 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyNeT: Synthetic Negatives for Traversability Learning
Feb 03, 2026Reliable traversability estimation is crucial for autonomous robots to navigate complex outdoor environments safely. Existing self-supervised learning frameworks primarily rely on positive and unlabeled data; however, the lack of explicit negative data remains a critical limitation, hindering the model's ability to accurately identify diverse non-traversable regions. To address this issue, we introduce a method to explicitly construct synthetic negatives, representing plausible but non-traversable, and integrate them into vision-based traversability learning. Our approach is formulated as a training strategy that can be seamlessly integrated into both Positive-Unlabeled (PU) and Positive-Negative (PN) frameworks without modifying inference architectures. Complementing standard pixel-wise metrics, we introduce an object-centric FPR evaluation approach that analyzes predictions in regions where synthetic negatives are inserted. This evaluation provides an indirect measure of the model's ability to consistently identify non-traversable regions without additional manual labeling. Extensive experiments on both public and self-collected datasets demonstrate that our approach significantly enhances robustness and generalization across diverse environments. The source code and demonstration videos will be publicly available.
Targeted Data Protection for Diffusion Model by Matching Training Trajectory
Dec 11, 2025Recent advancements in diffusion models have made fine-tuning text-to-image models for personalization increasingly accessible, but have also raised significant concerns regarding unauthorized data usage and privacy infringement. Current protection methods are limited to passively degrading image quality, failing to achieve stable control. While Targeted Data Protection (TDP) offers a promising paradigm for active redirection toward user-specified target concepts, existing TDP attempts suffer from poor controllability due to snapshot-matching approaches that fail to account for complete learning dynamics. We introduce TAFAP (Trajectory Alignment via Fine-tuning with Adversarial Perturbations), the first method to successfully achieve effective TDP by controlling the entire training trajectory. Unlike snapshot-based methods whose protective influence is easily diluted as training progresses, TAFAP employs trajectory-matching inspired by dataset distillation to enforce persistent, verifiable transformations throughout fine-tuning. We validate our method through extensive experiments, demonstrating the first successful targeted transformation in diffusion models with simultaneous control over both identity and visual patterns. TAFAP significantly outperforms existing TDP attempts, achieving robust redirection toward target concepts while maintaining high image quality. This work enables verifiable safeguards and provides a new framework for controlling and tracing alterations in diffusion model outputs.
IMPACT: Industrial Machine Perception via Acoustic Cognitive Transformer
Jul 09, 2025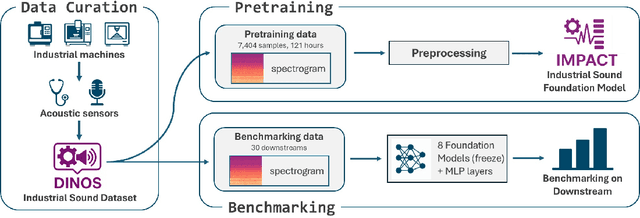
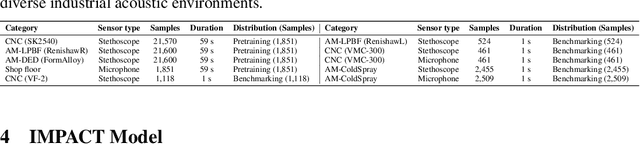

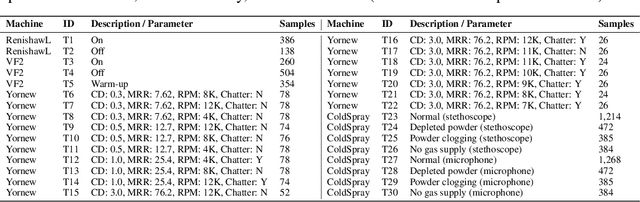
Acoustic signals from industrial machines offer valuable insights for anomaly detection, predictive maintenance, and operational efficiency enhancement. However, existing task-specific, supervised learning methods often scale poorly and fail to generalize across diverse industrial scenarios, whose acoustic characteristics are distinct from general audio. Furthermore, the scarcity of accessible, large-scale datasets and pretrained models tailored for industrial audio impedes community-driven research and benchmarking. To address these challenges, we introduce DINOS (Diverse INdustrial Operation Sounds), a large-scale open-access dataset. DINOS comprises over 74,149 audio samples (exceeding 1,093 hours) collected from various industrial acoustic scenarios. We also present IMPACT (Industrial Machine Perception via Acoustic Cognitive Transformer), a novel foundation model for industrial machine sound analysis. IMPACT is pretrained on DINOS in a self-supervised manner. By jointly optimizing utterance and frame-level losses, it captures both global semantics and fine-grained temporal structures. This makes its representations suitable for efficient fine-tuning on various industrial downstream tasks with minimal labeled data. Comprehensive benchmarking across 30 distinct downstream tasks (spanning four machine types) demonstrates that IMPACT outperforms existing models on 24 tasks, establishing its superior effectiveness and robustness, while providing a new performance benchmark for future research.
Coreset Selection for Object Detection
Apr 14, 2024



Coreset selection is a method for selecting a small, representative subset of an entire dataset. It has been primarily researched in image classification, assuming there is only one object per image. However, coreset selection for object detection is more challenging as an image can contain multiple objects. As a result, much research has yet to be done on this topic. Therefore, we introduce a new approach, Coreset Selection for Object Detection (CSOD). CSOD generates imagewise and classwise representative feature vectors for multiple objects of the same class within each image. Subsequently, we adopt submodular optimization for considering both representativeness and diversity and utilize the representative vectors in the submodular optimization process to select a subset. When we evaluated CSOD on the Pascal VOC dataset, CSOD outperformed random selection by +6.4%p in AP$_{50}$ when selecting 200 images.
HourglassNeRF: Casting an Hourglass as a Bundle of Rays for Few-shot Neural Rendering
Mar 16, 2024Recent advancements in the Neural Radiance Field (NeRF) have bolstered its capabilities for novel view synthesis, yet its reliance on dense multi-view training images poses a practical challenge. Addressing this, we propose HourglassNeRF, an effective regularization-based approach with a novel hourglass casting strategy. Our proposed hourglass is conceptualized as a bundle of additional rays within the area between the original input ray and its corresponding reflection ray, by featurizing the conical frustum via Integrated Positional Encoding (IPE). This design expands the coverage of unseen views and enables an adaptive high-frequency regularization based on target pixel photo-consistency. Furthermore, we propose luminance consistency regularization based on the Lambertian assumption, which is known to be effective for training a set of augmented rays under the few-shot setting. Leveraging the inherent property of a Lambertian surface, which retains consistent luminance irrespective of the viewing angle, we assume our proposed hourglass as a collection of flipped diffuse reflection rays and enhance the luminance consistency between the original input ray and its corresponding hourglass, resulting in more physically grounded training framework and performance improvement. Our HourglassNeRF outperforms its baseline and achieves competitive results on multiple benchmarks with sharply rendered fine details. The code will be available.
Tradeoff of generalization error in unsupervised learning
Mar 10, 2023Finding the optimal model complexity that minimizes the generalization error (GE) is a key issue of machine learning. For the conventional supervised learning, this task typically involves the bias-variance tradeoff: lowering the bias by making the model more complex entails an increase in the variance. Meanwhile, little has been studied about whether the same tradeoff exists for unsupervised learning. In this study, we propose that unsupervised learning generally exhibits a two-component tradeoff of the GE, namely the model error and the data error -- using a more complex model reduces the model error at the cost of the data error, with the data error playing a more significant role for a smaller training dataset. This is corroborated by training the restricted Boltzmann machine to generate the configurations of the two-dimensional Ising model at a given temperature and the totally asymmetric simple exclusion process with given entry and exit rates. Our results also indicate that the optimal model tends to be more complex when the data to be learned are more complex.
Sparse MDOD: Training End-to-End Multi-Object Detector without Bipartite Matching
May 18, 2022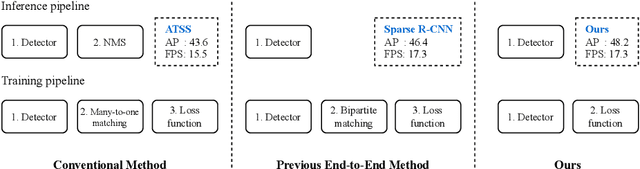
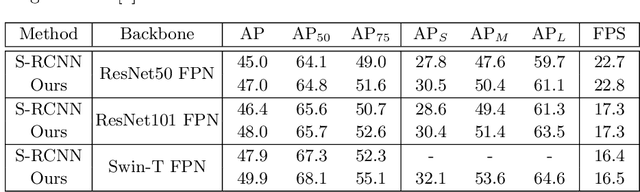
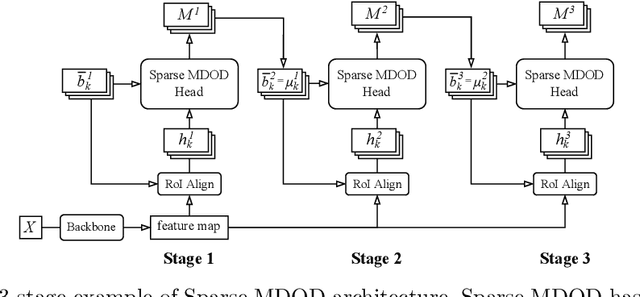
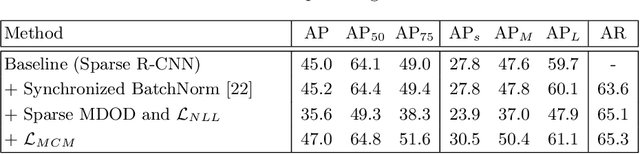
Recent end-to-end multi-object detectors simplify the inference pipeline by removing the hand-crafted process such as the duplicate bounding box removal using non-maximum suppression (NMS). However, in the training, they require bipartite matching to calculate the loss from the output of the detector. Contrary to the directivity of the end-to-end method, the bipartite matching makes the training of the end-to-end detector complex, heuristic, and reliant. In this paper, we aim to propose a method to train the end-to-end multi-object detector without bipartite matching. To this end, we approach end-to-end multi-object detection as a density estimation using a mixture model. Our proposed detector, called Sparse Mixture Density Object Detector (Sparse MDOD) estimates the distribution of bounding boxes using a mixture model. Sparse MDOD is trained by minimizing the negative log-likelihood and our proposed regularization term, maximum component maximization (MCM) loss that prevents duplicated predictions. During training, no additional procedure such as bipartite matching is needed, and the loss is directly computed from the network outputs. Moreover, our Sparse MDOD outperforms the existing detectors on MS-COCO, a renowned multi-object detection benchmark.
Few-Shot Object Detection by Attending to Per-Sample-Prototype
Sep 16, 2021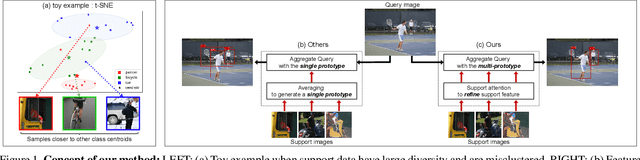

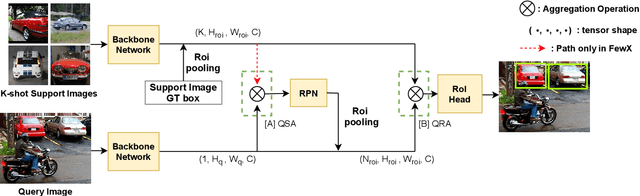

Few-shot object detection aims to detect instances of specific categories in a query image with only a handful of support samples. Although this takes less effort than obtaining enough annotated images for supervised object detection, it results in a far inferior performance compared to the conventional object detection methods. In this paper, we propose a meta-learning-based approach that considers the unique characteristics of each support sample. Rather than simply averaging the information of the support samples to generate a single prototype per category, our method can better utilize the information of each support sample by treating each support sample as an individual prototype. Specifically, we introduce two types of attention mechanisms for aggregating the query and support feature maps. The first is to refine the information of few-shot samples by extracting shared information between the support samples through attention. Second, each support sample is used as a class code to leverage the information by comparing similarities between each support feature and query features. Our proposed method is complementary to the previous methods, making it easy to plug and play for further improvement. We have evaluated our method on PASCAL VOC and COCO benchmarks, and the results verify the effectiveness of our method. In particular, the advantages of our method are maximized when there is more diversity among support data.
Density Estimation and Incremental Learning of Latent Vector for Generative Autoencoders
Feb 12, 2019
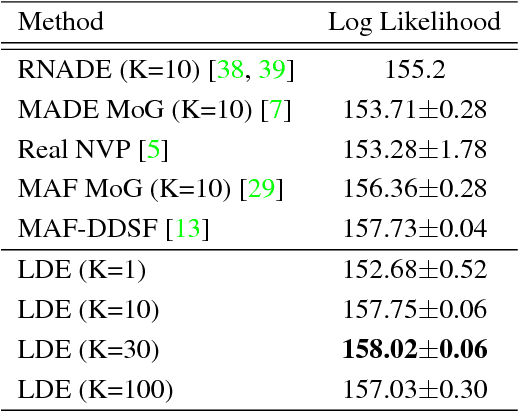
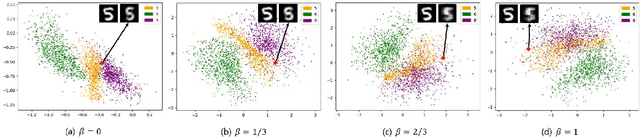
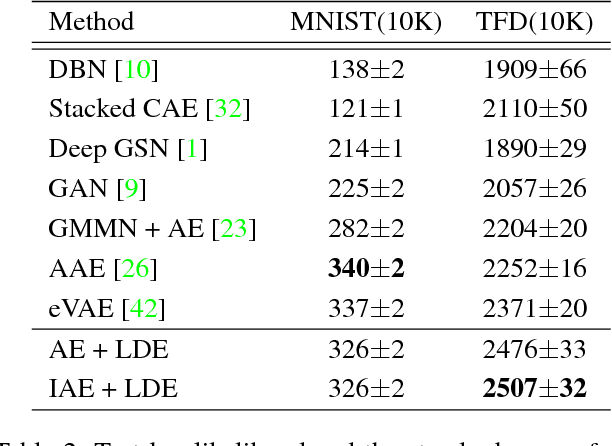
In this paper, we treat the image generation task using the autoencoder, a representative latent model. Unlike many studies regularizing the latent variable's distribution by assuming a manually specified prior, we approach the image generation task using an autoencoder by directly estimating the latent distribution. To do this, we introduce 'latent density estimator' which captures latent distribution explicitly and propose its structure. In addition, we propose an incremental learning strategy of latent variables so that the autoencoder learns important features of data by using the structural characteristics of under-complete autoencoder without an explicit regularization term in the objective function. Through experiments, we show the effectiveness of the proposed latent density estimator and the incremental learning strategy of latent variables. We also show that our generative model generates images with improved visual quality compared to previous generative models based on autoencoders.