 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards standardizing Korean Grammatical Error Correction: Datasets and Annotation
Oct 27, 2022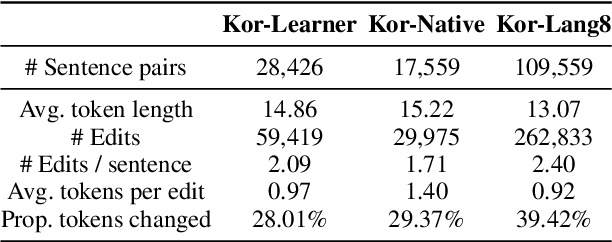
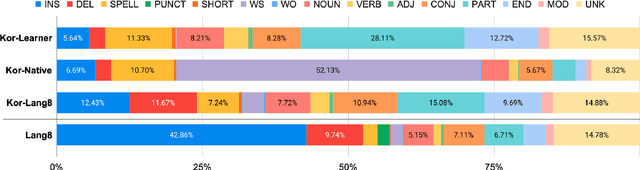

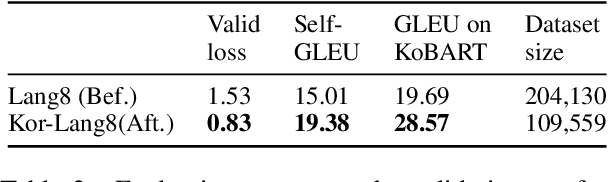
Research on Korean grammatical error correction (GEC) is limited compared to other major languages such as English and Chinese. We attribute this problematic circumstance to the lack of a carefully designed evaluation benchmark for Korean. Thus, in this work, we first collect three datasets from different sources (Kor-Lang8, Kor-Native, and Kor-Learner) to cover a wide range of error types and annotate them using our newly proposed tool called Korean Automatic Grammatical error Annotation System (KAGAS). KAGAS is a carefully designed edit alignment & classification tool that considers the nature of Korean on generating an alignment between a source sentence and a target sentence, and identifies error types on each aligned edit. We also present baseline models fine-tuned over our datasets. We show that the model trained with our datasets significantly outperforms the public statistical GEC system (Hanspell) on a wider range of error types, demonstrating the diversity and usefulness of the datasets.