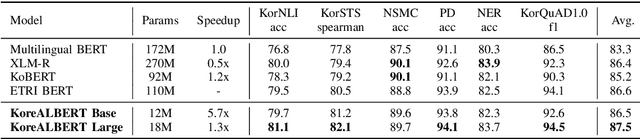
A Lite BERT (ALBERT) has been introduced to scale up deep bidirectional representation learning for natural languages. Due to the lack of pretrained ALBERT models for Korean language, the best available practice is the multilingual model or resorting back to the any other BERT-based model. In this paper, we develop and pretrain KoreALBERT, a monolingual ALBERT model specifically for Korean language understanding. We introduce a new training objective, namely Word Order Prediction (WOP), and use alongside the existing MLM and SOP criteria to the same architecture and model parameters. Despite having significantly fewer model parameters (thus, quicker to train), our pretrained KoreALBERT outperforms its BERT counterpart on 6 different NLU tasks. Consistent with the empirical results in English by Lan et al., KoreALBERT seems to improve downstream task performance involving multi-sentence encoding for Korean language. The pretrained KoreALBERT is publicly available to encourage research and application development for Korean NLP.
Analyzing Zero-shot Cross-lingual Transfer in Supervised NLP Tasks
Jan 26, 2021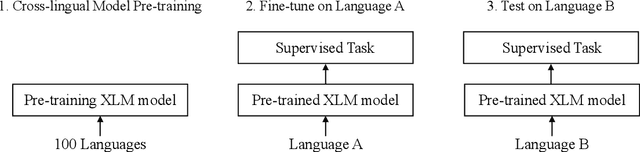
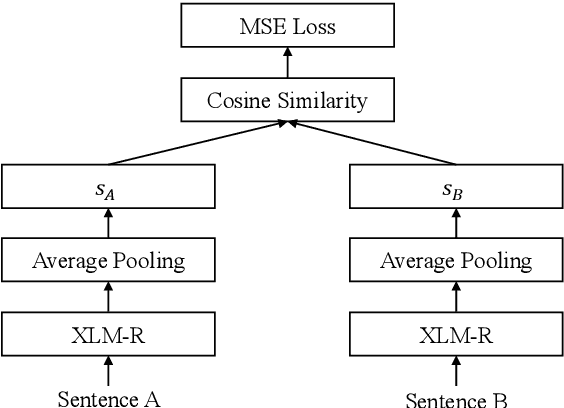
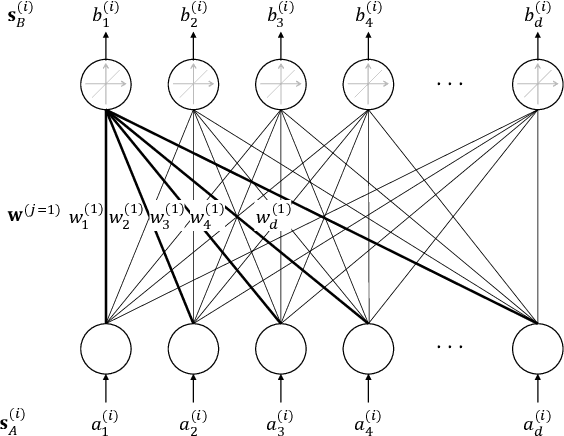
In zero-shot cross-lingual transfer, a supervised NLP task trained on a corpus in one language is directly applicable to another language without any additional training. A source of cross-lingual transfer can be as straightforward as lexical overlap between languages (e.g., use of the same scripts, shared subwords) that naturally forces text embeddings to occupy a similar representation space. Recently introduced cross-lingual language model (XLM) pretraining brings out neural parameter sharing in Transformer-style networks as the most important factor for the transfer. In this paper, we aim to validate the hypothetically strong cross-lingual transfer properties induced by XLM pretraining. Particularly, we take XLM-RoBERTa (XLMR) in our experiments that extend semantic textual similarity (STS), SQuAD and KorQuAD for machine reading comprehension, sentiment analysis, and alignment of sentence embeddings under various cross-lingual settings. Our results indicate that the presence of cross-lingual transfer is most pronounced in STS, sentiment analysis the next, and MRC the last. That is, the complexity of a downstream task softens the degree of crosslingual transfer. All of our results are empirically observed and measured, and we make our code and data publicly available.
SelfMatch: Combining Contrastive Self-Supervision and Consistency for Semi-Supervised Learning
Jan 16, 2021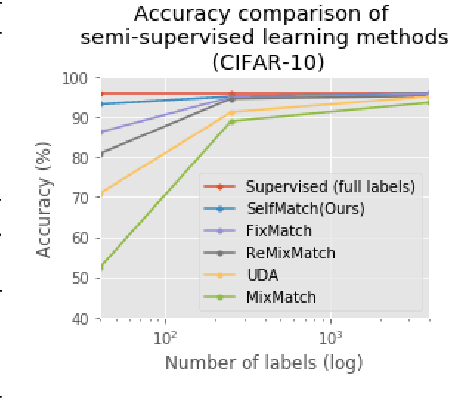
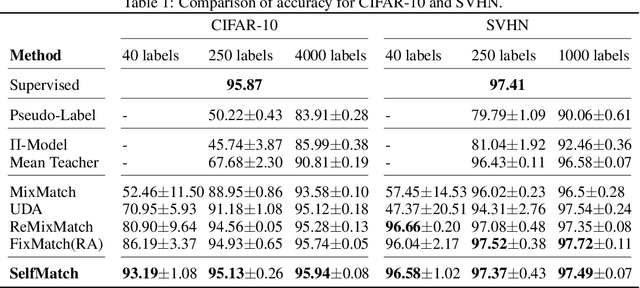
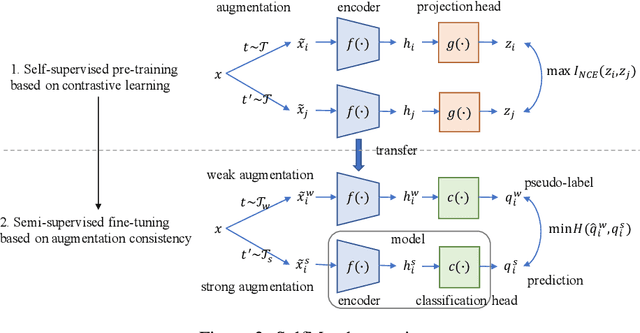

This paper introduces SelfMatch, a semi-supervised learning method that combines the power of contrastive self-supervised learning and consistency regularization. SelfMatch consists of two stages: (1) self-supervised pre-training based on contrastive learning and (2) semi-supervised fine-tuning based on augmentation consistency regularization. We empirically demonstrate that SelfMatch achieves the state-of-the-art results on standard benchmark datasets such as CIFAR-10 and SVHN. For example, for CIFAR-10 with 40 labeled examples, SelfMatch achieves 93.19% accuracy that outperforms the strong previous methods such as MixMatch (52.46%), UDA (70.95%), ReMixMatch (80.9%), and FixMatch (86.19%). We note that SelfMatch can close the gap between supervised learning (95.87%) and semi-supervised learning (93.19%) by using only a few labels for each class.
POMO: Policy Optimization with Multiple Optima for Reinforcement Learning
Oct 30, 2020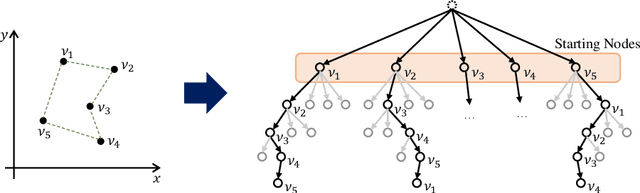

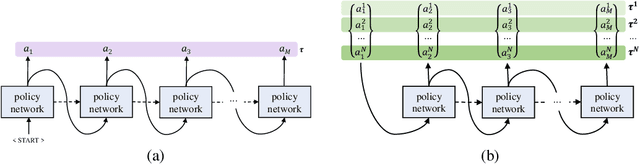
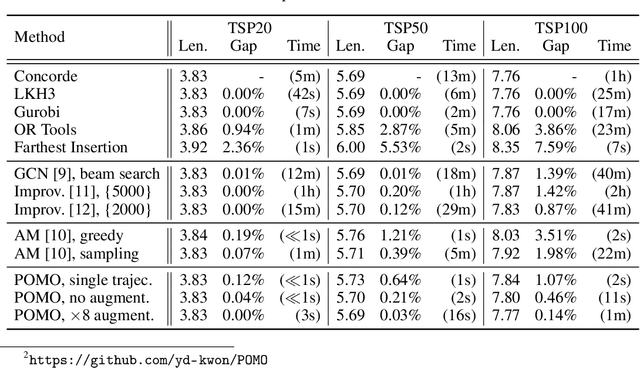
In neural combinatorial optimization (CO), reinforcement learning (RL) can turn a deep neural net into a fast, powerful heuristic solver of NP-hard problems. This approach has a great potential in practical applications because it allows near-optimal solutions to be found without expert guides armed with substantial domain knowledge. We introduce Policy Optimization with Multiple Optima (POMO), an end-to-end approach for building such a heuristic solver. POMO is applicable to a wide range of CO problems. It is designed to exploit the symmetries in the representation of a CO solution. POMO uses a modified REINFORCE algorithm that forces diverse rollouts towards all optimal solutions. Empirically, the low-variance baseline of POMO makes RL training fast and stable, and it is more resistant to local minima compared to previous approaches. We also introduce a new augmentation-based inference method, which accompanies POMO nicely. We demonstrate the effectiveness of POMO by solving three popular NP-hard problems, namely, traveling salesman (TSP), capacitated vehicle routing (CVRP), and 0-1 knapsack (KP). For all three, our solver based on POMO shows a significant improvement in performance over all recent learned heuristics. In particular, we achieve the optimality gap of 0.14% with TSP100 while reducing inference time by more than an order of magnitude.