 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVRPAgent: LLM-Driven Discovery of Heuristic Operators for Vehicle Routing Problems
Oct 08, 2025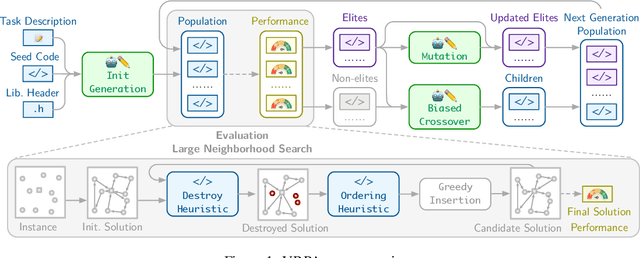
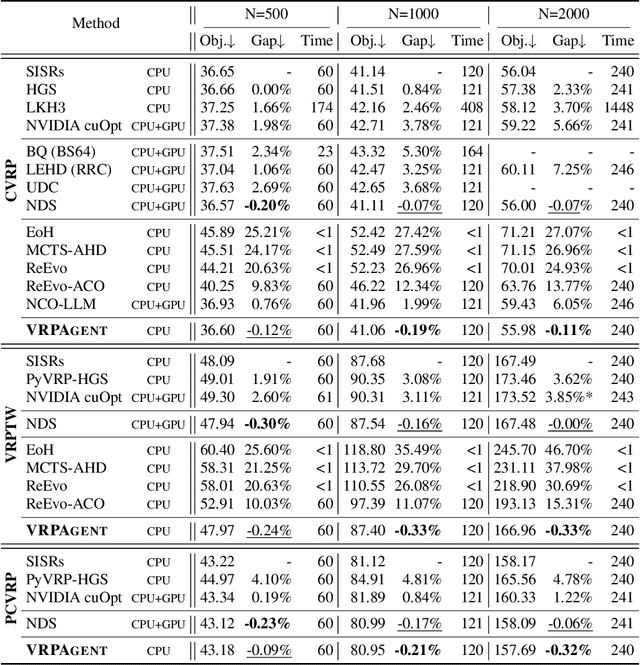
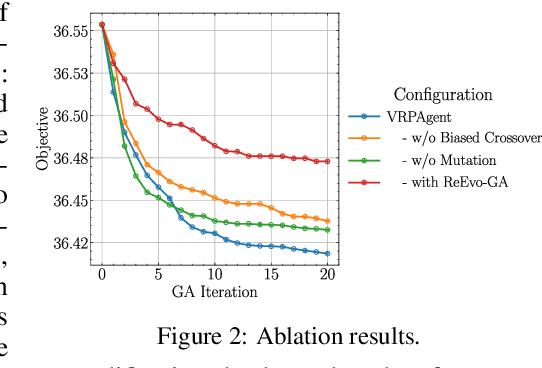
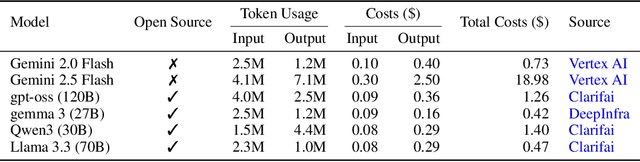
Designing high-performing heuristics for vehicle routing problems (VRPs) is a complex task that requires both intuition and deep domain knowledge. Large language model (LLM)-based code generation has recently shown promise across many domains, but it still falls short of producing heuristics that rival those crafted by human experts. In this paper, we propose VRPAgent, a framework that integrates LLM-generated components into a metaheuristic and refines them through a novel genetic search. By using the LLM to generate problem-specific operators, embedded within a generic metaheuristic framework, VRPAgent keeps tasks manageable, guarantees correctness, and still enables the discovery of novel and powerful strategies. Across multiple problems, including the capacitated VRP, the VRP with time windows, and the prize-collecting VRP, our method discovers heuristic operators that outperform handcrafted methods and recent learning-based approaches while requiring only a single CPU core. To our knowledge, \VRPAgent is the first LLM-based paradigm to advance the state-of-the-art in VRPs, highlighting a promising future for automated heuristics discovery.
Neural Deconstruction Search for Vehicle Routing Problems
Jan 07, 2025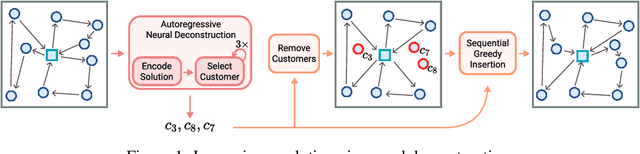

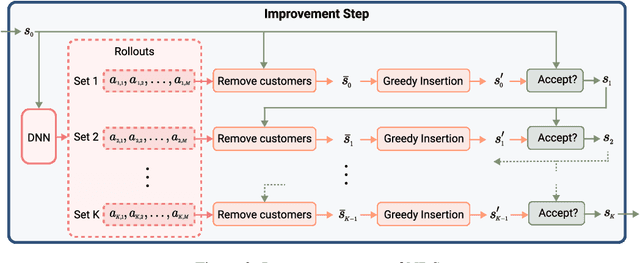

Autoregressive construction approaches generate solutions to vehicle routing problems in a step-by-step fashion, leading to high-quality solutions that are nearing the performance achieved by handcrafted, operations research techniques. In this work, we challenge the conventional paradigm of sequential solution construction and introduce an iterative search framework where solutions are instead deconstructed by a neural policy. Throughout the search, the neural policy collaborates with a simple greedy insertion algorithm to rebuild the deconstructed solutions. Our approach surpasses the performance of state-of-the-art operations research methods across three challenging vehicle routing problems of various problem sizes.
RouteFinder: Towards Foundation Models for Vehicle Routing Problems
Jun 21, 2024



Vehicle Routing Problems (VRPs) are optimization problems with significant real-world implications in logistics, transportation, and supply chain management. Despite the recent progress made in learning to solve individual VRP variants, there is a lack of a unified approach that can effectively tackle a wide range of tasks, which is crucial for real-world impact. This paper introduces RouteFinder, a framework for developing foundation models for VRPs. Our key idea is that a foundation model for VRPs should be able to model variants by treating each variant as a subset of a larger VRP problem, equipped with different attributes. We introduce a parallelized environment that can handle any combination of attributes at the same time in a batched manner, and an efficient sampling procedure to train on a mix of problems at each optimization step that can greatly improve convergence robustness. We also introduce novel Global Feature Embeddings that project instance-wise attributes efficiently onto the latent space and help the model understand different VRP variants. Finally, we introduce Efficient Adapter Layers, a simple yet effective technique to finetune pre-trained RouteFinder models to solve novel variants with previously unseen attributes outside of the original feature space. We validate our approach through extensive experiments on 24 VRP variants, demonstrating competitive results over recent multi-task learning models. We make our code openly available at https://github.com/ai4co/routefinder.
PolyNet: Learning Diverse Solution Strategies for Neural Combinatorial Optimization
Feb 21, 2024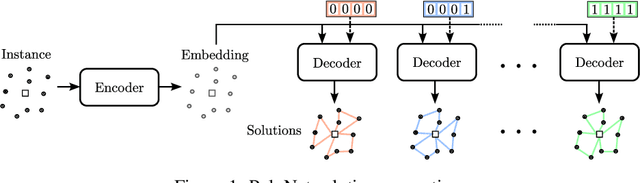


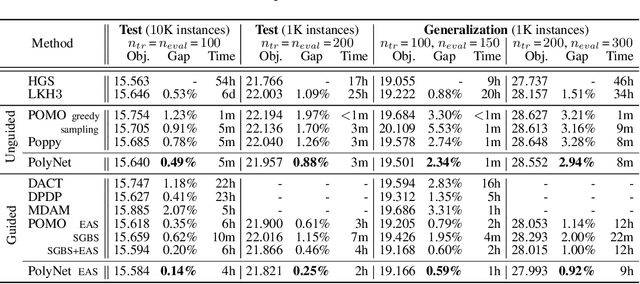
Reinforcement learning-based methods for constructing solutions to combinatorial optimization problems are rapidly approaching the performance of human-designed algorithms. To further narrow the gap, learning-based approaches must efficiently explore the solution space during the search process. Recent approaches artificially increase exploration by enforcing diverse solution generation through handcrafted rules, however, these rules can impair solution quality and are difficult to design for more complex problems. In this paper, we introduce PolyNet, an approach for improving exploration of the solution space by learning complementary solution strategies. In contrast to other works, PolyNet uses only a single-decoder and a training schema that does not enforce diverse solution generation through handcrafted rules. We evaluate PolyNet on four combinatorial optimization problems and observe that the implicit diversity mechanism allows PolyNet to find better solutions than approaches the explicitly enforce diverse solution generation.
Simulation-guided Beam Search for Neural Combinatorial Optimization
Jul 13, 2022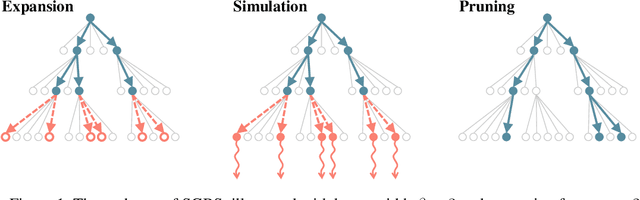
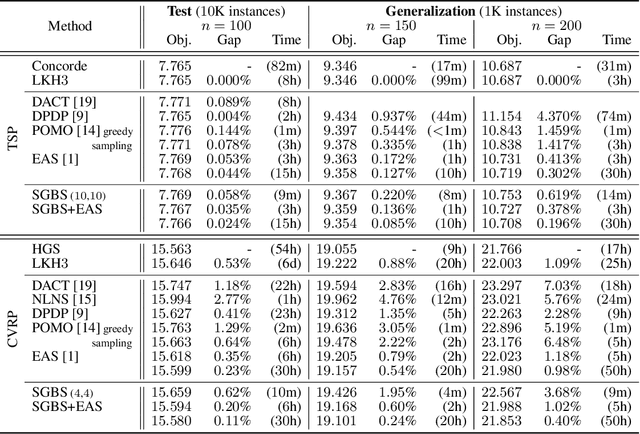
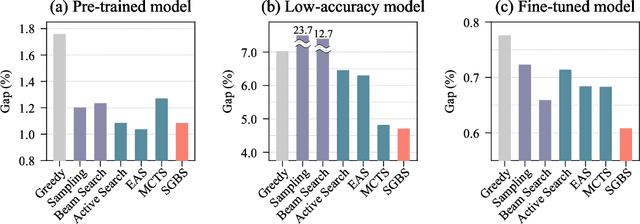
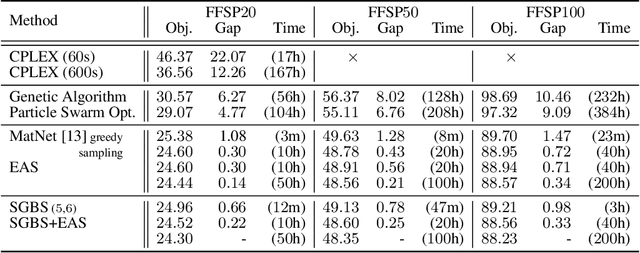
Neural approaches for combinatorial optimization (CO) equip a learning mechanism to discover powerful heuristics for solving complex real-world problems. While neural approaches capable of high-quality solutions in a single shot are emerging, state-of-the-art approaches are often unable to take full advantage of the solving time available to them. In contrast, hand-crafted heuristics perform highly effective search well and exploit the computation time given to them, but contain heuristics that are difficult to adapt to a dataset being solved. With the goal of providing a powerful search procedure to neural CO approaches, we propose simulation-guided beam search (SGBS), which examines candidate solutions within a fixed-width tree search that both a neural net-learned policy and a simulation (rollout) identify as promising. We further hybridize SGBS with efficient active search (EAS), where SGBS enhances the quality of solutions backpropagated in EAS, and EAS improves the quality of the policy used in SGBS. We evaluate our methods on well-known CO benchmarks and show that SGBS significantly improves the quality of the solutions found under reasonable runtime assumptions.
The First AI4TSP Competition: Learning to Solve Stochastic Routing Problems
Jan 25, 2022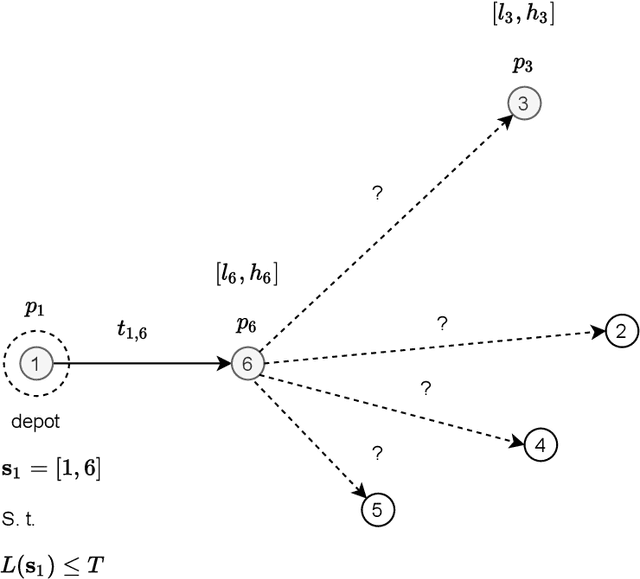
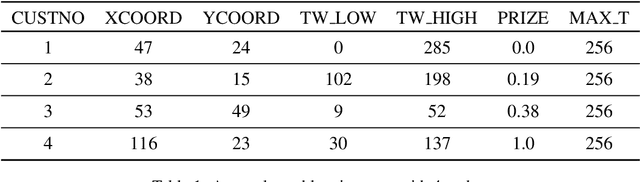

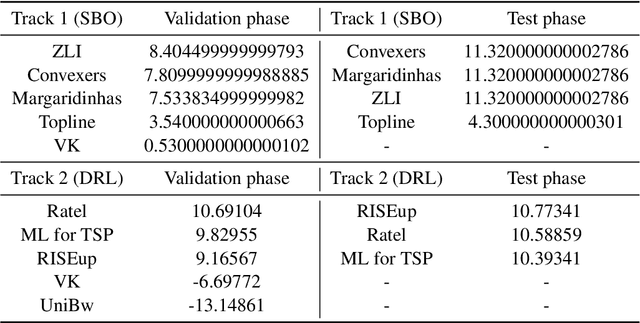
This paper reports on the first international competition on AI for the traveling salesman problem (TSP) at the International Joint Conference on Artificial Intelligence 2021 (IJCAI-21). The TSP is one of the classical combinatorial optimization problems, with many variants inspired by real-world applications. This first competition asked the participants to develop algorithms to solve a time-dependent orienteering problem with stochastic weights and time windows (TD-OPSWTW). It focused on two types of learning approaches: surrogate-based optimization and deep reinforcement learning. In this paper, we describe the problem, the setup of the competition, the winning methods, and give an overview of the results. The winning methods described in this work have advanced the state-of-the-art in using AI for stochastic routing problems. Overall, by organizing this competition we have introduced routing problems as an interesting problem setting for AI researchers. The simulator of the problem has been made open-source and can be used by other researchers as a benchmark for new AI methods.
Efficient Active Search for Combinatorial Optimization Problems
Jun 09, 2021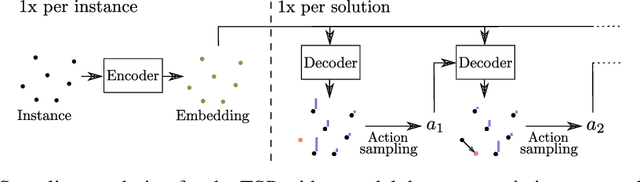
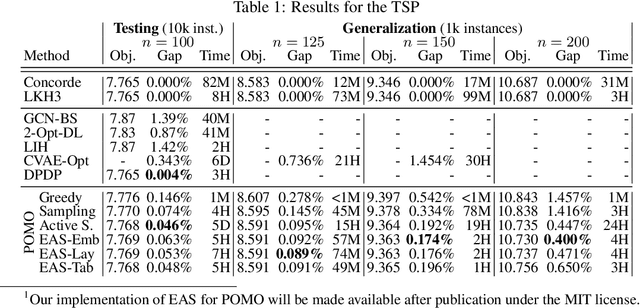
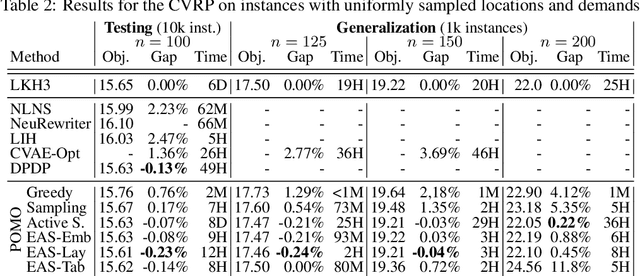
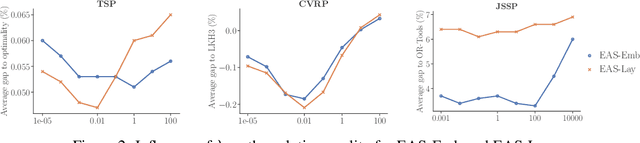
Recently numerous machine learning based methods for combinatorial optimization problems have been proposed that learn to construct solutions in a sequential decision process via reinforcement learning. While these methods can be easily combined with search strategies like sampling and beam search, it is not straightforward to integrate them into a high-level search procedure offering strong search guidance. Bello et al. (2016) propose active search, which adjusts the weights of a (trained) model with respect to a single instance at test time using reinforcement learning. While active search is simple to implement, it is not competitive with state-of-the-art methods because adjusting all model weights for each test instance is very time and memory intensive. Instead of updating all model weights, we propose and evaluate three efficient active search strategies that only update a subset of parameters during the search. The proposed methods offer a simple way to significantly improve the search performance of a given model and outperform state-of-the-art machine learning based methods on combinatorial problems, even surpassing the well-known heuristic solver LKH3 on the capacitated vehicle routing problem. Finally, we show that (efficient) active search enables learned models to effectively solve instances that are much larger than those seen during training.
Neural Large Neighborhood Search for the Capacitated Vehicle Routing Problem
Nov 21, 2019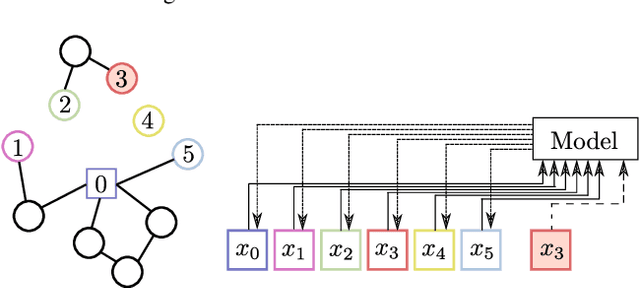
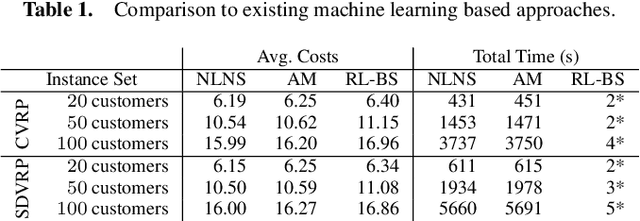
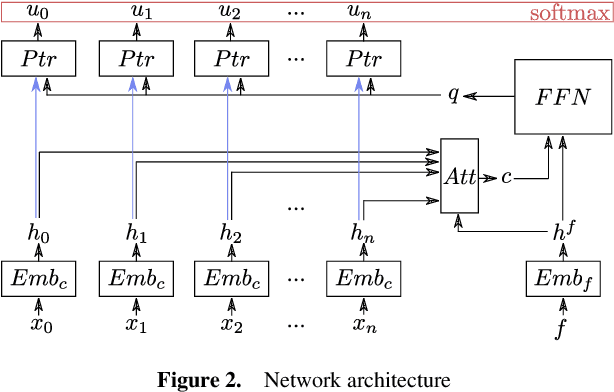
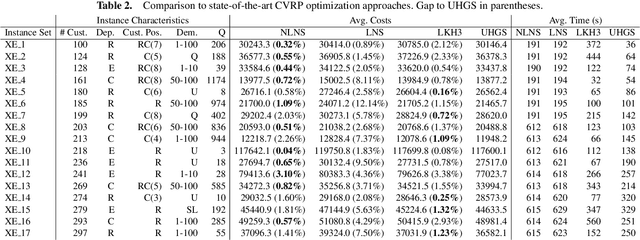
Learning how to automatically solve optimization problems has the potential to provide the next big leap in optimization technology. The performance of automatically learned heuristics on routing problems has been steadily improving in recent years, but approaches based purely on machine learning are still outperformed by state-of-the-art optimization methods. To close this performance gap, we propose a novel large neighborhood search (LNS) framework for vehicle routing that integrates learned heuristics for generating new solutions. The learning mechanism is based on a deep neural network with an attention mechanism and has been especially designed to be integrated into an LNS search setting. We evaluate our approach on the capacitated vehicle routing problem (CVRP) and the split delivery vehicle routing problem (SDVRP). On CVRP instances with up to 297 customers our approach significantly outperforms an LNS that uses only handcrafted heuristics and a well-known heuristic from the literature. Furthermore, we show for the CVRP and the SDVRP that our approach surpasses the performance of existing machine learning approaches and comes close to the performance of state-of-the-art optimization approaches.
Deep Learning Assisted Heuristic Tree Search for the Container Pre-marshalling Problem
Sep 28, 2017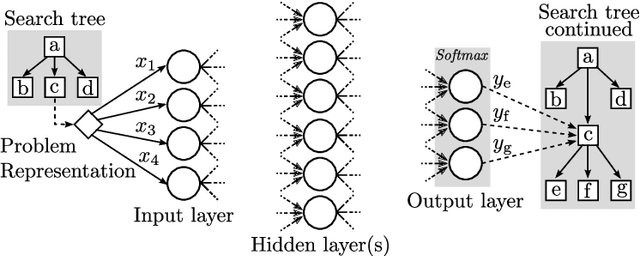
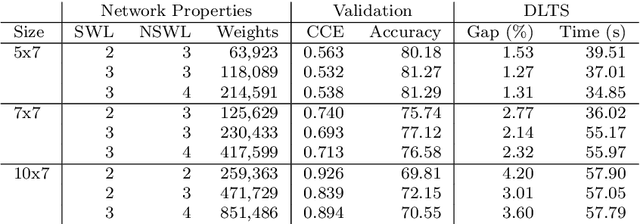
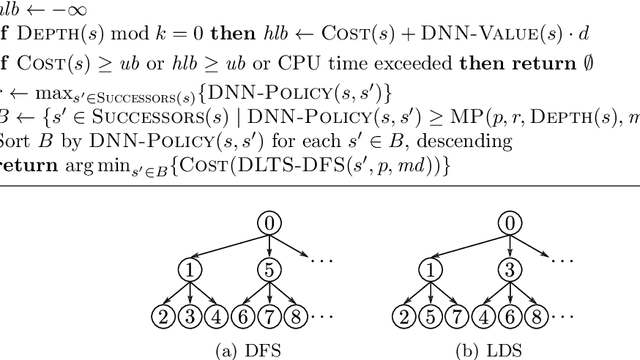
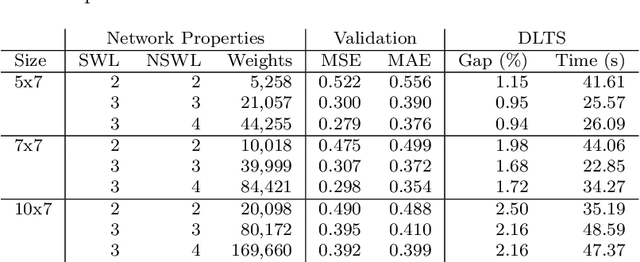
One of the key challenges for operations researchers solving real-world problems is designing and implementing high-quality heuristics to guide their search procedures. In the past, machine learning techniques have failed to play a major role in operations research approaches, especially in terms of guiding branching and pruning decisions. We integrate deep neural networks into a heuristic tree search procedure to decide which branch to choose next and to estimate a bound for pruning the search tree of an optimization problem. We call our approach Deep Learning assisted heuristic Tree Search (DLTS) and apply it to a well-known problem from the container terminals literature, the container pre-marshalling problem (CPMP). Our approach is able to learn heuristics customized to the CPMP solely through analyzing the solutions to CPMP instances, and applies this knowledge within a heuristic tree search to produce the highest quality heuristic solutions to the CPMP to date.