 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPACT: Industrial Machine Perception via Acoustic Cognitive Transformer
Jul 09, 2025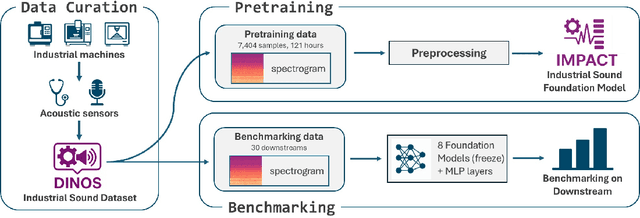
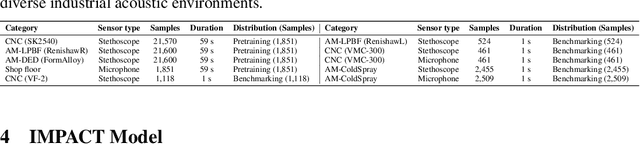

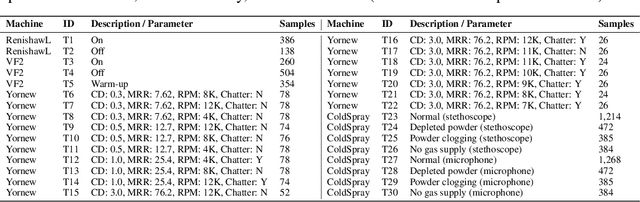
Acoustic signals from industrial machines offer valuable insights for anomaly detection, predictive maintenance, and operational efficiency enhancement. However, existing task-specific, supervised learning methods often scale poorly and fail to generalize across diverse industrial scenarios, whose acoustic characteristics are distinct from general audio. Furthermore, the scarcity of accessible, large-scale datasets and pretrained models tailored for industrial audio impedes community-driven research and benchmarking. To address these challenges, we introduce DINOS (Diverse INdustrial Operation Sounds), a large-scale open-access dataset. DINOS comprises over 74,149 audio samples (exceeding 1,093 hours) collected from various industrial acoustic scenarios. We also present IMPACT (Industrial Machine Perception via Acoustic Cognitive Transformer), a novel foundation model for industrial machine sound analysis. IMPACT is pretrained on DINOS in a self-supervised manner. By jointly optimizing utterance and frame-level losses, it captures both global semantics and fine-grained temporal structures. This makes its representations suitable for efficient fine-tuning on various industrial downstream tasks with minimal labeled data. Comprehensive benchmarking across 30 distinct downstream tasks (spanning four machine types) demonstrates that IMPACT outperforms existing models on 24 tasks, establishing its superior effectiveness and robustness, while providing a new performance benchmark for future research.
A Unified Debiasing Approach for Vision-Language Models across Modalities and Tasks
Oct 10, 2024

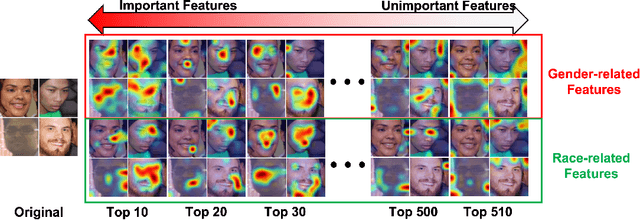

Recent advancements in Vision-Language Models (VLMs) have enabled complex multimodal tasks by processing text and image data simultaneously, significantly enhancing the field of artificial intelligence. However, these models often exhibit biases that can skew outputs towards societal stereotypes, thus necessitating debiasing strategies. Existing debiasing methods focus narrowly on specific modalities or tasks, and require extensive retraining. To address these limitations, this paper introduces Selective Feature Imputation for Debiasing (SFID), a novel methodology that integrates feature pruning and low confidence imputation (LCI) to effectively reduce biases in VLMs. SFID is versatile, maintaining the semantic integrity of outputs and costly effective by eliminating the need for retraining. Our experimental results demonstrate SFID's effectiveness across various VLMs tasks including zero-shot classification, text-to-image retrieval, image captioning, and text-to-image generation, by significantly reducing gender biases without compromising performance. This approach not only enhances the fairness of VLMs applications but also preserves their efficiency and utility across diverse scenarios.
Revealing and Utilizing In-group Favoritism for Graph-based Collaborative Filtering
Apr 23, 2024



When it comes to a personalized item recommendation system, It is essential to extract users' preferences and purchasing patterns. Assuming that users in the real world form a cluster and there is common favoritism in each cluster, in this work, we introduce Co-Clustering Wrapper (CCW). We compute co-clusters of users and items with co-clustering algorithms and add CF subnetworks for each cluster to extract the in-group favoritism. Combining the features from the networks, we obtain rich and unified information about users. We experimented real world datasets considering two aspects: Finding the number of groups divided according to in-group preference, and measuring the quantity of improvement of the performance.