 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Test-Time Adaptation: Style Invariance as a Correctness Likelihood
Dec 08, 2025Test-time adaptation (TTA) enables efficient adaptation of deployed models, yet it often leads to poorly calibrated predictive uncertainty - a critical issue in high-stakes domains such as autonomous driving, finance, and healthcare. Existing calibration methods typically assume fixed models or static distributions, resulting in degraded performance under real-world, dynamic test conditions. To address these challenges, we introduce Style Invariance as a Correctness Likelihood (SICL), a framework that leverages style-invariance for robust uncertainty estimation. SICL estimates instance-wise correctness likelihood by measuring prediction consistency across style-altered variants, requiring only the model's forward pass. This makes it a plug-and-play, backpropagation-free calibration module compatible with any TTA method. Comprehensive evaluations across four baselines, five TTA methods, and two realistic scenarios with three model architecture demonstrate that SICL reduces calibration error by an average of 13 percentage points compared to conventional calibration approaches.
ZIM: Zero-Shot Image Matting for Anything
Nov 01, 2024



The recent segmentation foundation model, Segment Anything Model (SAM), exhibits strong zero-shot segmentation capabilities, but it falls short in generating fine-grained precise masks. To address this limitation, we propose a novel zero-shot image matting model, called ZIM, with two key contributions: First, we develop a label converter that transforms segmentation labels into detailed matte labels, constructing the new SA1B-Matte dataset without costly manual annotations. Training SAM with this dataset enables it to generate precise matte masks while maintaining its zero-shot capability. Second, we design the zero-shot matting model equipped with a hierarchical pixel decoder to enhance mask representation, along with a prompt-aware masked attention mechanism to improve performance by enabling the model to focus on regions specified by visual prompts. We evaluate ZIM using the newly introduced MicroMat-3K test set, which contains high-quality micro-level matte labels. Experimental results show that ZIM outperforms existing methods in fine-grained mask generation and zero-shot generalization. Furthermore, we demonstrate the versatility of ZIM in various downstream tasks requiring precise masks, such as image inpainting and 3D NeRF. Our contributions provide a robust foundation for advancing zero-shot matting and its downstream applications across a wide range of computer vision tasks. The code is available at \url{https://github.com/naver-ai/ZIM}.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
ProxyDet: Synthesizing Proxy Novel Classes via Classwise Mixup for Open-Vocabulary Object Detection
Dec 19, 2023Open-vocabulary object detection (OVOD) aims to recognize novel objects whose categories are not included in the training set. In order to classify these unseen classes during training, many OVOD frameworks leverage the zero-shot capability of largely pretrained vision and language models, such as CLIP. To further improve generalization on the unseen novel classes, several approaches proposed to additionally train with pseudo region labeling on the external data sources that contain a substantial number of novel category labels beyond the existing training data. Albeit its simplicity, these pseudo-labeling methods still exhibit limited improvement with regard to the truly unseen novel classes that were not pseudo-labeled. In this paper, we present a novel, yet simple technique that helps generalization on the overall distribution of novel classes. Inspired by our observation that numerous novel classes reside within the convex hull constructed by the base (seen) classes in the CLIP embedding space, we propose to synthesize proxy-novel classes approximating novel classes via linear mixup between a pair of base classes. By training our detector with these synthetic proxy-novel classes, we effectively explore the embedding space of novel classes. The experimental results on various OVOD benchmarks such as LVIS and COCO demonstrate superior performance on novel classes compared to the other state-of-the-art methods. Code is available at https://github.com/clovaai/ProxyDet.
Hijacking Context in Large Multi-modal Models
Dec 07, 2023Recently, Large Multi-modal Models (LMMs) have demonstrated their ability to understand the visual contents of images given the instructions regarding the images. Built upon the Large Language Models (LLMs), LMMs also inherit their abilities and characteristics such as in-context learning where a coherent sequence of images and texts are given as the input prompt. However, we identify a new limitation of off-the-shelf LMMs where a small fraction of incoherent images or text descriptions mislead LMMs to only generate biased output about the hijacked context, not the originally intended context. To address this, we propose a pre-filtering method that removes irrelevant contexts via GPT-4V, based on its robustness towards distribution shift within the contexts. We further investigate whether replacing the hijacked visual and textual contexts with the correlated ones via GPT-4V and text-to-image models can help yield coherent responses.
GeNAS: Neural Architecture Search with Better Generalization
May 18, 2023Neural Architecture Search (NAS) aims to automatically excavate the optimal network architecture with superior test performance. Recent neural architecture search (NAS) approaches rely on validation loss or accuracy to find the superior network for the target data. In this paper, we investigate a new neural architecture search measure for excavating architectures with better generalization. We demonstrate that the flatness of the loss surface can be a promising proxy for predicting the generalization capability of neural network architectures. We evaluate our proposed method on various search spaces, showing similar or even better performance compared to the state-of-the-art NAS methods. Notably, the resultant architecture found by flatness measure generalizes robustly to various shifts in data distribution (e.g. ImageNet-V2,-A,-O), as well as various tasks such as object detection and semantic segmentation. Code is available at https://github.com/clovaai/GeNAS.
The Devil is in the Points: Weakly Semi-Supervised Instance Segmentation via Point-Guided Mask Representation
Mar 27, 2023In this paper, we introduce a novel learning scheme named weakly semi-supervised instance segmentation (WSSIS) with point labels for budget-efficient and high-performance instance segmentation. Namely, we consider a dataset setting consisting of a few fully-labeled images and a lot of point-labeled images. Motivated by the main challenge of semi-supervised approaches mainly derives from the trade-off between false-negative and false-positive instance proposals, we propose a method for WSSIS that can effectively leverage the budget-friendly point labels as a powerful weak supervision source to resolve the challenge. Furthermore, to deal with the hard case where the amount of fully-labeled data is extremely limited, we propose a MaskRefineNet that refines noise in rough masks. We conduct extensive experiments on COCO and BDD100K datasets, and the proposed method achieves promising results comparable to those of the fully-supervised model, even with 50% of the fully labeled COCO data (38.8% vs. 39.7%). Moreover, when using as little as 5% of fully labeled COCO data, our method shows significantly superior performance over the state-of-the-art semi-supervised learning method (33.7% vs. 24.9%). The code is available at https://github.com/clovaai/PointWSSIS.
Dataset Condensation via Efficient Synthetic-Data Parameterization
Jun 02, 2022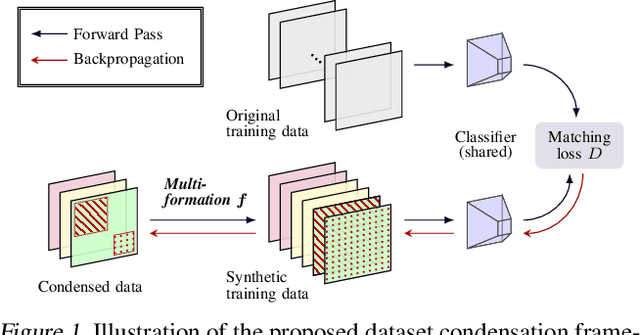
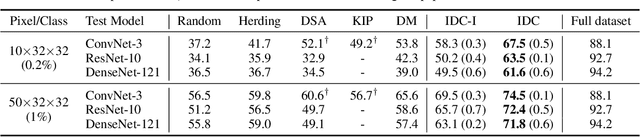
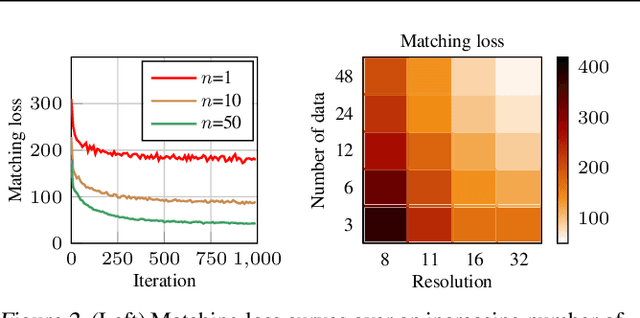
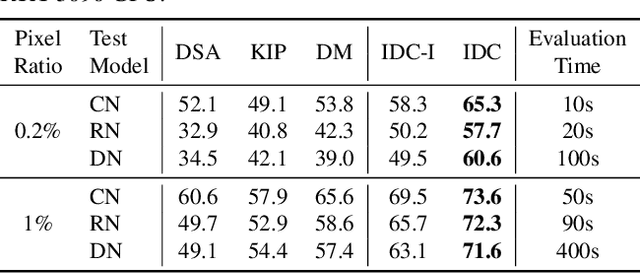
The great success of machine learning with massive amounts of data comes at a price of huge computation costs and storage for training and tuning. Recent studies on dataset condensation attempt to reduce the dependence on such massive data by synthesizing a compact training dataset. However, the existing approaches have fundamental limitations in optimization due to the limited representability of synthetic datasets without considering any data regularity characteristics. To this end, we propose a novel condensation framework that generates multiple synthetic data with a limited storage budget via efficient parameterization considering data regularity. We further analyze the shortcomings of the existing gradient matching-based condensation methods and develop an effective optimization technique for improving the condensation of training data information. We propose a unified algorithm that drastically improves the quality of condensed data against the current state-of-the-art on CIFAR-10, ImageNet, and Speech Commands.
Rediscovery of the Effectiveness of Standard Convolution for Lightweight Face Detection
Apr 04, 2022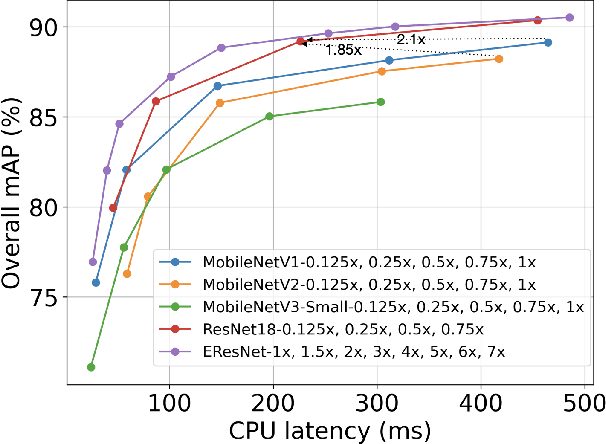
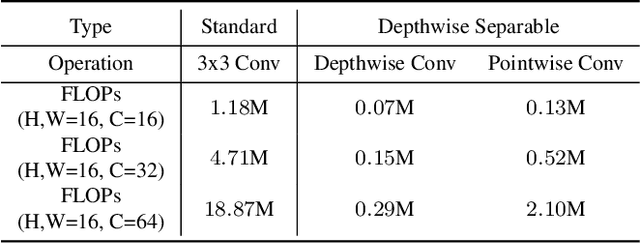
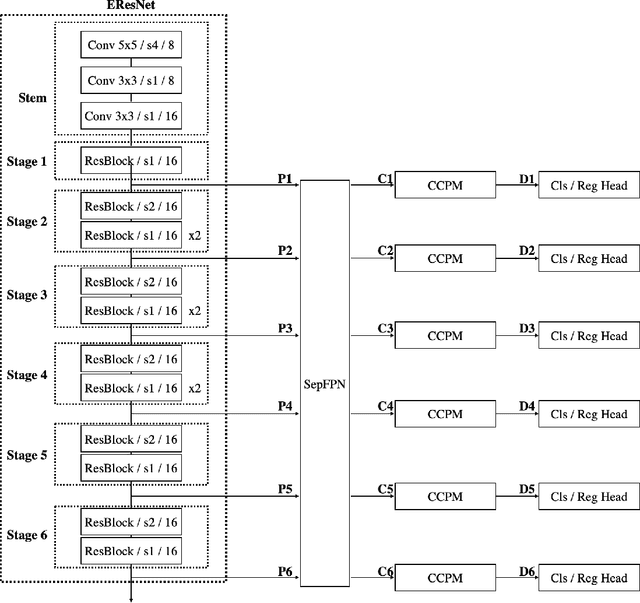
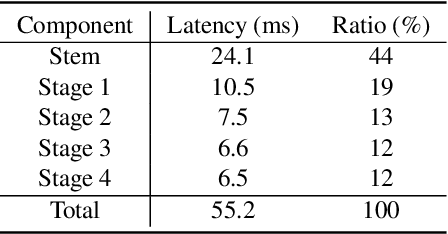
This paper analyses the design choices of face detection architecture that improve efficiency between computation cost and accuracy. Specifically, we re-examine the effectiveness of the standard convolutional block as a lightweight backbone architecture on face detection. Unlike the current tendency of lightweight architecture design, which heavily utilizes depthwise separable convolution layers, we show that heavily channel-pruned standard convolution layer can achieve better accuracy and inference speed when using a similar parameter size. This observation is supported by the analyses concerning the characteristics of the target data domain, face. Based on our observation, we propose to employ ResNet with a highly reduced channel, which surprisingly allows high efficiency compared to other mobile-friendly networks (e.g., MobileNet-V1,-V2,-V3). From the extensive experiments, we show that the proposed backbone can replace that of the state-of-the-art face detector with a faster inference speed. Also, we further propose a new feature aggregation method maximizing the detection performance. Our proposed detector EResFD obtained 80.4% mAP on WIDER FACE Hard subset which only takes 37.7 ms for VGA image inference in on CPU. Code will be available at https://github.com/clovaai/EResFD.
Observations on K-image Expansion of Image-Mixing Augmentation for Classification
Oct 08, 2021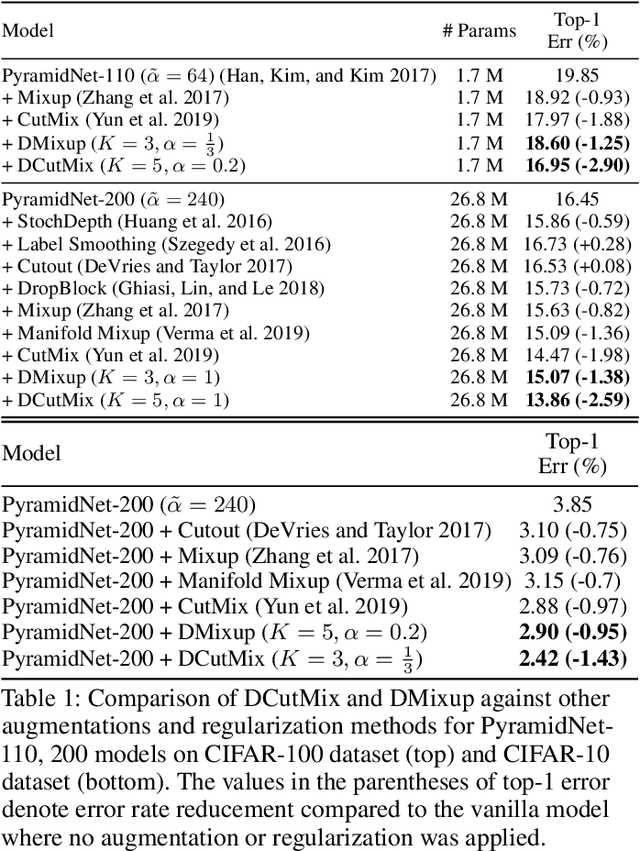
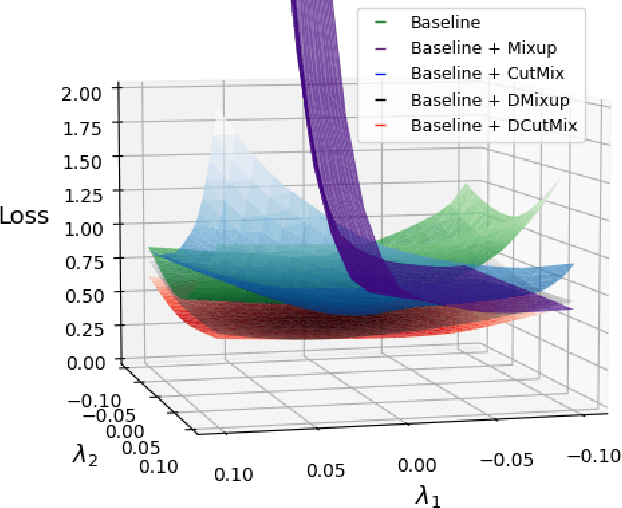

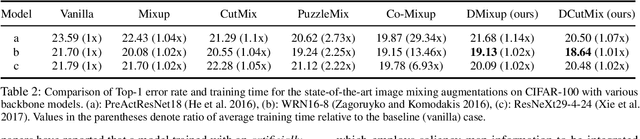
Image-mixing augmentations (e.g., Mixup or CutMix), which typically mix two images, have become de-facto training tricks for image classification. Despite their huge success on image classification, the number of images to mix has not been profoundly investigated by the previous works, only showing the naive K-image expansion leads to poor performance degradation. This paper derives a new K-image mixing augmentation based on the stick-breaking process under Dirichlet prior. We show that our method can train more robust and generalized classifiers through extensive experiments and analysis on classification accuracy, a shape of a loss landscape and adversarial robustness, than the usual two-image methods. Furthermore, we show that our probabilistic model can measure the sample-wise uncertainty and can boost the efficiency for Network Architecture Search (NAS) with 7x reduced search time.