 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGuard-v1: Safety Guardrail for Large Language Models
Nov 16, 2025We present SGuard-v1, a lightweight safety guardrail for Large Language Models (LLMs), which comprises two specialized models to detect harmful content and screen adversarial prompts in human-AI conversational settings. The first component, ContentFilter, is trained to identify safety risks in LLM prompts and responses in accordance with the MLCommons hazard taxonomy, a comprehensive framework for trust and safety assessment of AI. The second component, JailbreakFilter, is trained with a carefully designed curriculum over integrated datasets and findings from prior work on adversarial prompting, covering 60 major attack types while mitigating false-unsafe classification. SGuard-v1 is built on the 2B-parameter Granite-3.3-2B-Instruct model that supports 12 languages. We curate approximately 1.4 million training instances from both collected and synthesized data and perform instruction tuning on the base model, distributing the curated data across the two component according to their designated functions. Through extensive evaluation on public and proprietary safety benchmarks, SGuard-v1 achieves state-of-the-art safety performance while remaining lightweight, thereby reducing deployment overhead. SGuard-v1 also improves interpretability for downstream use by providing multi-class safety predictions and their binary confidence scores. We release the SGuard-v1 under the Apache-2.0 License to enable further research and practical deployment in AI safety.
Is Cross-modal Information Retrieval Possible without Training?
Apr 20, 2023Encoded representations from a pretrained deep learning model (e.g., BERT text embeddings, penultimate CNN layer activations of an image) convey a rich set of features beneficial for information retrieval. Embeddings for a particular modality of data occupy a high-dimensional space of its own, but it can be semantically aligned to another by a simple mapping without training a deep neural net. In this paper, we take a simple mapping computed from the least squares and singular value decomposition (SVD) for a solution to the Procrustes problem to serve a means to cross-modal information retrieval. That is, given information in one modality such as text, the mapping helps us locate a semantically equivalent data item in another modality such as image. Using off-the-shelf pretrained deep learning models, we have experimented the aforementioned simple cross-modal mappings in tasks of text-to-image and image-to-text retrieval. Despite simplicity, our mappings perform reasonably well reaching the highest accuracy of 77% on recall@10, which is comparable to those requiring costly neural net training and fine-tuning. We have improved the simple mappings by contrastive learning on the pretrained models. Contrastive learning can be thought as properly biasing the pretrained encoders to enhance the cross-modal mapping quality. We have further improved the performance by multilayer perceptron with gating (gMLP), a simple neural architecture.
D2CSE: Difference-aware Deep continuous prompts for Contrastive Sentence Embeddings
Apr 18, 2023This paper describes Difference-aware Deep continuous prompt for Contrastive Sentence Embeddings (D2CSE) that learns sentence embeddings. Compared to state-of-the-art approaches, D2CSE computes sentence vectors that are exceptional to distinguish a subtle difference in similar sentences by employing a simple neural architecture for continuous prompts. Unlike existing architectures that require multiple pretrained language models (PLMs) to process a pair of the original and corrupted (subtly modified) sentences, D2CSE avoids cumbersome fine-tuning of multiple PLMs by only optimizing continuous prompts by performing multiple tasks -- i.e., contrastive learning and conditional replaced token detection all done in a self-guided manner. D2CSE overloads a single PLM on continuous prompts and greatly saves memory consumption as a result. The number of training parameters in D2CSE is reduced to about 1\% of existing approaches while substantially improving the quality of sentence embeddings. We evaluate D2CSE on seven Semantic Textual Similarity (STS) benchmarks, using three different metrics, namely, Spearman's rank correlation, recall@K for a retrieval task, and the anisotropy of an embedding space measured in alignment and uniformity. Our empirical results suggest that shallow (not too meticulously devised) continuous prompts can be honed effectively for multiple NLP tasks and lead to improvements upon existing state-of-the-art approaches.
KoreALBERT: Pretraining a Lite BERT Model for Korean Language Understanding
Jan 27, 2021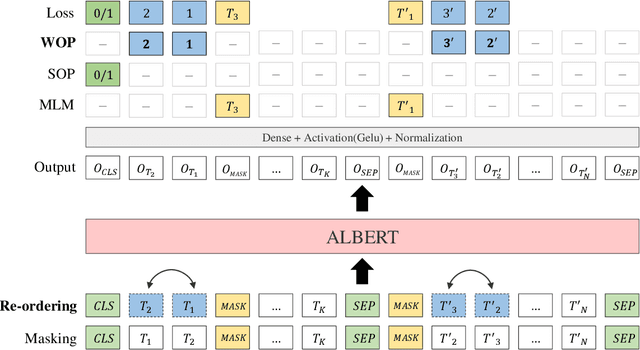
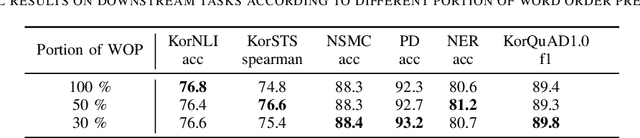

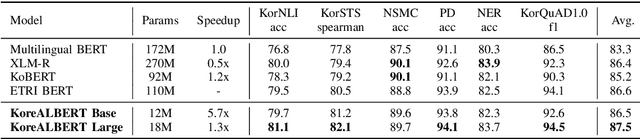
A Lite BERT (ALBERT) has been introduced to scale up deep bidirectional representation learning for natural languages. Due to the lack of pretrained ALBERT models for Korean language, the best available practice is the multilingual model or resorting back to the any other BERT-based model. In this paper, we develop and pretrain KoreALBERT, a monolingual ALBERT model specifically for Korean language understanding. We introduce a new training objective, namely Word Order Prediction (WOP), and use alongside the existing MLM and SOP criteria to the same architecture and model parameters. Despite having significantly fewer model parameters (thus, quicker to train), our pretrained KoreALBERT outperforms its BERT counterpart on 6 different NLU tasks. Consistent with the empirical results in English by Lan et al., KoreALBERT seems to improve downstream task performance involving multi-sentence encoding for Korean language. The pretrained KoreALBERT is publicly available to encourage research and application development for Korean NLP.
Clear the Fog: Combat Value Assessment in Incomplete Information Games with Convolutional Encoder-Decoders
Nov 30, 2018StarCraft, one of the most popular real-time strategy games, is a compelling environment for artificial intelligence research for both micro-level unit control and macro-level strategic decision making. In this study, we address an eminent problem concerning macro-level decision making, known as the 'fog-of-war', which rises naturally from the fact that information regarding the opponent's state is always provided in the incomplete form. For intelligent agents to play like human players, it is obvious that making accurate predictions of the opponent's status under incomplete information will increase its chance of winning. To reflect this fact, we propose a convolutional encoder-decoder architecture that predicts potential counts and locations of the opponent's units based on only partially visible and noisy information. To evaluate the performance of our proposed method, we train an additional classifier on the encoder-decoder output to predict the game outcome (win or lose). Finally, we designed an agent incorporating the proposed method and conducted simulation games against rule-based agents to demonstrate both effectiveness and practicality. All experiments were conducted on actual game replay data acquired from professional players.