 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe First AI4TSP Competition: Learning to Solve Stochastic Routing Problems
Jan 25, 2022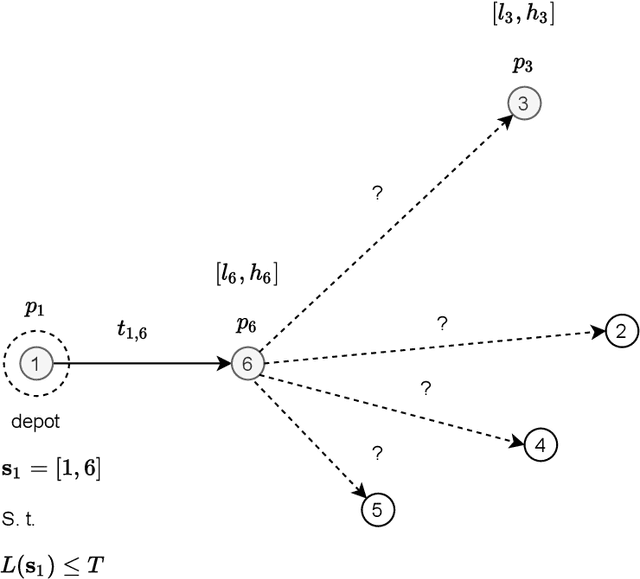
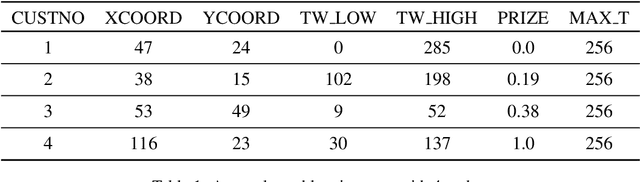

This paper reports on the first international competition on AI for the traveling salesman problem (TSP) at the International Joint Conference on Artificial Intelligence 2021 (IJCAI-21). The TSP is one of the classical combinatorial optimization problems, with many variants inspired by real-world applications. This first competition asked the participants to develop algorithms to solve a time-dependent orienteering problem with stochastic weights and time windows (TD-OPSWTW). It focused on two types of learning approaches: surrogate-based optimization and deep reinforcement learning. In this paper, we describe the problem, the setup of the competition, the winning methods, and give an overview of the results. The winning methods described in this work have advanced the state-of-the-art in using AI for stochastic routing problems. Overall, by organizing this competition we have introduced routing problems as an interesting problem setting for AI researchers. The simulator of the problem has been made open-source and can be used by other researchers as a benchmark for new AI methods.
Policies for the Dynamic Traveling Maintainer Problem with Alerts
May 31, 2021
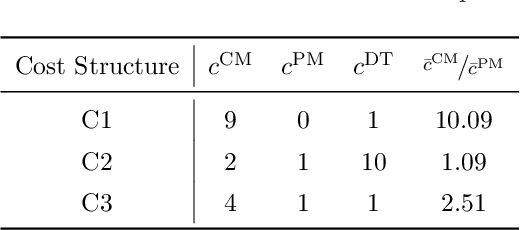
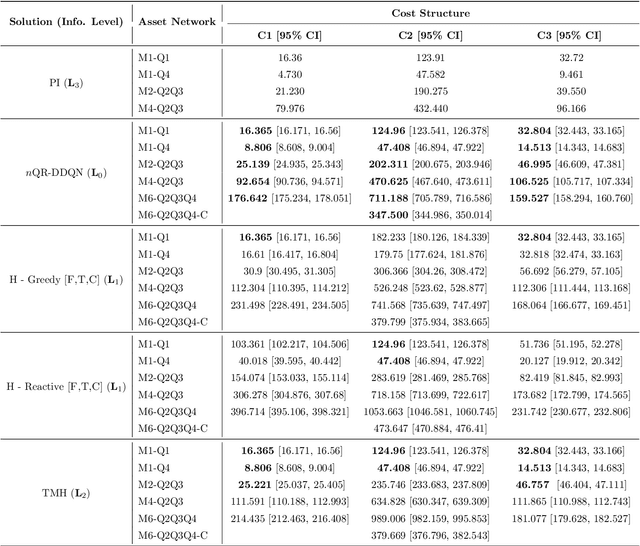
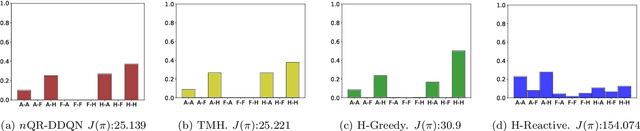
Companies require modern capital assets such as wind turbines, trains and hospital equipment to experience minimal downtime. Ideally, assets are maintained right before failure to ensure maximum availability at minimum maintenance costs. To this end, two challenges arise: failure times of assets are unknown a priori and assets can be part of a larger asset network. Nowadays, it is common for assets to be equipped with real-time monitoring that emits alerts, typically triggered by the first signs of degradation. Thus, it becomes crucial to plan maintenance considering information received via alerts, asset locations and maintenance costs. This problem is referred to as the Dynamic Traveling Maintainer Problem with Alerts (DTMPA). We propose a modeling framework for the DTMPA, where the alerts are early and imperfect indicators of failures. The objective is to minimize discounted maintenance costs accrued over an infinite time horizon. We propose three methods to solve this problem, leveraging different information levels from the alert signals. The proposed methods comprise various greedy heuristics that rank assets based on proximity, urgency and economic risk; a Traveling Maintainer Heuristic employing combinatorial optimization to optimize near-future costs; a Deep Reinforcement Learning (DRL) method trained to minimize the long-term costs using exclusively the history of alerts. In a simulated environment, all methods can approximate optimal policies with access to perfect condition information for small asset networks. For larger networks, where computing the optimal policy is intractable, the proposed methods yield competitive maintenance policies, with DRL consistently achieving the lowest costs.
Of Starships and Klingons: Bayesian Logic for the 23rd Century
Jul 04, 2012

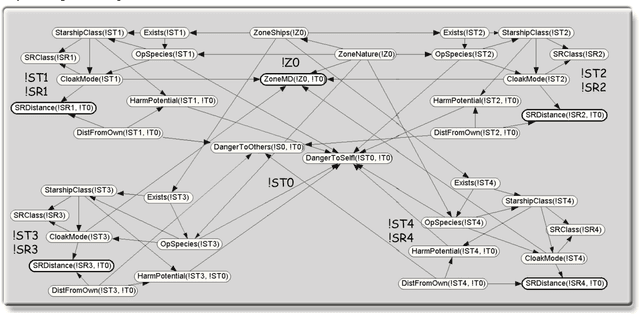
Intelligent systems in an open world must reason about many interacting entities related to each other in diverse ways and having uncertain features and relationships. Traditional probabilistic languages lack the expressive power to handle relational domains. Classical first-order logic is sufficiently expressive, but lacks a coherent plausible reasoning capability. Recent years have seen the emergence of a variety of approaches to integrating first-order logic, probability, and machine learning. This paper presents Multi-entity Bayesian networks (MEBN), a formal system that integrates First Order Logic (FOL) with Bayesian probability theory. MEBN extends ordinary Bayesian networks to allow representation of graphical models with repeated sub-structures, and can express a probability distribution over models of any consistent, finitely axiomatizable first-order theory. We present the logic using an example inspired by the Paramount Series StarTrek.