 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHourglassNeRF: Casting an Hourglass as a Bundle of Rays for Few-shot Neural Rendering
Mar 16, 2024Recent advancements in the Neural Radiance Field (NeRF) have bolstered its capabilities for novel view synthesis, yet its reliance on dense multi-view training images poses a practical challenge. Addressing this, we propose HourglassNeRF, an effective regularization-based approach with a novel hourglass casting strategy. Our proposed hourglass is conceptualized as a bundle of additional rays within the area between the original input ray and its corresponding reflection ray, by featurizing the conical frustum via Integrated Positional Encoding (IPE). This design expands the coverage of unseen views and enables an adaptive high-frequency regularization based on target pixel photo-consistency. Furthermore, we propose luminance consistency regularization based on the Lambertian assumption, which is known to be effective for training a set of augmented rays under the few-shot setting. Leveraging the inherent property of a Lambertian surface, which retains consistent luminance irrespective of the viewing angle, we assume our proposed hourglass as a collection of flipped diffuse reflection rays and enhance the luminance consistency between the original input ray and its corresponding hourglass, resulting in more physically grounded training framework and performance improvement. Our HourglassNeRF outperforms its baseline and achieves competitive results on multiple benchmarks with sharply rendered fine details. The code will be available.
Mitigating the Bias in the Model for Continual Test-Time Adaptation
Mar 02, 2024
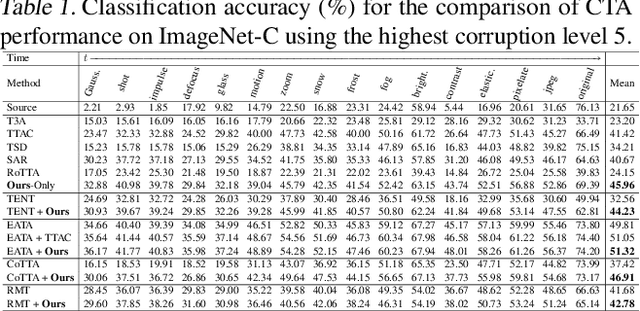
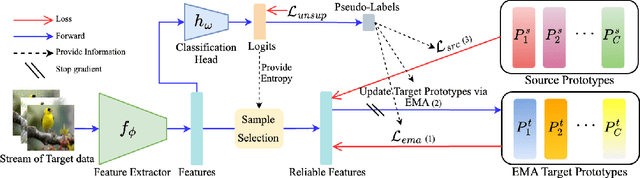
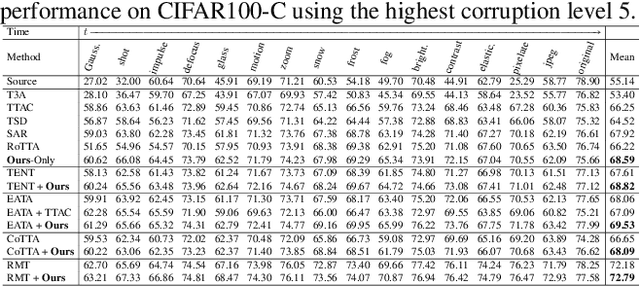
Continual Test-Time Adaptation (CTA) is a challenging task that aims to adapt a source pre-trained model to continually changing target domains. In the CTA setting, a model does not know when the target domain changes, thus facing a drastic change in the distribution of streaming inputs during the test-time. The key challenge is to keep adapting the model to the continually changing target domains in an online manner. We find that a model shows highly biased predictions as it constantly adapts to the chaining distribution of the target data. It predicts certain classes more often than other classes, making inaccurate over-confident predictions. This paper mitigates this issue to improve performance in the CTA scenario. To alleviate the bias issue, we make class-wise exponential moving average target prototypes with reliable target samples and exploit them to cluster the target features class-wisely. Moreover, we aim to align the target distributions to the source distribution by anchoring the target feature to its corresponding source prototype. With extensive experiments, our proposed method achieves noteworthy performance gain when applied on top of existing CTA methods without substantial adaptation time overhead.
ProxyDet: Synthesizing Proxy Novel Classes via Classwise Mixup for Open-Vocabulary Object Detection
Dec 19, 2023Open-vocabulary object detection (OVOD) aims to recognize novel objects whose categories are not included in the training set. In order to classify these unseen classes during training, many OVOD frameworks leverage the zero-shot capability of largely pretrained vision and language models, such as CLIP. To further improve generalization on the unseen novel classes, several approaches proposed to additionally train with pseudo region labeling on the external data sources that contain a substantial number of novel category labels beyond the existing training data. Albeit its simplicity, these pseudo-labeling methods still exhibit limited improvement with regard to the truly unseen novel classes that were not pseudo-labeled. In this paper, we present a novel, yet simple technique that helps generalization on the overall distribution of novel classes. Inspired by our observation that numerous novel classes reside within the convex hull constructed by the base (seen) classes in the CLIP embedding space, we propose to synthesize proxy-novel classes approximating novel classes via linear mixup between a pair of base classes. By training our detector with these synthetic proxy-novel classes, we effectively explore the embedding space of novel classes. The experimental results on various OVOD benchmarks such as LVIS and COCO demonstrate superior performance on novel classes compared to the other state-of-the-art methods. Code is available at https://github.com/clovaai/ProxyDet.
What, How, and When Should Object Detectors Update in Continually Changing Test Domains?
Dec 12, 2023



It is a well-known fact that the performance of deep learning models deteriorates when they encounter a distribution shift at test time. Test-time adaptation (TTA) algorithms have been proposed to adapt the model online while inferring test data. However, existing research predominantly focuses on classification tasks through the optimization of batch normalization layers or classification heads, but this approach limits its applicability to various model architectures like Transformers and makes it challenging to apply to other tasks, such as object detection. In this paper, we propose a novel online adaption approach for object detection in continually changing test domains, considering which part of the model to update, how to update it, and when to perform the update. By introducing architecture-agnostic and lightweight adaptor modules and only updating these while leaving the pre-trained backbone unchanged, we can rapidly adapt to new test domains in an efficient way and prevent catastrophic forgetting. Furthermore, we present a practical and straightforward class-wise feature aligning method for object detection to resolve domain shifts. Additionally, we enhance efficiency by determining when the model is sufficiently adapted or when additional adaptation is needed due to changes in the test distribution. Our approach surpasses baselines on widely used benchmarks, achieving improvements of up to 4.9\%p and 7.9\%p in mAP for COCO $\rightarrow$ COCO-corrupted and SHIFT, respectively, while maintaining about 20 FPS or higher.
SHOT: Suppressing the Hessian along the Optimization Trajectory for Gradient-Based Meta-Learning
Oct 04, 2023



In this paper, we hypothesize that gradient-based meta-learning (GBML) implicitly suppresses the Hessian along the optimization trajectory in the inner loop. Based on this hypothesis, we introduce an algorithm called SHOT (Suppressing the Hessian along the Optimization Trajectory) that minimizes the distance between the parameters of the target and reference models to suppress the Hessian in the inner loop. Despite dealing with high-order terms, SHOT does not increase the computational complexity of the baseline model much. It is agnostic to both the algorithm and architecture used in GBML, making it highly versatile and applicable to any GBML baseline. To validate the effectiveness of SHOT, we conduct empirical tests on standard few-shot learning tasks and qualitatively analyze its dynamics. We confirm our hypothesis empirically and demonstrate that SHOT outperforms the corresponding baseline. Code is available at: https://github.com/JunHoo-Lee/SHOT
Unsupervised Domain Adaptation for One-stage Object Detector using Offsets to Bounding Box
Jul 20, 2022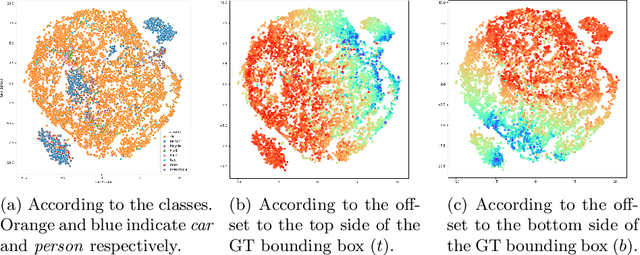


Most existing domain adaptive object detection methods exploit adversarial feature alignment to adapt the model to a new domain. Recent advances in adversarial feature alignment strives to reduce the negative effect of alignment, or negative transfer, that occurs because the distribution of features varies depending on the category of objects. However, by analyzing the features of the anchor-free one-stage detector, in this paper, we find that negative transfer may occur because the feature distribution varies depending on the regression value for the offset to the bounding box as well as the category. To obtain domain invariance by addressing this issue, we align the feature conditioned on the offset value, considering the modality of the feature distribution. With a very simple and effective conditioning method, we propose OADA (Offset-Aware Domain Adaptive object detector) that achieves state-of-the-art performances in various experimental settings. In addition, by analyzing through singular value decomposition, we find that our model enhances both discriminability and transferability.
Exploiting Inter-pixel Correlations in Unsupervised Domain Adaptation for Semantic Segmentation
Oct 21, 2021
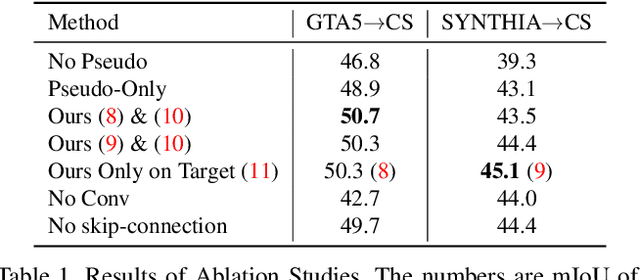
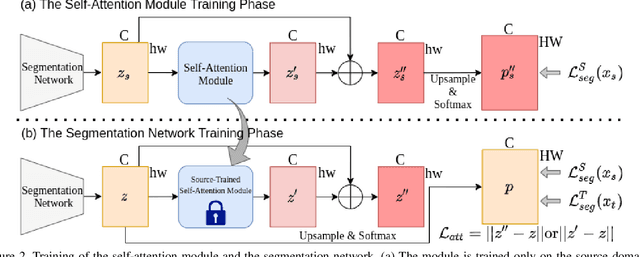
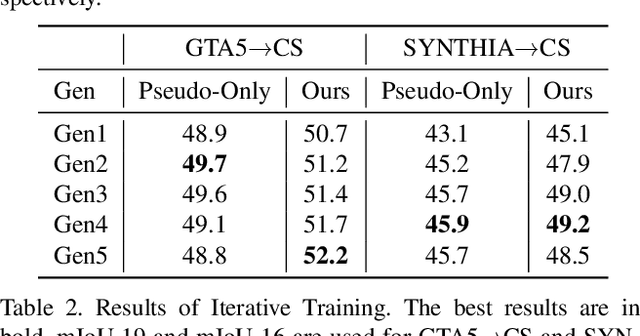
"Self-training" has become a dominant method for semantic segmentation via unsupervised domain adaptation (UDA). It creates a set of pseudo labels for the target domain to give explicit supervision. However, the pseudo labels are noisy, sparse and do not provide any information about inter-pixel correlations. We regard inter-pixel correlation quite important because semantic segmentation is a task of predicting highly structured pixel-level outputs. Therefore, in this paper, we propose a method of transferring the inter-pixel correlations from the source domain to the target domain via a self-attention module. The module takes the prediction of the segmentation network as an input and creates a self-attended prediction that correlates similar pixels. The module is trained only on the source domain to learn the domain-invariant inter-pixel correlations, then later, it is used to train the segmentation network on the target domain. The network learns not only from the pseudo labels but also by following the output of the self-attention module which provides additional knowledge about the inter-pixel correlations. Through extensive experiments, we show that our method significantly improves the performance on two standard UDA benchmarks and also can be combined with recent state-of-the-art method to achieve better performance.
Dynamic Collective Intelligence Learning: Finding Efficient Sparse Model via Refined Gradients for Pruned Weights
Sep 10, 2021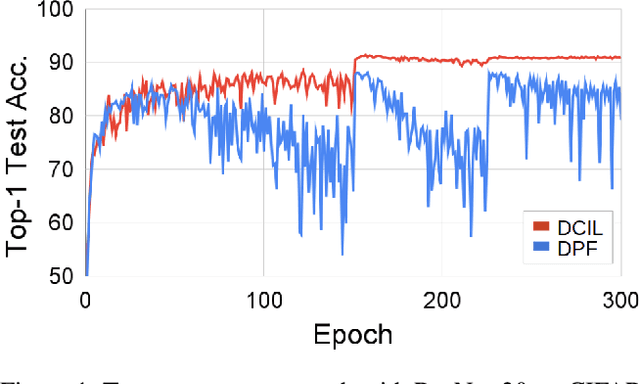
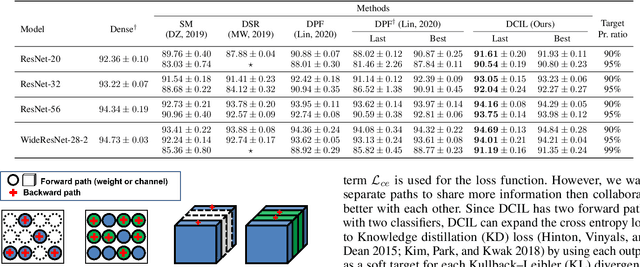
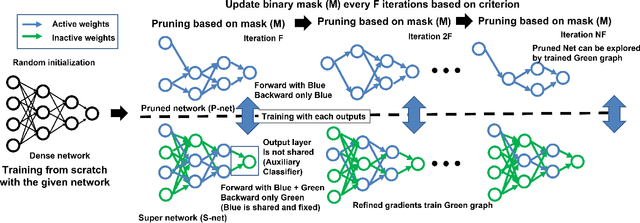
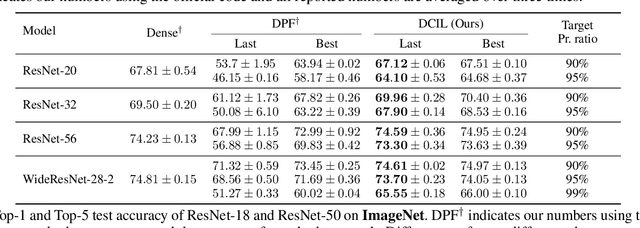
With the growth of deep neural networks (DNN), the number of DNN parameters has drastically increased. This makes DNN models hard to be deployed on resource-limited embedded systems. To alleviate this problem, dynamic pruning methods have emerged, which try to find diverse sparsity patterns during training by utilizing Straight-Through-Estimator (STE) to approximate gradients of pruned weights. STE can help the pruned weights revive in the process of finding dynamic sparsity patterns. However, using these coarse gradients causes training instability and performance degradation owing to the unreliable gradient signal of the STE approximation. In this work, to tackle this issue, we introduce refined gradients to update the pruned weights by forming dual forwarding paths from two sets (pruned and unpruned) of weights. We propose a novel Dynamic Collective Intelligence Learning (DCIL) which makes use of the learning synergy between the collective intelligence of both weight sets. We verify the usefulness of the refined gradients by showing enhancements in the training stability and the model performance on the CIFAR and ImageNet datasets. DCIL outperforms various previously proposed pruning schemes including other dynamic pruning methods with enhanced stability during training.
Learning Dynamic Network Using a Reuse Gate Function in Semi-supervised Video Object Segmentation
Dec 21, 2020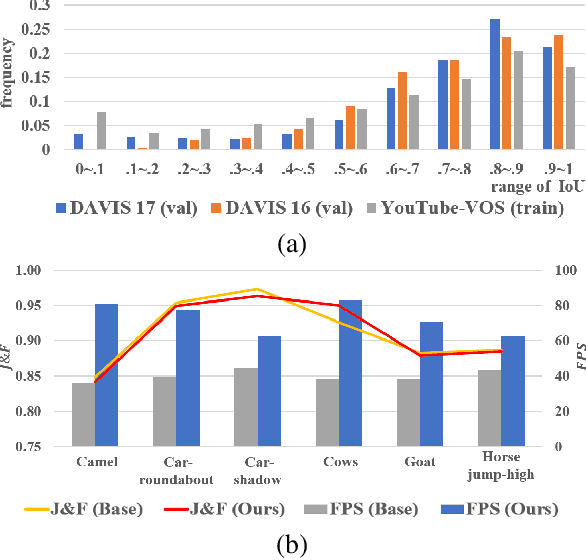
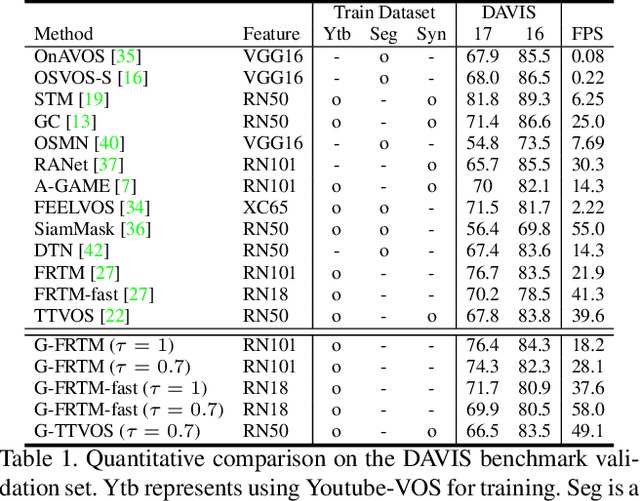
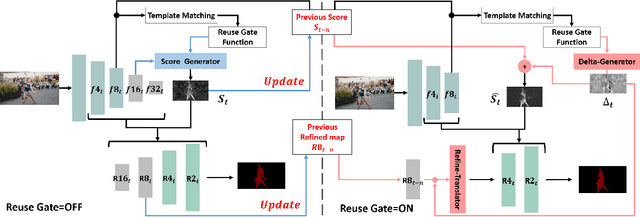
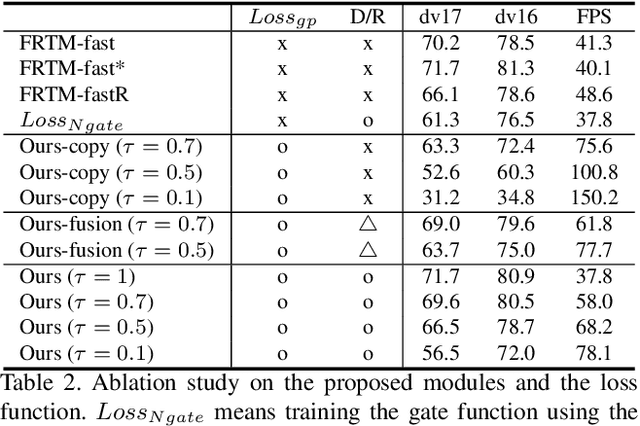
Current state-of-the-art approaches for Semi-supervised Video Object Segmentation (Semi-VOS) propagates information from previous frames to generate segmentation mask for the current frame. This results in high-quality segmentation across challenging scenarios such as changes in appearance and occlusion. But it also leads to unnecessary computations for stationary or slow-moving objects where the change across frames is minimal. In this work, we exploit this observation by using temporal information to quickly identify frames with minimal change and skip the heavyweight mask generation step. To realize this efficiency, we propose a novel dynamic network that estimates change across frames and decides which path -- computing a full network or reusing previous frame's feature -- to choose depending on the expected similarity. Experimental results show that our approach significantly improves inference speed without much accuracy degradation on challenging Semi-VOS datasets -- DAVIS 16, DAVIS 17, and YouTube-VOS. Furthermore, our approach can be applied to multiple Semi-VOS methods demonstrating its generality.