 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Zero-shot Cross-lingual Transfer in Supervised NLP Tasks
Jan 26, 2021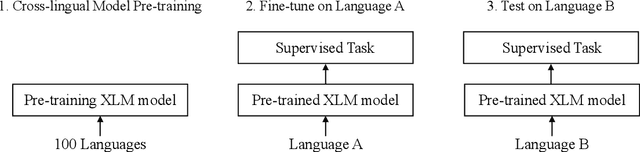
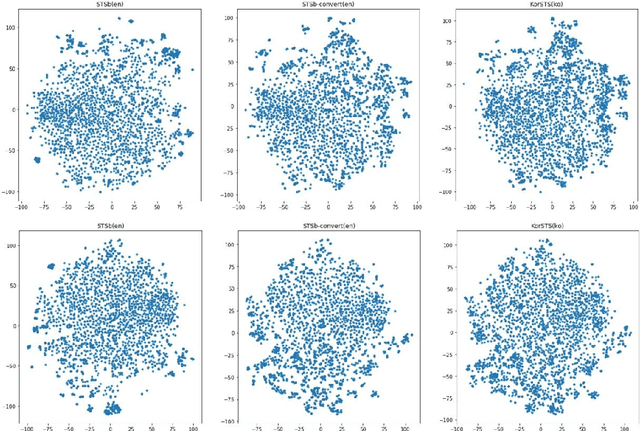
In zero-shot cross-lingual transfer, a supervised NLP task trained on a corpus in one language is directly applicable to another language without any additional training. A source of cross-lingual transfer can be as straightforward as lexical overlap between languages (e.g., use of the same scripts, shared subwords) that naturally forces text embeddings to occupy a similar representation space. Recently introduced cross-lingual language model (XLM) pretraining brings out neural parameter sharing in Transformer-style networks as the most important factor for the transfer. In this paper, we aim to validate the hypothetically strong cross-lingual transfer properties induced by XLM pretraining. Particularly, we take XLM-RoBERTa (XLMR) in our experiments that extend semantic textual similarity (STS), SQuAD and KorQuAD for machine reading comprehension, sentiment analysis, and alignment of sentence embeddings under various cross-lingual settings. Our results indicate that the presence of cross-lingual transfer is most pronounced in STS, sentiment analysis the next, and MRC the last. That is, the complexity of a downstream task softens the degree of crosslingual transfer. All of our results are empirically observed and measured, and we make our code and data publicly available.
Evaluation of BERT and ALBERT Sentence Embedding Performance on Downstream NLP Tasks
Jan 26, 2021



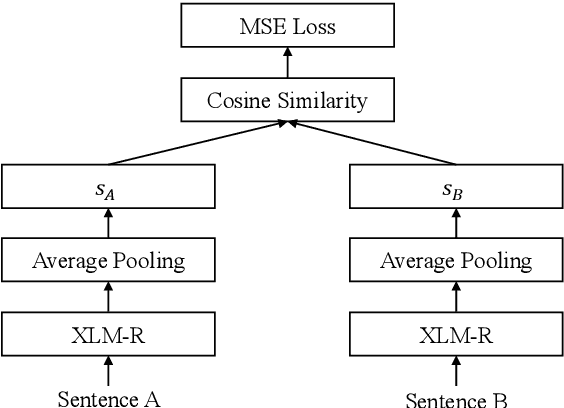
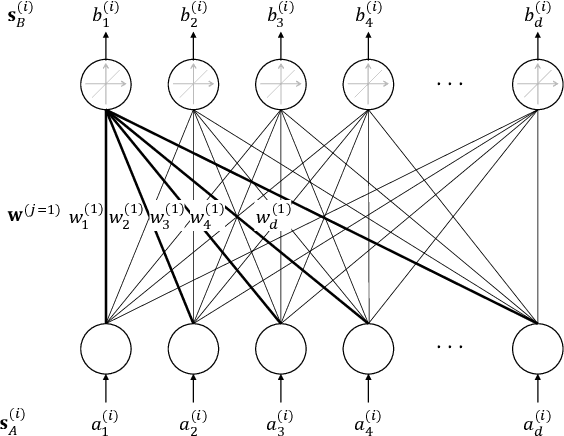
Contextualized representations from a pre-trained language model are central to achieve a high performance on downstream NLP task. The pre-trained BERT and A Lite BERT (ALBERT) models can be fine-tuned to give state-ofthe-art results in sentence-pair regressions such as semantic textual similarity (STS) and natural language inference (NLI). Although BERT-based models yield the [CLS] token vector as a reasonable sentence embedding, the search for an optimal sentence embedding scheme remains an active research area in computational linguistics. This paper explores on sentence embedding models for BERT and ALBERT. In particular, we take a modified BERT network with siamese and triplet network structures called Sentence-BERT (SBERT) and replace BERT with ALBERT to create Sentence-ALBERT (SALBERT). We also experiment with an outer CNN sentence-embedding network for SBERT and SALBERT. We evaluate performances of all sentence-embedding models considered using the STS and NLI datasets. The empirical results indicate that our CNN architecture improves ALBERT models substantially more than BERT models for STS benchmark. Despite significantly fewer model parameters, ALBERT sentence embedding is highly competitive to BERT in downstream NLP evaluations.