 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubric-Specific Approach to Automated Essay Scoring with Augmentation Training
Sep 06, 2023Neural based approaches to automatic evaluation of subjective responses have shown superior performance and efficiency compared to traditional rule-based and feature engineering oriented solutions. However, it remains unclear whether the suggested neural solutions are sufficient replacements of human raters as we find recent works do not properly account for rubric items that are essential for automated essay scoring during model training and validation. In this paper, we propose a series of data augmentation operations that train and test an automated scoring model to learn features and functions overlooked by previous works while still achieving state-of-the-art performance in the Automated Student Assessment Prize dataset.
KoreALBERT: Pretraining a Lite BERT Model for Korean Language Understanding
Jan 27, 2021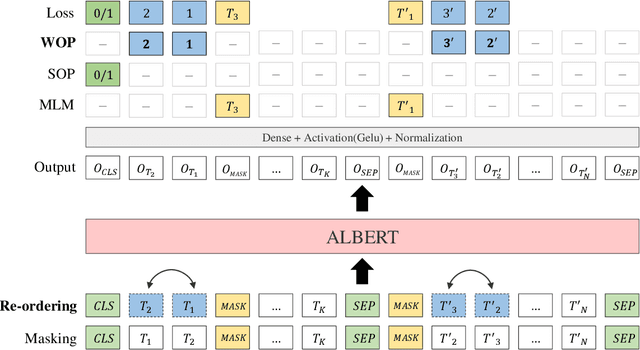
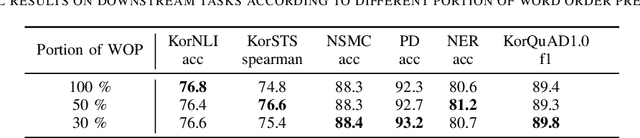

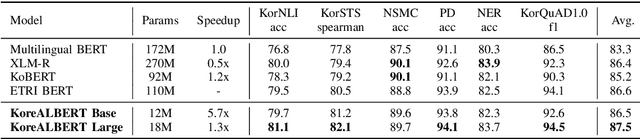
A Lite BERT (ALBERT) has been introduced to scale up deep bidirectional representation learning for natural languages. Due to the lack of pretrained ALBERT models for Korean language, the best available practice is the multilingual model or resorting back to the any other BERT-based model. In this paper, we develop and pretrain KoreALBERT, a monolingual ALBERT model specifically for Korean language understanding. We introduce a new training objective, namely Word Order Prediction (WOP), and use alongside the existing MLM and SOP criteria to the same architecture and model parameters. Despite having significantly fewer model parameters (thus, quicker to train), our pretrained KoreALBERT outperforms its BERT counterpart on 6 different NLU tasks. Consistent with the empirical results in English by Lan et al., KoreALBERT seems to improve downstream task performance involving multi-sentence encoding for Korean language. The pretrained KoreALBERT is publicly available to encourage research and application development for Korean NLP.