 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Spatial Frequency: Pixel-wise Temporal Frequency-based Deepfake Video Detection
Jul 03, 2025We introduce a deepfake video detection approach that exploits pixel-wise temporal inconsistencies, which traditional spatial frequency-based detectors often overlook. Traditional detectors represent temporal information merely by stacking spatial frequency spectra across frames, resulting in the failure to detect temporal artifacts in the pixel plane. Our approach performs a 1D Fourier transform on the time axis for each pixel, extracting features highly sensitive to temporal inconsistencies, especially in areas prone to unnatural movements. To precisely locate regions containing the temporal artifacts, we introduce an attention proposal module trained in an end-to-end manner. Additionally, our joint transformer module effectively integrates pixel-wise temporal frequency features with spatio-temporal context features, expanding the range of detectable forgery artifacts. Our framework represents a significant advancement in deepfake video detection, providing robust performance across diverse and challenging detection scenarios.
Exploiting Style Latent Flows for Generalizing Deepfake Detection Video Detection
Mar 11, 2024



This paper presents a new approach for the detection of fake videos, based on the analysis of style latent vectors and their abnormal behavior in temporal changes in the generated videos. We discovered that the generated facial videos suffer from the temporal distinctiveness in the temporal changes of style latent vectors, which are inevitable during the generation of temporally stable videos with various facial expressions and geometric transformations. Our framework utilizes the StyleGRU module, trained by contrastive learning, to represent the dynamic properties of style latent vectors. Additionally, we introduce a style attention module that integrates StyleGRU-generated features with content-based features, enabling the detection of visual and temporal artifacts. We demonstrate our approach across various benchmark scenarios in deepfake detection, showing its superiority in cross-dataset and cross-manipulation scenarios. Through further analysis, we also validate the importance of using temporal changes of style latent vectors to improve the generality of deepfake video detection.
Text-Guided Variational Image Generation for Industrial Anomaly Detection and Segmentation
Mar 10, 2024



We propose a text-guided variational image generation method to address the challenge of getting clean data for anomaly detection in industrial manufacturing. Our method utilizes text information about the target object, learned from extensive text library documents, to generate non-defective data images resembling the input image. The proposed framework ensures that the generated non-defective images align with anticipated distributions derived from textual and image-based knowledge, ensuring stability and generality. Experimental results demonstrate the effectiveness of our approach, surpassing previous methods even with limited non-defective data. Our approach is validated through generalization tests across four baseline models and three distinct datasets. We present an additional analysis to enhance the effectiveness of anomaly detection models by utilizing the generated images.
Topic-VQ-VAE: Leveraging Latent Codebooks for Flexible Topic-Guided Document Generation
Dec 15, 2023



This paper introduces a novel approach for topic modeling utilizing latent codebooks from Vector-Quantized Variational Auto-Encoder~(VQ-VAE), discretely encapsulating the rich information of the pre-trained embeddings such as the pre-trained language model. From the novel interpretation of the latent codebooks and embeddings as conceptual bag-of-words, we propose a new generative topic model called Topic-VQ-VAE~(TVQ-VAE) which inversely generates the original documents related to the respective latent codebook. The TVQ-VAE can visualize the topics with various generative distributions including the traditional BoW distribution and the autoregressive image generation. Our experimental results on document analysis and image generation demonstrate that TVQ-VAE effectively captures the topic context which reveals the underlying structures of the dataset and supports flexible forms of document generation. Official implementation of the proposed TVQ-VAE is available at https://github.com/clovaai/TVQ-VAE.
Scaling of Class-wise Training Losses for Post-hoc Calibration
Jun 19, 2023The class-wise training losses often diverge as a result of the various levels of intra-class and inter-class appearance variation, and we find that the diverging class-wise training losses cause the uncalibrated prediction with its reliability. To resolve the issue, we propose a new calibration method to synchronize the class-wise training losses. We design a new training loss to alleviate the variance of class-wise training losses by using multiple class-wise scaling factors. Since our framework can compensate the training losses of overfitted classes with those of under-fitted classes, the integrated training loss is preserved, preventing the performance drop even after the model calibration. Furthermore, our method can be easily employed in the post-hoc calibration methods, allowing us to use the pre-trained model as an initial model and reduce the additional computation for model calibration. We validate the proposed framework by employing it in the various post-hoc calibration methods, which generally improves calibration performance while preserving accuracy, and discover through the investigation that our approach performs well with unbalanced datasets and untuned hyperparameters.
Adaptive Attention Link-based Regularization for Vision Transformers
Nov 25, 2022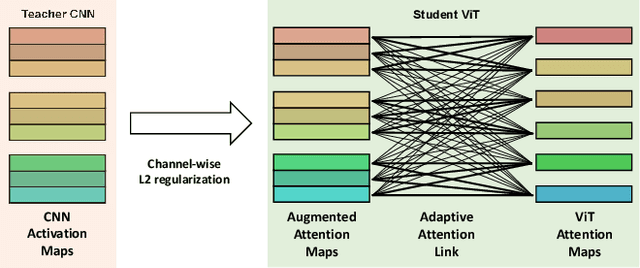



Although transformer networks are recently employed in various vision tasks with outperforming performance, extensive training data and a lengthy training time are required to train a model to disregard an inductive bias. Using trainable links between the channel-wise spatial attention of a pre-trained Convolutional Neural Network (CNN) and the attention head of Vision Transformers (ViT), we present a regularization technique to improve the training efficiency of ViT. The trainable links are referred to as the attention augmentation module, which is trained simultaneously with ViT, boosting the training of ViT and allowing it to avoid the overfitting issue caused by a lack of data. From the trained attention augmentation module, we can extract the relevant relationship between each CNN activation map and each ViT attention head, and based on this, we also propose an advanced attention augmentation module. Consequently, even with a small amount of data, the suggested method considerably improves the performance of ViT while achieving faster convergence during training.
FrePGAN: Robust Deepfake Detection Using Frequency-level Perturbations
Feb 07, 2022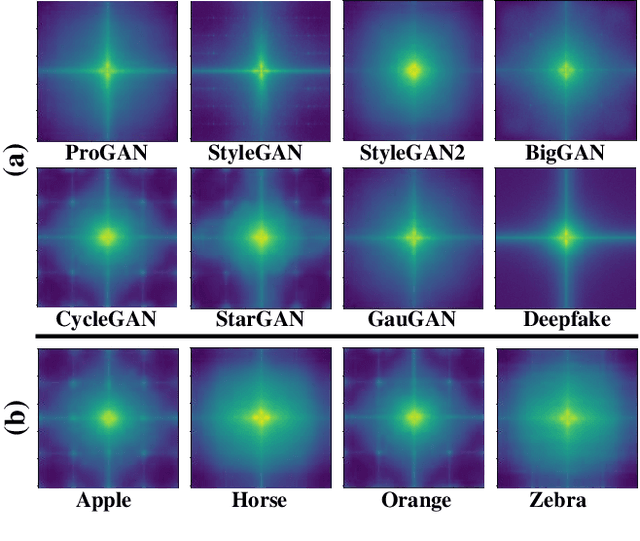

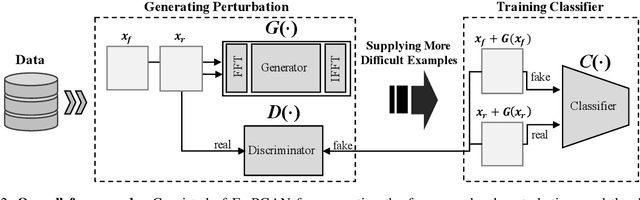
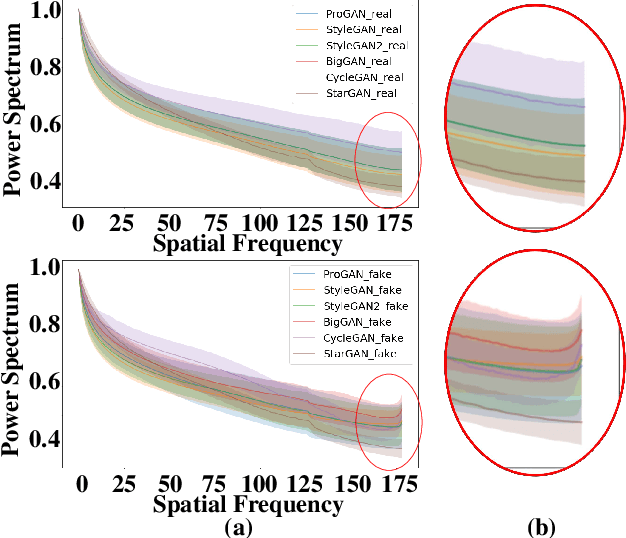
Various deepfake detectors have been proposed, but challenges still exist to detect images of unknown categories or GAN models outside of the training settings. Such issues arise from the overfitting issue, which we discover from our own analysis and the previous studies to originate from the frequency-level artifacts in generated images. We find that ignoring the frequency-level artifacts can improve the detector's generalization across various GAN models, but it can reduce the model's performance for the trained GAN models. Thus, we design a framework to generalize the deepfake detector for both the known and unseen GAN models. Our framework generates the frequency-level perturbation maps to make the generated images indistinguishable from the real images. By updating the deepfake detector along with the training of the perturbation generator, our model is trained to detect the frequency-level artifacts at the initial iterations and consider the image-level irregularities at the last iterations. For experiments, we design new test scenarios varying from the training settings in GAN models, color manipulations, and object categories. Numerous experiments validate the state-of-the-art performance of our deepfake detector.
Self-supervised GAN Detector
Nov 12, 2021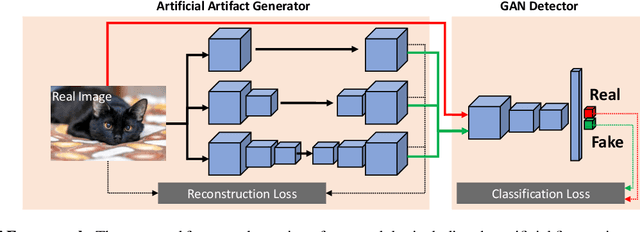
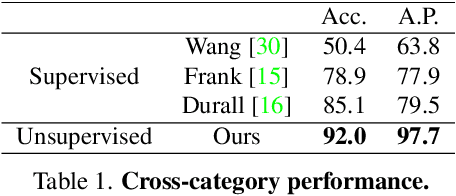
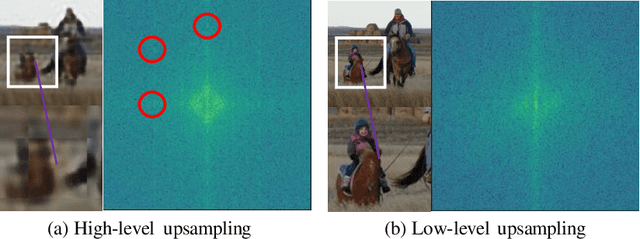

Although the recent advancement in generative models brings diverse advantages to society, it can also be abused with malicious purposes, such as fraud, defamation, and fake news. To prevent such cases, vigorous research is conducted to distinguish the generated images from the real images, but challenges still remain to distinguish the unseen generated images outside of the training settings. Such limitations occur due to data dependency arising from the model's overfitting issue to the training data generated by specific GANs. To overcome this issue, we adopt a self-supervised scheme to propose a novel framework. Our proposed method is composed of the artificial fingerprint generator reconstructing the high-quality artificial fingerprints of GAN images for detailed analysis, and the GAN detector distinguishing GAN images by learning the reconstructed artificial fingerprints. To improve the generalization of the artificial fingerprint generator, we build multiple autoencoders with different numbers of upconvolution layers. With numerous ablation studies, the robust generalization of our method is validated by outperforming the generalization of the previous state-of-the-art algorithms, even without utilizing the GAN images of the training dataset.
Observations on K-image Expansion of Image-Mixing Augmentation for Classification
Oct 08, 2021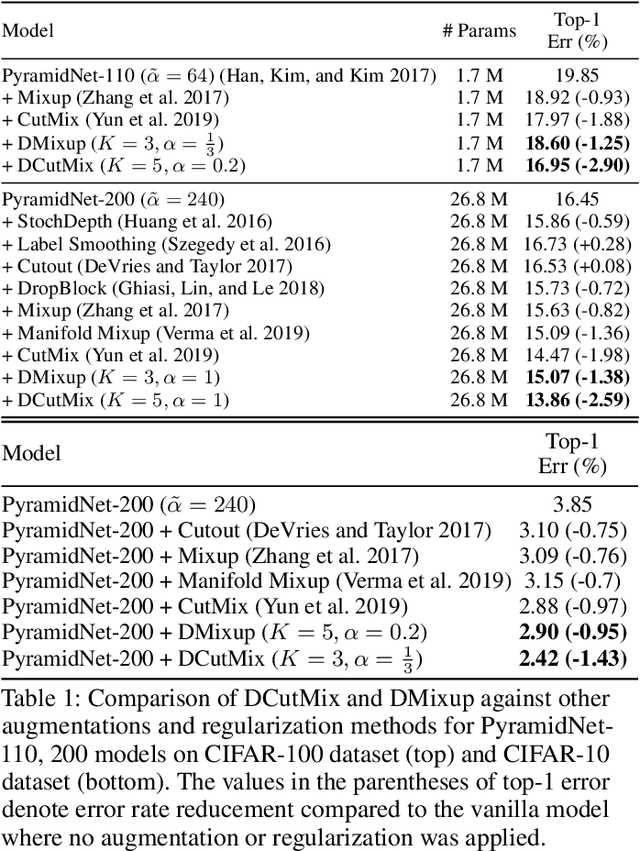
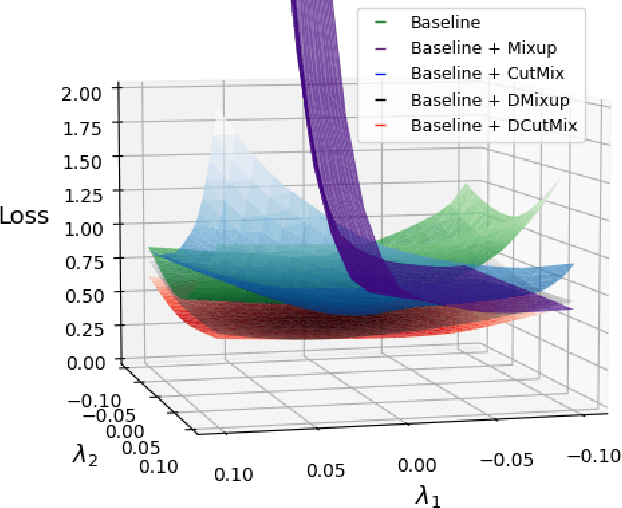

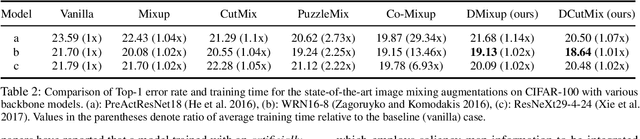
Image-mixing augmentations (e.g., Mixup or CutMix), which typically mix two images, have become de-facto training tricks for image classification. Despite their huge success on image classification, the number of images to mix has not been profoundly investigated by the previous works, only showing the naive K-image expansion leads to poor performance degradation. This paper derives a new K-image mixing augmentation based on the stick-breaking process under Dirichlet prior. We show that our method can train more robust and generalized classifiers through extensive experiments and analysis on classification accuracy, a shape of a loss landscape and adversarial robustness, than the usual two-image methods. Furthermore, we show that our probabilistic model can measure the sample-wise uncertainty and can boost the efficiency for Network Architecture Search (NAS) with 7x reduced search time.
MToFNet: Object Anti-Spoofing with Mobile Time-of-Flight Data
Oct 06, 2021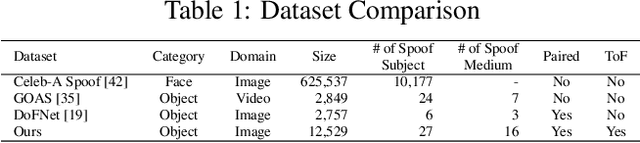
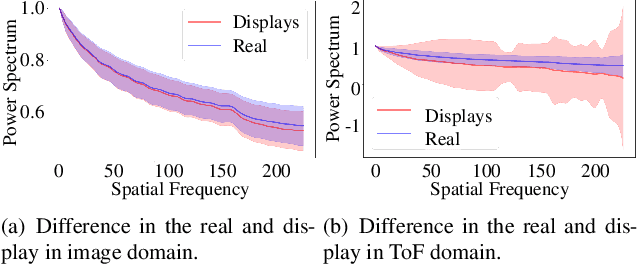

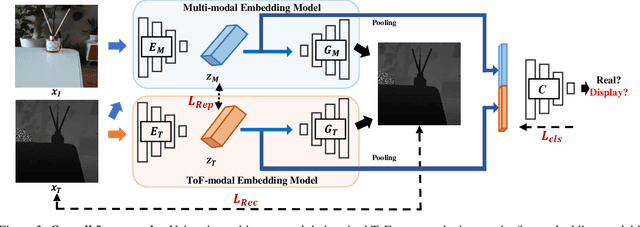
In online markets, sellers can maliciously recapture others' images on display screens to utilize as spoof images, which can be challenging to distinguish in human eyes. To prevent such harm, we propose an anti-spoofing method using the paired rgb images and depth maps provided by the mobile camera with a Time-of-Fight sensor. When images are recaptured on display screens, various patterns differing by the screens as known as the moir\'e patterns can be also captured in spoof images. These patterns lead the anti-spoofing model to be overfitted and unable to detect spoof images recaptured on unseen media. To avoid the issue, we build a novel representation model composed of two embedding models, which can be trained without considering the recaptured images. Also, we newly introduce mToF dataset, the largest and most diverse object anti-spoofing dataset, and the first to utilize ToF data. Experimental results confirm that our model achieves robust generalization even across unseen domains.