 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermarking for Factuality: Guiding Vision-Language Models Toward Truth via Tri-layer Contrastive Decoding
Oct 16, 2025Large Vision-Language Models (LVLMs) have recently shown promising results on various multimodal tasks, even achieving human-comparable performance in certain cases. Nevertheless, LVLMs remain prone to hallucinations -- they often rely heavily on a single modality or memorize training data without properly grounding their outputs. To address this, we propose a training-free, tri-layer contrastive decoding with watermarking, which proceeds in three steps: (1) select a mature layer and an amateur layer among the decoding layers, (2) identify a pivot layer using a watermark-related question to assess whether the layer is visually well-grounded, and (3) apply tri-layer contrastive decoding to generate the final output. Experiments on public benchmarks such as POPE, MME and AMBER demonstrate that our method achieves state-of-the-art performance in reducing hallucinations in LVLMs and generates more visually grounded responses.
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025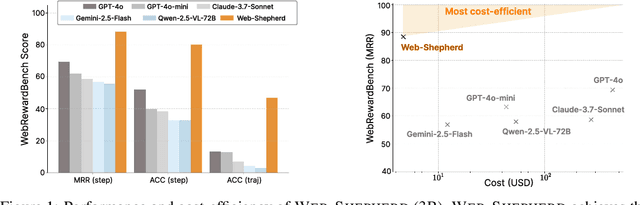


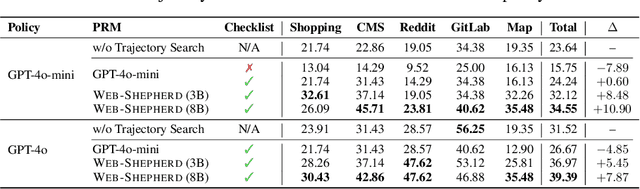
Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.
CAAP: Context-Aware Action Planning Prompting to Solve Computer Tasks with Front-End UI Only
Jun 11, 2024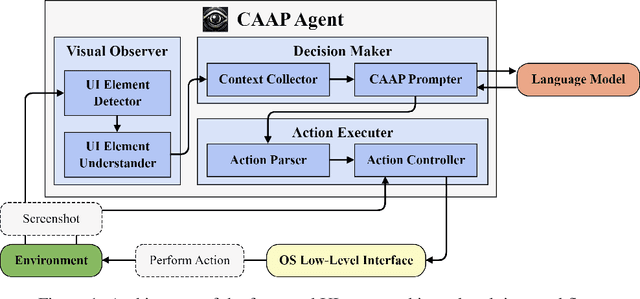



Software robots have long been deployed in Robotic Process Automation (RPA) to automate mundane and repetitive computer tasks. The advent of Large Language Models (LLMs) with advanced reasoning capabilities has set the stage for these agents to now undertake more complex and even previously unseen tasks. However, the LLM-based automation techniques in recent literature frequently rely on HTML source codes for input, limiting their application to web environments. Moreover, the information contained in HTML codes is often inaccurate or incomplete, making the agent less reliable for practical applications. We propose an LLM-based agent that functions solely on the basis of screenshots for recognizing environments, while leveraging in-context learning to eliminate the need for collecting large datasets of human demonstration. Our strategy, named Context-Aware Action Planning (CAAP) prompting encourages the agent to meticulously review the context in various angles. Through our proposed methodology, we achieve a success rate of 94.4% on 67~types of MiniWoB++ problems, utilizing only 1.48~demonstrations per problem type. Our method offers the potential for broader applications, especially for tasks that require inter-application coordination on computers or smartphones, showcasing a significant advancement in the field of automation agents. Codes and models are accessible at https://github.com/caap-agent/caap-agent.
Towards standardizing Korean Grammatical Error Correction: Datasets and Annotation
Oct 27, 2022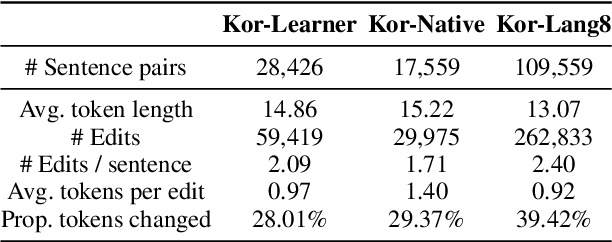
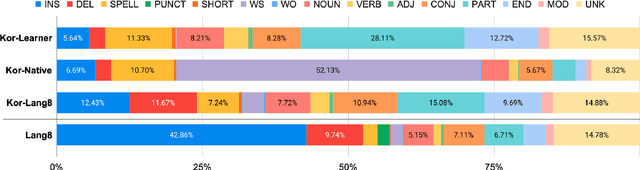

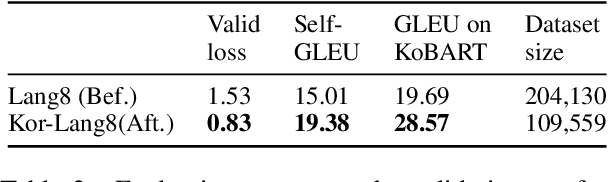
Research on Korean grammatical error correction (GEC) is limited compared to other major languages such as English and Chinese. We attribute this problematic circumstance to the lack of a carefully designed evaluation benchmark for Korean. Thus, in this work, we first collect three datasets from different sources (Kor-Lang8, Kor-Native, and Kor-Learner) to cover a wide range of error types and annotate them using our newly proposed tool called Korean Automatic Grammatical error Annotation System (KAGAS). KAGAS is a carefully designed edit alignment & classification tool that considers the nature of Korean on generating an alignment between a source sentence and a target sentence, and identifies error types on each aligned edit. We also present baseline models fine-tuned over our datasets. We show that the model trained with our datasets significantly outperforms the public statistical GEC system (Hanspell) on a wider range of error types, demonstrating the diversity and usefulness of the datasets.