 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effects of Adversarial Perturbations on Distribution Robustness
Jan 23, 2026Adversarial robustness refers to a model's ability to resist perturbation of inputs, while distribution robustness evaluates the performance of the model under data shifts. Although both aim to ensure reliable performance, prior work has revealed a tradeoff in distribution and adversarial robustness. Specifically, adversarial training might increase reliance on spurious features, which can harm distribution robustness, especially the performance on some underrepresented subgroups. We present a theoretical analysis of adversarial and distribution robustness that provides a tractable surrogate for per-step adversarial training by studying models trained on perturbed data. In addition to the tradeoff, our work further identified a nuanced phenomenon that $\ell_\infty$ perturbations on data with moderate bias can yield an increase in distribution robustness. Moreover, the gain in distribution robustness remains on highly skewed data when simplicity bias induces reliance on the core feature, characterized as greater feature separability. Our theoretical analysis extends the understanding of the tradeoff by highlighting the interplay of the tradeoff and the feature separability. Despite the tradeoff that persists in many cases, overlooking the role of feature separability may lead to misleading conclusions about robustness.
The Trojan in the Vocabulary: Stealthy Sabotage of LLM Composition
Dec 31, 2025The open-weight LLM ecosystem is increasingly defined by model composition techniques (such as weight merging, speculative decoding, and vocabulary expansion) that remix capabilities from diverse sources. A critical prerequisite for applying these methods across different model families is tokenizer transplant, which aligns incompatible vocabularies to a shared embedding space. We demonstrate that this essential interoperability step introduces a supply-chain vulnerability: we engineer a single "breaker token" that is functionally inert in a donor model yet reliably reconstructs into a high-salience malicious feature after transplant into a base model. By exploiting the geometry of coefficient reuse, our attack creates an asymmetric realizability gap that sabotages the base model's generation while leaving the donor's utility statistically indistinguishable from nominal behavior. We formalize this as a dual-objective optimization problem and instantiate the attack using a sparse solver. Empirically, the attack is training-free and achieves spectral mimicry to evade outlier detection, while demonstrating structural persistence against fine-tuning and weight merging, highlighting a hidden risk in the pipeline of modular AI composition. Code is available at https://github.com/xz-liu/tokenforge
Inland Waterway Object Detection in Multi-environment: Dataset and Approach
Apr 07, 2025The success of deep learning in intelligent ship visual perception relies heavily on rich image data. However, dedicated datasets for inland waterway vessels remain scarce, limiting the adaptability of visual perception systems in complex environments. Inland waterways, characterized by narrow channels, variable weather, and urban interference, pose significant challenges to object detection systems based on existing datasets. To address these issues, this paper introduces the Multi-environment Inland Waterway Vessel Dataset (MEIWVD), comprising 32,478 high-quality images from diverse scenarios, including sunny, rainy, foggy, and artificial lighting conditions. MEIWVD covers common vessel types in the Yangtze River Basin, emphasizing diversity, sample independence, environmental complexity, and multi-scale characteristics, making it a robust benchmark for vessel detection. Leveraging MEIWVD, this paper proposes a scene-guided image enhancement module to improve water surface images based on environmental conditions adaptively. Additionally, a parameter-limited dilated convolution enhances the representation of vessel features, while a multi-scale dilated residual fusion method integrates multi-scale features for better detection. Experiments show that MEIWVD provides a more rigorous benchmark for object detection algorithms, and the proposed methods significantly improve detector performance, especially in complex multi-environment scenarios.
SUV: Scalable Large Language Model Copyright Compliance with Regularized Selective Unlearning
Mar 29, 2025Large Language Models (LLMs) have transformed natural language processing by learning from massive datasets, yet this rapid progress has also drawn legal scrutiny, as the ability to unintentionally generate copyrighted content has already prompted several prominent lawsuits. In this work, we introduce SUV (Selective Unlearning for Verbatim data), a selective unlearning framework designed to prevent LLM from memorizing copyrighted content while preserving its overall utility. In detail, the proposed method constructs a dataset that captures instances of copyrighted infringement cases by the targeted LLM. With the dataset, we unlearn the content from the LLM by means of Direct Preference Optimization (DPO), which replaces the verbatim copyrighted content with plausible and coherent alternatives. Since DPO may hinder the LLM's performance in other unrelated tasks, we integrate gradient projection and Fisher information regularization to mitigate the degradation. We validate our approach using a large-scale dataset of 500 famous books (predominantly copyrighted works) and demonstrate that SUV significantly reduces verbatim memorization with negligible impact on the performance on unrelated tasks. Extensive experiments on both our dataset and public benchmarks confirm the scalability and efficacy of our approach, offering a promising solution for mitigating copyright risks in real-world LLM applications.
A Unified Debiasing Approach for Vision-Language Models across Modalities and Tasks
Oct 10, 2024

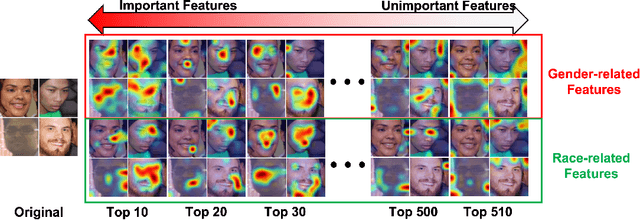

Recent advancements in Vision-Language Models (VLMs) have enabled complex multimodal tasks by processing text and image data simultaneously, significantly enhancing the field of artificial intelligence. However, these models often exhibit biases that can skew outputs towards societal stereotypes, thus necessitating debiasing strategies. Existing debiasing methods focus narrowly on specific modalities or tasks, and require extensive retraining. To address these limitations, this paper introduces Selective Feature Imputation for Debiasing (SFID), a novel methodology that integrates feature pruning and low confidence imputation (LCI) to effectively reduce biases in VLMs. SFID is versatile, maintaining the semantic integrity of outputs and costly effective by eliminating the need for retraining. Our experimental results demonstrate SFID's effectiveness across various VLMs tasks including zero-shot classification, text-to-image retrieval, image captioning, and text-to-image generation, by significantly reducing gender biases without compromising performance. This approach not only enhances the fairness of VLMs applications but also preserves their efficiency and utility across diverse scenarios.
SHIELD: Evaluation and Defense Strategies for Copyright Compliance in LLM Text Generation
Jun 18, 2024



Large Language Models (LLMs) have transformed machine learning but raised significant legal concerns due to their potential to produce text that infringes on copyrights, resulting in several high-profile lawsuits. The legal landscape is struggling to keep pace with these rapid advancements, with ongoing debates about whether generated text might plagiarize copyrighted materials. Current LLMs may infringe on copyrights or overly restrict non-copyrighted texts, leading to these challenges: (i) the need for a comprehensive evaluation benchmark to assess copyright compliance from multiple aspects; (ii) evaluating robustness against safeguard bypassing attacks; and (iii) developing effective defenses targeted against the generation of copyrighted text. To tackle these challenges, we introduce a curated dataset to evaluate methods, test attack strategies, and propose lightweight, real-time defenses to prevent the generation of copyrighted text, ensuring the safe and lawful use of LLMs. Our experiments demonstrate that current LLMs frequently output copyrighted text, and that jailbreaking attacks can significantly increase the volume of copyrighted output. Our proposed defense mechanisms significantly reduce the volume of copyrighted text generated by LLMs by effectively refusing malicious requests. Code is publicly available at https://github.com/xz-liu/SHIELD
Evaluating the Factuality of Large Language Models using Large-Scale Knowledge Graphs
Apr 01, 2024



The advent of Large Language Models (LLMs) has significantly transformed the AI landscape, enhancing machine learning and AI capabilities. Factuality issue is a critical concern for LLMs, as they may generate factually incorrect responses. In this paper, we propose GraphEval to evaluate an LLM's performance using a substantially large test dataset. Specifically, the test dataset is retrieved from a large knowledge graph with more than 10 million facts without expensive human efforts. Unlike conventional methods that evaluate LLMs based on generated responses, GraphEval streamlines the evaluation process by creating a judge model to estimate the correctness of the answers given by the LLM. Our experiments demonstrate that the judge model's factuality assessment aligns closely with the correctness of the LLM's generated outputs, while also substantially reducing evaluation costs. Besides, our findings offer valuable insights into LLM performance across different metrics and highlight the potential for future improvements in ensuring the factual integrity of LLM outputs. The code is publicly available at https://github.com/xz-liu/GraphEval.
Auto-Train-Once: Controller Network Guided Automatic Network Pruning from Scratch
Mar 21, 2024



Current techniques for deep neural network (DNN) pruning often involve intricate multi-step processes that require domain-specific expertise, making their widespread adoption challenging. To address the limitation, the Only-Train-Once (OTO) and OTOv2 are proposed to eliminate the need for additional fine-tuning steps by directly training and compressing a general DNN from scratch. Nevertheless, the static design of optimizers (in OTO) can lead to convergence issues of local optima. In this paper, we proposed the Auto-Train-Once (ATO), an innovative network pruning algorithm designed to automatically reduce the computational and storage costs of DNNs. During the model training phase, our approach not only trains the target model but also leverages a controller network as an architecture generator to guide the learning of target model weights. Furthermore, we developed a novel stochastic gradient algorithm that enhances the coordination between model training and controller network training, thereby improving pruning performance. We provide a comprehensive convergence analysis as well as extensive experiments, and the results show that our approach achieves state-of-the-art performance across various model architectures (including ResNet18, ResNet34, ResNet50, ResNet56, and MobileNetv2) on standard benchmark datasets (CIFAR-10, CIFAR-100, and ImageNet).
Learning the irreversible progression trajectory of Alzheimer's disease
Mar 10, 2024



Alzheimer's disease (AD) is a progressive and irreversible brain disorder that unfolds over the course of 30 years. Therefore, it is critical to capture the disease progression in an early stage such that intervention can be applied before the onset of symptoms. Machine learning (ML) models have been shown effective in predicting the onset of AD. Yet for subjects with follow-up visits, existing techniques for AD classification only aim for accurate group assignment, where the monotonically increasing risk across follow-up visits is usually ignored. Resulted fluctuating risk scores across visits violate the irreversibility of AD, hampering the trustworthiness of models and also providing little value to understanding the disease progression. To address this issue, we propose a novel regularization approach to predict AD longitudinally. Our technique aims to maintain the expected monotonicity of increasing disease risk during progression while preserving expressiveness. Specifically, we introduce a monotonicity constraint that encourages the model to predict disease risk in a consistent and ordered manner across follow-up visits. We evaluate our method using the longitudinal structural MRI and amyloid-PET imaging data from the Alzheimer's Disease Neuroimaging Initiative (ADNI). Our model outperforms existing techniques in capturing the progressiveness of disease risk, and at the same time preserves prediction accuracy.
To be Robust and to be Fair: Aligning Fairness with Robustness
Mar 31, 2023



Adversarial training has been shown to be reliable in improving robustness against adversarial samples. However, the problem of adversarial training in terms of fairness has not yet been properly studied, and the relationship between fairness and accuracy attack still remains unclear. Can we simultaneously improve robustness w.r.t. both fairness and accuracy? To tackle this topic, in this paper, we study the problem of adversarial training and adversarial attack w.r.t. both metrics. We propose a unified structure for fairness attack which brings together common notions in group fairness, and we theoretically prove the equivalence of fairness attack against different notions. Moreover, we show the alignment of fairness and accuracy attack, and theoretically demonstrate that robustness w.r.t. one metric benefits from robustness w.r.t. the other metric. Our study suggests a novel way to unify adversarial training and attack w.r.t. fairness and accuracy, and experimental results show that our proposed method achieves better performance in terms of robustness w.r.t. both metrics.