 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement learning to learn quantum states for Heisenberg scaling accuracy
Dec 03, 2024Learning quantum states is a crucial task for realizing the potential of quantum information technology. Recently, neural approaches have emerged as promising methods for learning quantum states. We propose a meta-learning model that employs reinforcement learning (RL) to optimize the process of learning quantum states. For learning quantum states, our scheme trains a Hardware efficient ansatz with a blackbox optimization algorithm, called evolution strategy (ES). To enhance the efficiency of ES, a RL agent dynamically adjusts the hyperparameters of ES. To facilitate the RL training, we introduce an action repetition strategy inspired by curriculum learning. The RL agent significantly improves the sample efficiency of learning random quantum states, and achieves infidelity scaling close to the Heisenberg limit. We showcase that the RL agent trained using 3-qubit states can be generalized to learning up to 5-qubit states. These results highlight the utility of RL-driven meta-learning to enhance the efficiency and generalizability of learning quantum states. Our approach can be applicable to improve quantum control, quantum optimization, and quantum machine learning.
Simulation-guided Beam Search for Neural Combinatorial Optimization
Jul 13, 2022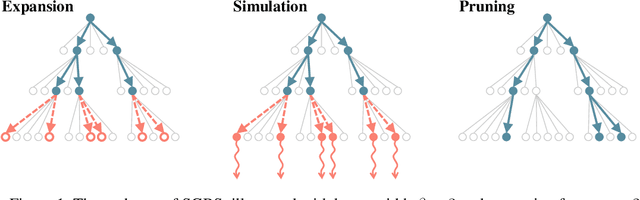
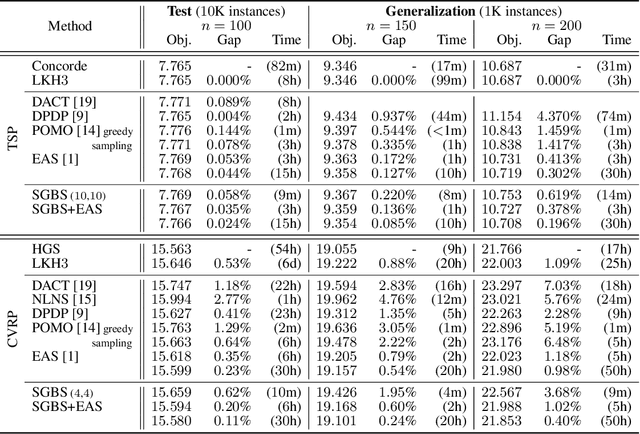
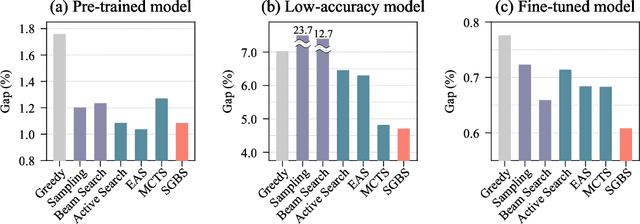
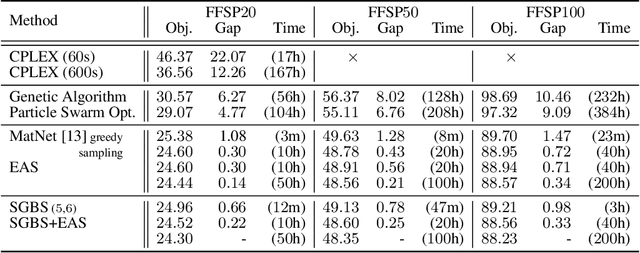
Neural approaches for combinatorial optimization (CO) equip a learning mechanism to discover powerful heuristics for solving complex real-world problems. While neural approaches capable of high-quality solutions in a single shot are emerging, state-of-the-art approaches are often unable to take full advantage of the solving time available to them. In contrast, hand-crafted heuristics perform highly effective search well and exploit the computation time given to them, but contain heuristics that are difficult to adapt to a dataset being solved. With the goal of providing a powerful search procedure to neural CO approaches, we propose simulation-guided beam search (SGBS), which examines candidate solutions within a fixed-width tree search that both a neural net-learned policy and a simulation (rollout) identify as promising. We further hybridize SGBS with efficient active search (EAS), where SGBS enhances the quality of solutions backpropagated in EAS, and EAS improves the quality of the policy used in SGBS. We evaluate our methods on well-known CO benchmarks and show that SGBS significantly improves the quality of the solutions found under reasonable runtime assumptions.