 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding LoRA as Knowledge Memory: An Empirical Analysis
Mar 01, 2026Continuous knowledge updating for pre-trained large language models (LLMs) is increasingly necessary yet remains challenging. Although inference-time methods like In-Context Learning (ICL) and Retrieval-Augmented Generation (RAG) are popular, they face constraints in context budgets, costs, and retrieval fragmentation. Departing from these context-dependent paradigms, this work investigates a parametric approach using Low-Rank Adaptation (LoRA) as a modular knowledge memory. Although few recent works examine this concept, the fundamental mechanics governing its capacity and composability remain largely unexplored. We bridge this gap through the first systematic empirical study mapping the design space of LoRA-based memory, ranging from characterizing storage capacity and optimizing internalization to scaling multi-module systems and evaluating long-context reasoning. Rather than proposing a single architecture, we provide practical guidance on the operational boundaries of LoRA memory. Overall, our findings position LoRA as the complementary axis of memory alongside RAG and ICL, offering distinct advantages.
Line Graph Vietoris-Rips Persistence Diagram for Topological Graph Representation Learning
Dec 23, 2024



While message passing graph neural networks result in informative node embeddings, they may suffer from describing the topological properties of graphs. To this end, node filtration has been widely used as an attempt to obtain the topological information of a graph using persistence diagrams. However, these attempts have faced the problem of losing node embedding information, which in turn prevents them from providing a more expressive graph representation. To tackle this issue, we shift our focus to edge filtration and introduce a novel edge filtration-based persistence diagram, named Topological Edge Diagram (TED), which is mathematically proven to preserve node embedding information as well as contain additional topological information. To implement TED, we propose a neural network based algorithm, named Line Graph Vietoris-Rips (LGVR) Persistence Diagram, that extracts edge information by transforming a graph into its line graph. Through LGVR, we propose two model frameworks that can be applied to any message passing GNNs, and prove that they are strictly more powerful than Weisfeiler-Lehman type colorings. Finally we empirically validate superior performance of our models on several graph classification and regression benchmarks.
CAAP: Context-Aware Action Planning Prompting to Solve Computer Tasks with Front-End UI Only
Jun 11, 2024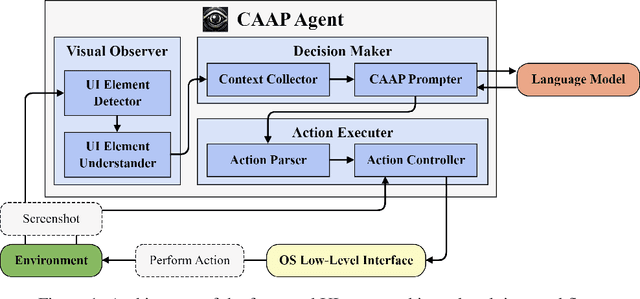



Software robots have long been deployed in Robotic Process Automation (RPA) to automate mundane and repetitive computer tasks. The advent of Large Language Models (LLMs) with advanced reasoning capabilities has set the stage for these agents to now undertake more complex and even previously unseen tasks. However, the LLM-based automation techniques in recent literature frequently rely on HTML source codes for input, limiting their application to web environments. Moreover, the information contained in HTML codes is often inaccurate or incomplete, making the agent less reliable for practical applications. We propose an LLM-based agent that functions solely on the basis of screenshots for recognizing environments, while leveraging in-context learning to eliminate the need for collecting large datasets of human demonstration. Our strategy, named Context-Aware Action Planning (CAAP) prompting encourages the agent to meticulously review the context in various angles. Through our proposed methodology, we achieve a success rate of 94.4% on 67~types of MiniWoB++ problems, utilizing only 1.48~demonstrations per problem type. Our method offers the potential for broader applications, especially for tasks that require inter-application coordination on computers or smartphones, showcasing a significant advancement in the field of automation agents. Codes and models are accessible at https://github.com/caap-agent/caap-agent.
ContraCluster: Learning to Classify without Labels by Contrastive Self-Supervision and Prototype-Based Semi-Supervision
Apr 19, 2023
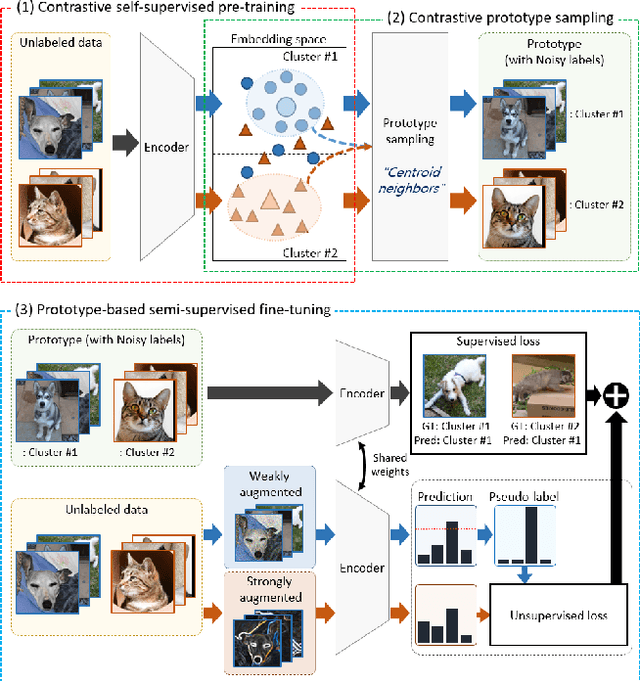
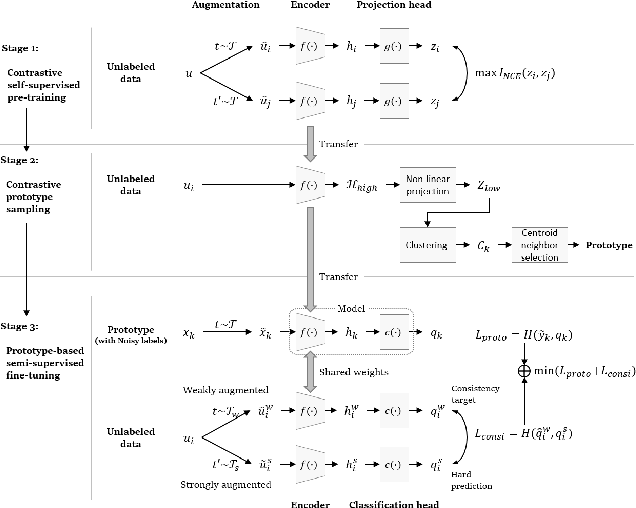
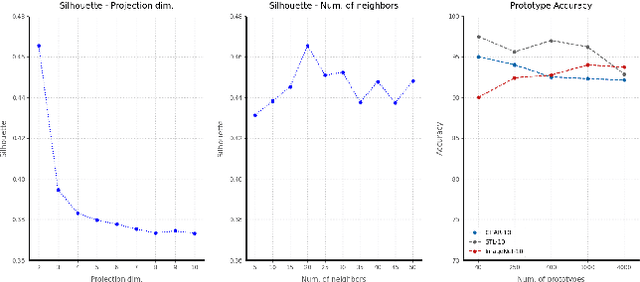
The recent advances in representation learning inspire us to take on the challenging problem of unsupervised image classification tasks in a principled way. We propose ContraCluster, an unsupervised image classification method that combines clustering with the power of contrastive self-supervised learning. ContraCluster consists of three stages: (1) contrastive self-supervised pre-training (CPT), (2) contrastive prototype sampling (CPS), and (3) prototype-based semi-supervised fine-tuning (PB-SFT). CPS can select highly accurate, categorically prototypical images in an embedding space learned by contrastive learning. We use sampled prototypes as noisy labeled data to perform semi-supervised fine-tuning (PB-SFT), leveraging small prototypes and large unlabeled data to further enhance the accuracy. We demonstrate empirically that ContraCluster achieves new state-of-the-art results for standard benchmark datasets including CIFAR-10, STL-10, and ImageNet-10. For example, ContraCluster achieves about 90.8% accuracy for CIFAR-10, which outperforms DAC (52.2%), IIC (61.7%), and SCAN (87.6%) by a large margin. Without any labels, ContraCluster can achieve a 90.8% accuracy that is comparable to 95.8% by the best supervised counterpart.
* Accepted at ICPR 2022
Shuffle & Divide: Contrastive Learning for Long Text
Apr 19, 2023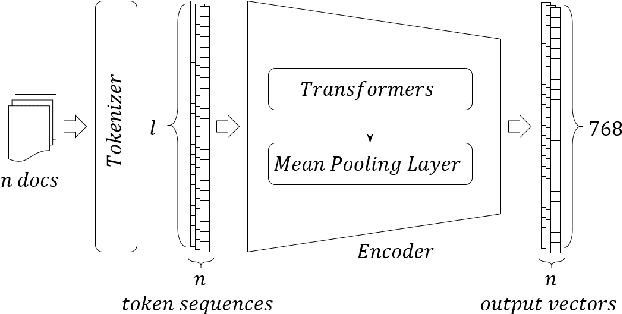

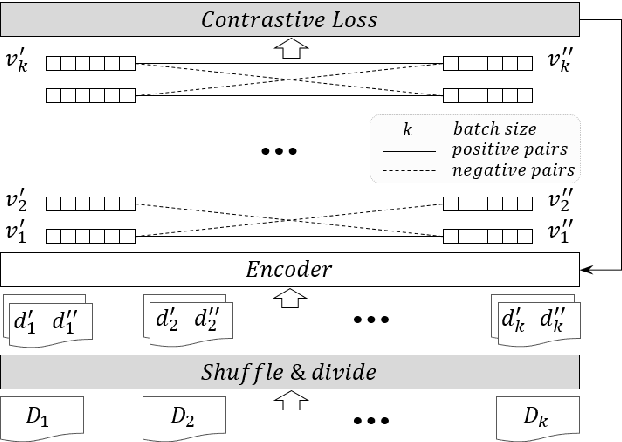
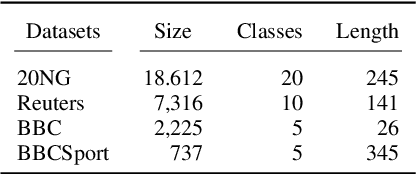
We propose a self-supervised learning method for long text documents based on contrastive learning. A key to our method is Shuffle and Divide (SaD), a simple text augmentation algorithm that sets up a pretext task required for contrastive updates to BERT-based document embedding. SaD splits a document into two sub-documents containing randomly shuffled words in the entire documents. The sub-documents are considered positive examples, leaving all other documents in the corpus as negatives. After SaD, we repeat the contrastive update and clustering phases until convergence. It is naturally a time-consuming, cumbersome task to label text documents, and our method can help alleviate human efforts, which are most expensive resources in AI. We have empirically evaluated our method by performing unsupervised text classification on the 20 Newsgroups, Reuters-21578, BBC, and BBCSport datasets. In particular, our method pushes the current state-of-the-art, SS-SB-MT, on 20 Newsgroups by 20.94% in accuracy. We also achieve the state-of-the-art performance on Reuters-21578 and exceptionally-high accuracy performances (over 95%) for unsupervised classification on the BBC and BBCSport datasets.
* Accepted at ICPR 2022
Simulation-guided Beam Search for Neural Combinatorial Optimization
Jul 13, 2022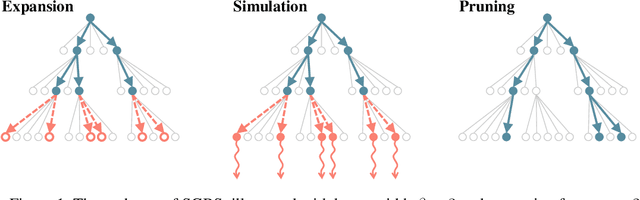
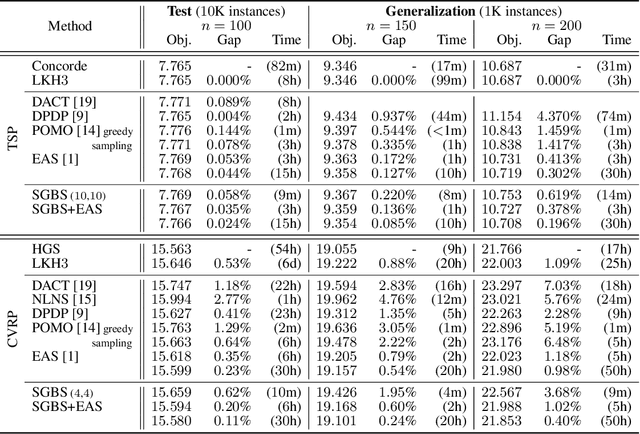
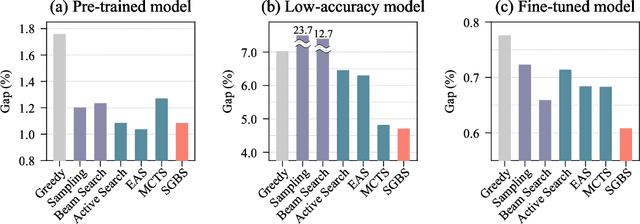
Neural approaches for combinatorial optimization (CO) equip a learning mechanism to discover powerful heuristics for solving complex real-world problems. While neural approaches capable of high-quality solutions in a single shot are emerging, state-of-the-art approaches are often unable to take full advantage of the solving time available to them. In contrast, hand-crafted heuristics perform highly effective search well and exploit the computation time given to them, but contain heuristics that are difficult to adapt to a dataset being solved. With the goal of providing a powerful search procedure to neural CO approaches, we propose simulation-guided beam search (SGBS), which examines candidate solutions within a fixed-width tree search that both a neural net-learned policy and a simulation (rollout) identify as promising. We further hybridize SGBS with efficient active search (EAS), where SGBS enhances the quality of solutions backpropagated in EAS, and EAS improves the quality of the policy used in SGBS. We evaluate our methods on well-known CO benchmarks and show that SGBS significantly improves the quality of the solutions found under reasonable runtime assumptions.
BiHPF: Bilateral High-Pass Filters for Robust Deepfake Detection
Aug 16, 2021

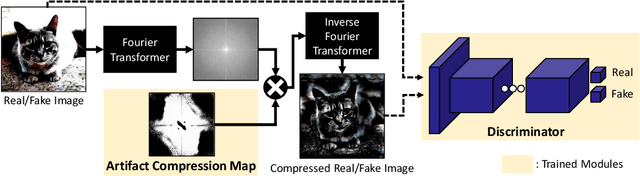
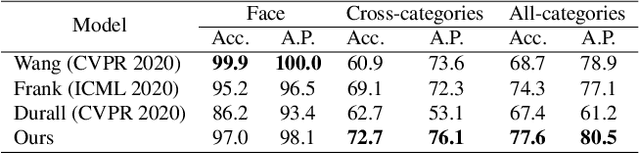
The advancement in numerous generative models has a two-fold effect: a simple and easy generation of realistic synthesized images, but also an increased risk of malicious abuse of those images. Thus, it is important to develop a generalized detector for synthesized images of any GAN model or object category, including those unseen during the training phase. However, the conventional methods heavily depend on the training settings, which cause a dramatic decline in performance when tested with unknown domains. To resolve the issue and obtain a generalized detection ability, we propose Bilateral High-Pass Filters (BiHPF), which amplify the effect of the frequency-level artifacts that are known to be found in the synthesized images of generative models. Numerous experimental results validate that our method outperforms other state-of-the-art methods, even when tested with unseen domains.
ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models
Aug 06, 2021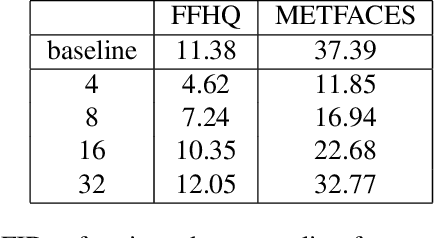
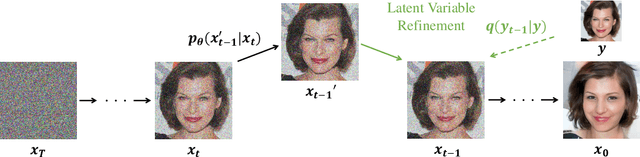

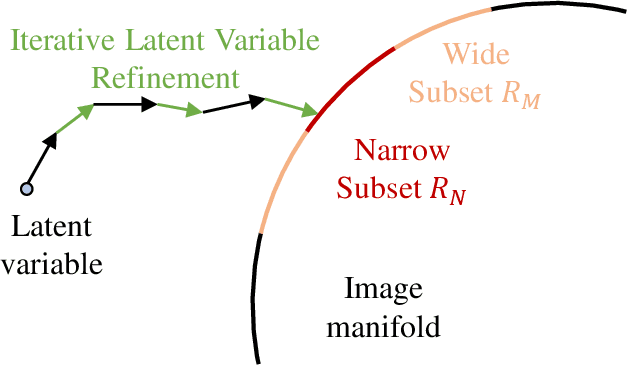
Denoising diffusion probabilistic models (DDPM) have shown remarkable performance in unconditional image generation. However, due to the stochasticity of the generative process in DDPM, it is challenging to generate images with the desired semantics. In this work, we propose Iterative Latent Variable Refinement (ILVR), a method to guide the generative process in DDPM to generate high-quality images based on a given reference image. Here, the refinement of the generative process in DDPM enables a single DDPM to sample images from various sets directed by the reference image. The proposed ILVR method generates high-quality images while controlling the generation. The controllability of our method allows adaptation of a single DDPM without any additional learning in various image generation tasks, such as generation from various downsampling factors, multi-domain image translation, paint-to-image, and editing with scribbles.
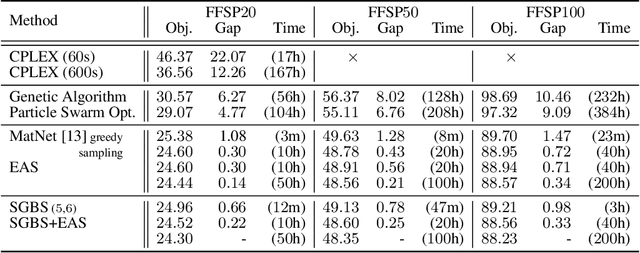
Matrix Encoding Networks for Neural Combinatorial Optimization
Jun 21, 2021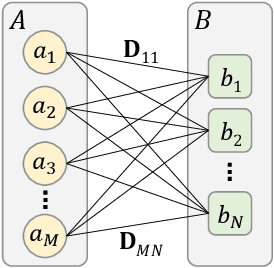
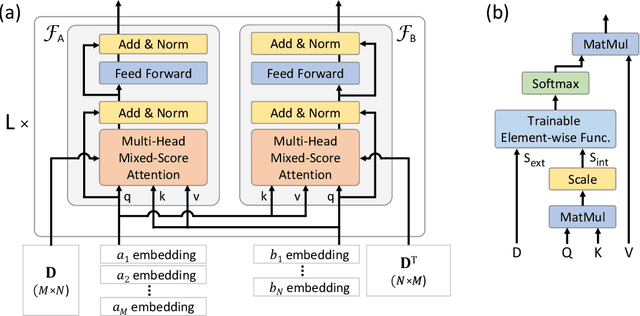
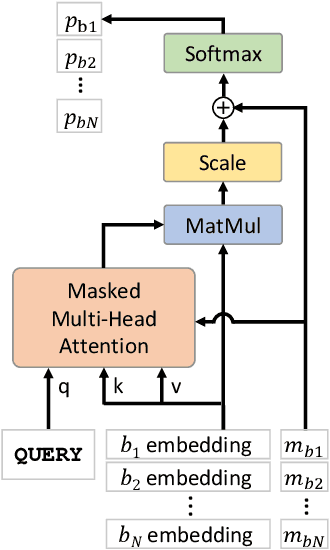
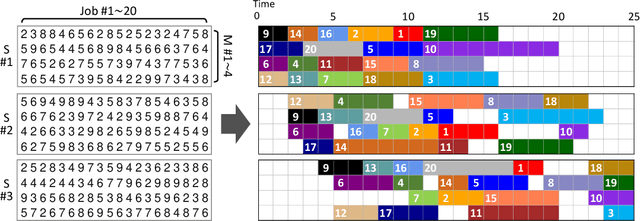
Machine Learning (ML) can help solve combinatorial optimization (CO) problems better. A popular approach is to use a neural net to compute on the parameters of a given CO problem and extract useful information that guides the search for good solutions. Many CO problems of practical importance can be specified in a matrix form of parameters quantifying the relationship between two groups of items. There is currently no neural net model, however, that takes in such matrix-style relationship data as an input. Consequently, these types of CO problems have been out of reach for ML engineers. In this paper, we introduce Matrix Encoding Network (MatNet) and show how conveniently it takes in and processes parameters of such complex CO problems. Using an end-to-end model based on MatNet, we solve asymmetric traveling salesman (ATSP) and flexible flow shop (FFSP) problems as the earliest neural approach. In particular, for a class of FFSP we have tested MatNet on, we demonstrate a far superior empirical performance to any methods (neural or not) known to date.
KoreALBERT: Pretraining a Lite BERT Model for Korean Language Understanding
Jan 27, 2021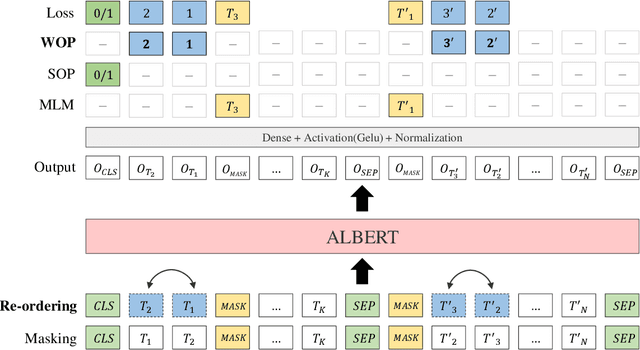
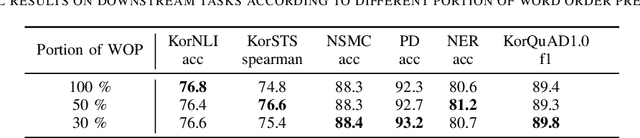

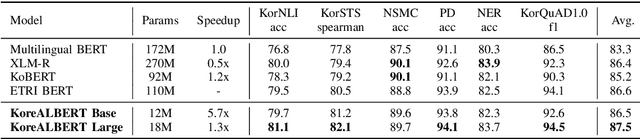
A Lite BERT (ALBERT) has been introduced to scale up deep bidirectional representation learning for natural languages. Due to the lack of pretrained ALBERT models for Korean language, the best available practice is the multilingual model or resorting back to the any other BERT-based model. In this paper, we develop and pretrain KoreALBERT, a monolingual ALBERT model specifically for Korean language understanding. We introduce a new training objective, namely Word Order Prediction (WOP), and use alongside the existing MLM and SOP criteria to the same architecture and model parameters. Despite having significantly fewer model parameters (thus, quicker to train), our pretrained KoreALBERT outperforms its BERT counterpart on 6 different NLU tasks. Consistent with the empirical results in English by Lan et al., KoreALBERT seems to improve downstream task performance involving multi-sentence encoding for Korean language. The pretrained KoreALBERT is publicly available to encourage research and application development for Korean NLP.