 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask2Flow-TSE: Two-Stage Target Speaker Extraction with Masking and Flow Matching
Mar 13, 2026Target speaker extraction (TSE) extracts the target speaker's voice from overlapping speech mixtures given a reference utterance. Existing approaches typically fall into two categories: discriminative and generative. Discriminative methods apply time-frequency masking for fast inference but often over-suppress the target signal, while generative methods synthesize high-quality speech at the cost of numerous iterative steps. We propose Mask2Flow-TSE, a two-stage framework combining the strengths of both paradigms. The first stage applies discriminative masking for coarse separation, and the second stage employs flow matching to refine the output toward target speech. Unlike generative approaches that synthesize speech from Gaussian noise, our method starts from the masked spectrogram, enabling high-quality reconstruction in a single inference step. Experiments show that Mask2Flow-TSE achieves comparable performance to existing generative TSE methods with approximately 85M parameters.
Label Space Partition Selection for Multi-Object Tracking Using Two-Layer Partitioning
Oct 23, 2023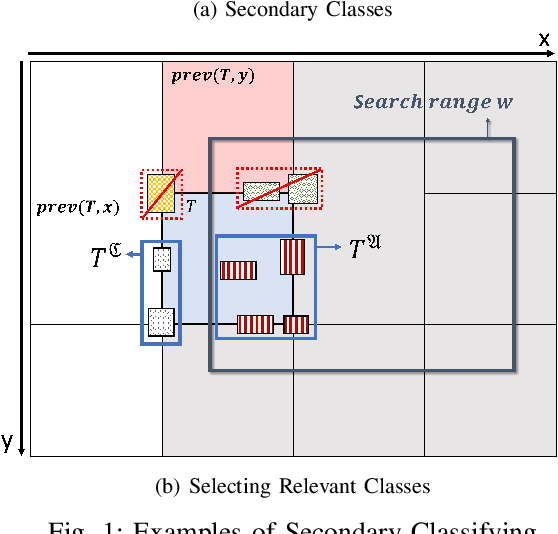
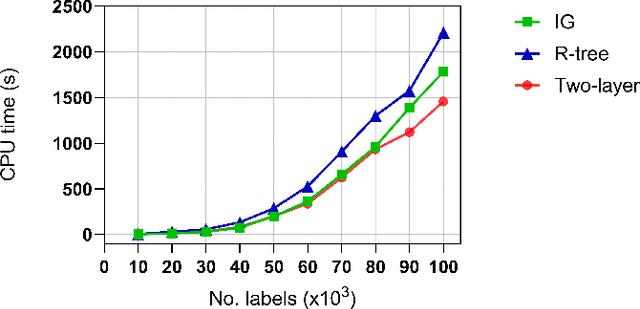
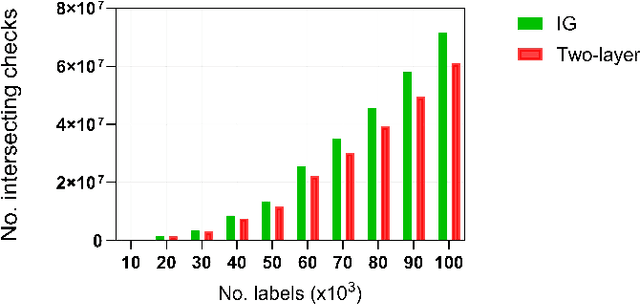
Estimating the trajectories of multi-objects poses a significant challenge due to data association ambiguity, which leads to a substantial increase in computational requirements. To address such problems, a divide-and-conquer manner has been employed with parallel computation. In this strategy, distinguished objects that have unique labels are grouped based on their statistical dependencies, the intersection of predicted measurements. Several geometry approaches have been used for label grouping since finding all intersected label pairs is clearly infeasible for large-scale tracking problems. This paper proposes an efficient implementation of label grouping for label-partitioned generalized labeled multi-Bernoulli filter framework using a secondary partitioning technique. This allows for parallel computation in the label graph indexing step, avoiding generating and eliminating duplicate comparisons. Additionally, we compare the performance of the proposed technique with several efficient spatial searching algorithms. The results demonstrate the superior performance of the proposed approach on large-scale data sets, enabling scalable trajectory estimation.
Is Cross-modal Information Retrieval Possible without Training?
Apr 20, 2023Encoded representations from a pretrained deep learning model (e.g., BERT text embeddings, penultimate CNN layer activations of an image) convey a rich set of features beneficial for information retrieval. Embeddings for a particular modality of data occupy a high-dimensional space of its own, but it can be semantically aligned to another by a simple mapping without training a deep neural net. In this paper, we take a simple mapping computed from the least squares and singular value decomposition (SVD) for a solution to the Procrustes problem to serve a means to cross-modal information retrieval. That is, given information in one modality such as text, the mapping helps us locate a semantically equivalent data item in another modality such as image. Using off-the-shelf pretrained deep learning models, we have experimented the aforementioned simple cross-modal mappings in tasks of text-to-image and image-to-text retrieval. Despite simplicity, our mappings perform reasonably well reaching the highest accuracy of 77% on recall@10, which is comparable to those requiring costly neural net training and fine-tuning. We have improved the simple mappings by contrastive learning on the pretrained models. Contrastive learning can be thought as properly biasing the pretrained encoders to enhance the cross-modal mapping quality. We have further improved the performance by multilayer perceptron with gating (gMLP), a simple neural architecture.
Analyzing Zero-shot Cross-lingual Transfer in Supervised NLP Tasks
Jan 26, 2021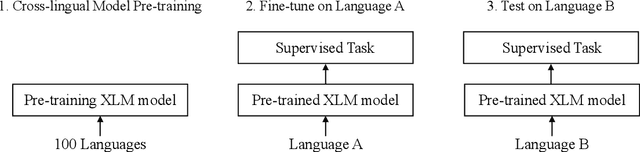
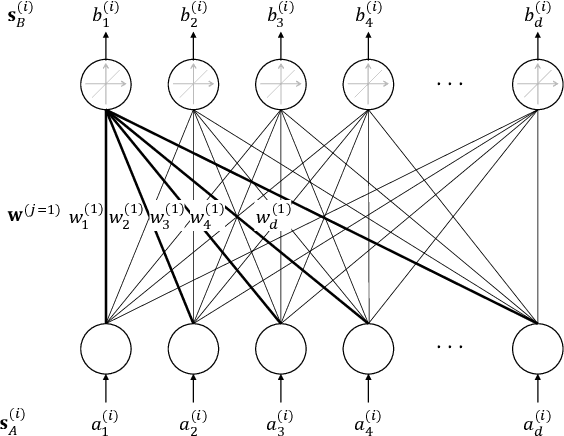
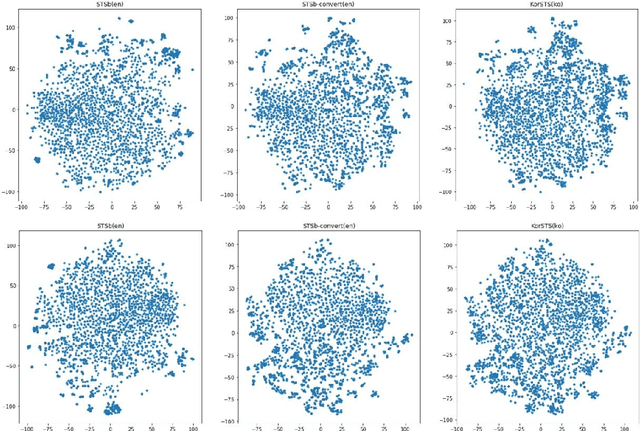
In zero-shot cross-lingual transfer, a supervised NLP task trained on a corpus in one language is directly applicable to another language without any additional training. A source of cross-lingual transfer can be as straightforward as lexical overlap between languages (e.g., use of the same scripts, shared subwords) that naturally forces text embeddings to occupy a similar representation space. Recently introduced cross-lingual language model (XLM) pretraining brings out neural parameter sharing in Transformer-style networks as the most important factor for the transfer. In this paper, we aim to validate the hypothetically strong cross-lingual transfer properties induced by XLM pretraining. Particularly, we take XLM-RoBERTa (XLMR) in our experiments that extend semantic textual similarity (STS), SQuAD and KorQuAD for machine reading comprehension, sentiment analysis, and alignment of sentence embeddings under various cross-lingual settings. Our results indicate that the presence of cross-lingual transfer is most pronounced in STS, sentiment analysis the next, and MRC the last. That is, the complexity of a downstream task softens the degree of crosslingual transfer. All of our results are empirically observed and measured, and we make our code and data publicly available.
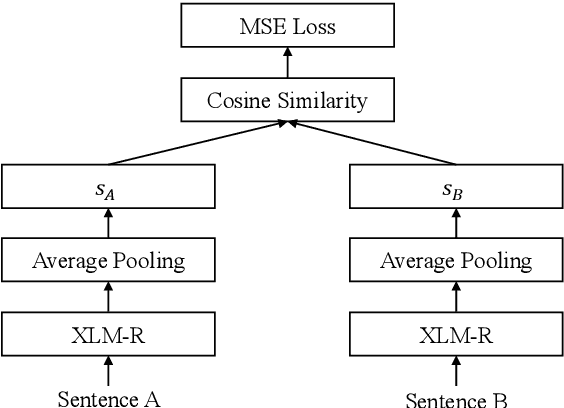
Evaluation of BERT and ALBERT Sentence Embedding Performance on Downstream NLP Tasks
Jan 26, 2021



Contextualized representations from a pre-trained language model are central to achieve a high performance on downstream NLP task. The pre-trained BERT and A Lite BERT (ALBERT) models can be fine-tuned to give state-ofthe-art results in sentence-pair regressions such as semantic textual similarity (STS) and natural language inference (NLI). Although BERT-based models yield the [CLS] token vector as a reasonable sentence embedding, the search for an optimal sentence embedding scheme remains an active research area in computational linguistics. This paper explores on sentence embedding models for BERT and ALBERT. In particular, we take a modified BERT network with siamese and triplet network structures called Sentence-BERT (SBERT) and replace BERT with ALBERT to create Sentence-ALBERT (SALBERT). We also experiment with an outer CNN sentence-embedding network for SBERT and SALBERT. We evaluate performances of all sentence-embedding models considered using the STS and NLI datasets. The empirical results indicate that our CNN architecture improves ALBERT models substantially more than BERT models for STS benchmark. Despite significantly fewer model parameters, ALBERT sentence embedding is highly competitive to BERT in downstream NLP evaluations.
DefogGAN: Predicting Hidden Information in the StarCraft Fog of War with Generative Adversarial Nets
Mar 15, 2020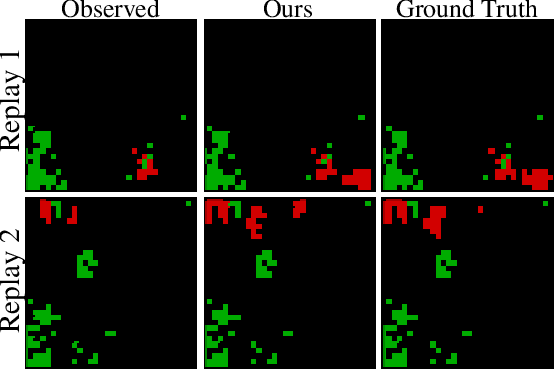
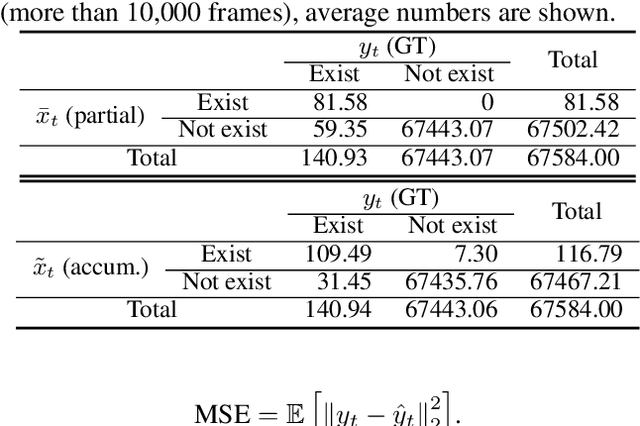
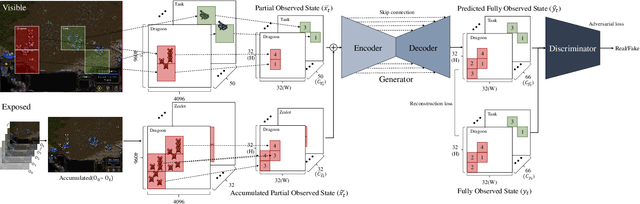
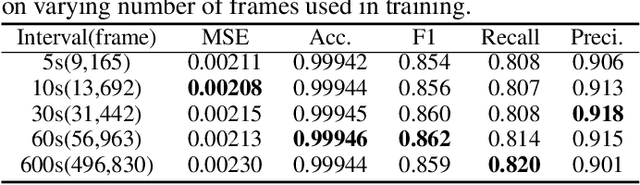
We propose DefogGAN, a generative approach to the problem of inferring state information hidden in the fog of war for real-time strategy (RTS) games. Given a partially observed state, DefogGAN generates defogged images of a game as predictive information. Such information can lead to create a strategic agent for the game. DefogGAN is a conditional GAN variant featuring pyramidal reconstruction loss to optimize on multiple feature resolution scales.We have validated DefogGAN empirically using a large dataset of professional StarCraft replays. Our results indicate that DefogGAN can predict the enemy buildings and combat units as accurately as professional players do and achieves a superior performance among state-of-the-art defoggers.
Clear the Fog: Combat Value Assessment in Incomplete Information Games with Convolutional Encoder-Decoders
Nov 30, 2018StarCraft, one of the most popular real-time strategy games, is a compelling environment for artificial intelligence research for both micro-level unit control and macro-level strategic decision making. In this study, we address an eminent problem concerning macro-level decision making, known as the 'fog-of-war', which rises naturally from the fact that information regarding the opponent's state is always provided in the incomplete form. For intelligent agents to play like human players, it is obvious that making accurate predictions of the opponent's status under incomplete information will increase its chance of winning. To reflect this fact, we propose a convolutional encoder-decoder architecture that predicts potential counts and locations of the opponent's units based on only partially visible and noisy information. To evaluate the performance of our proposed method, we train an additional classifier on the encoder-decoder output to predict the game outcome (win or lose). Finally, we designed an agent incorporating the proposed method and conducted simulation games against rule-based agents to demonstrate both effectiveness and practicality. All experiments were conducted on actual game replay data acquired from professional players.