 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo be Robust and to be Fair: Aligning Fairness with Robustness
Mar 31, 2023



Adversarial training has been shown to be reliable in improving robustness against adversarial samples. However, the problem of adversarial training in terms of fairness has not yet been properly studied, and the relationship between fairness and accuracy attack still remains unclear. Can we simultaneously improve robustness w.r.t. both fairness and accuracy? To tackle this topic, in this paper, we study the problem of adversarial training and adversarial attack w.r.t. both metrics. We propose a unified structure for fairness attack which brings together common notions in group fairness, and we theoretically prove the equivalence of fairness attack against different notions. Moreover, we show the alignment of fairness and accuracy attack, and theoretically demonstrate that robustness w.r.t. one metric benefits from robustness w.r.t. the other metric. Our study suggests a novel way to unify adversarial training and attack w.r.t. fairness and accuracy, and experimental results show that our proposed method achieves better performance in terms of robustness w.r.t. both metrics.
FAST: Improving Controllability for Text Generation with Feedback Aware Self-Training
Oct 06, 2022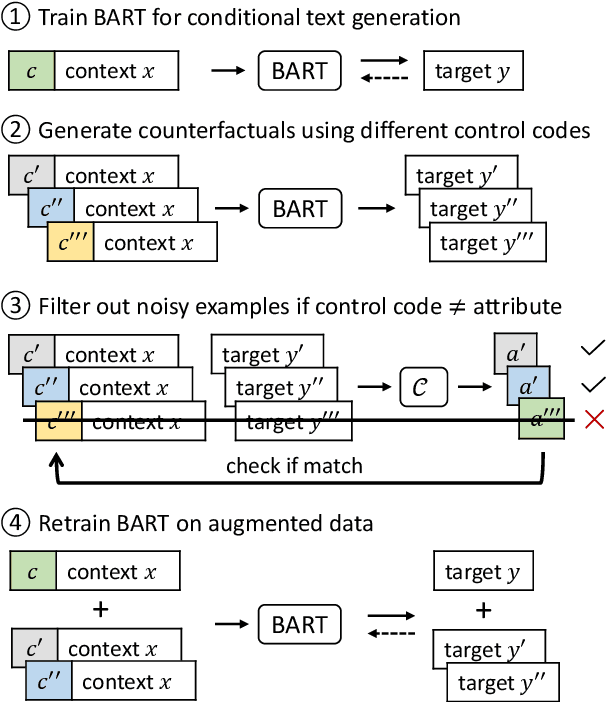
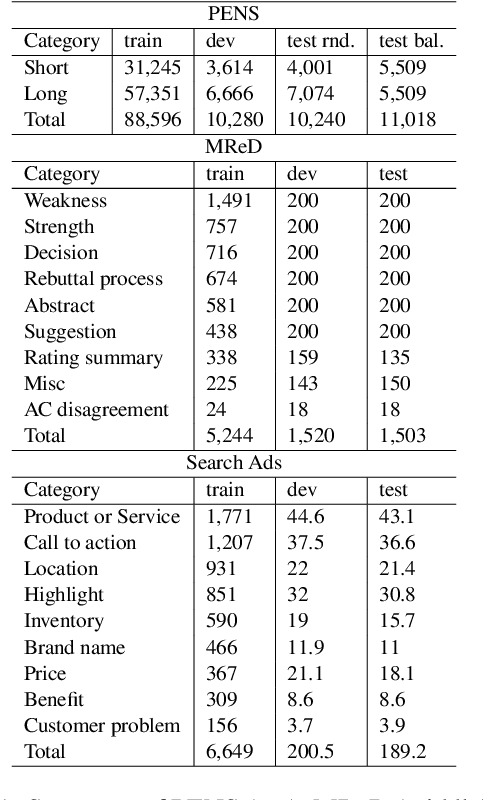
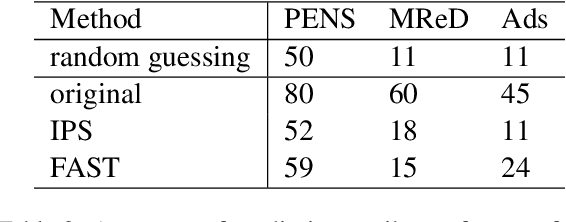

Controllable text generation systems often leverage control codes to direct various properties of the output like style and length. Inspired by recent work on causal inference for NLP, this paper reveals a previously overlooked flaw in these control code-based conditional text generation algorithms. Spurious correlations in the training data can lead models to incorrectly rely on parts of the input other than the control code for attribute selection, significantly undermining downstream generation quality and controllability. We demonstrate the severity of this issue with a series of case studies and then propose two simple techniques to reduce these correlations in training sets. The first technique is based on resampling the data according to an example's propensity towards each linguistic attribute (IPS). The second produces multiple counterfactual versions of each example and then uses an additional feedback mechanism to remove noisy examples (feedback aware self-training, FAST). We evaluate on 3 tasks -- news headline, meta review, and search ads generation -- and demonstrate that FAST can significantly improve the controllability and language quality of generated outputs when compared to state-of-the-art controllable text generation approaches.
DeepGen: Diverse Search Ad Generation and Real-Time Customization
Aug 06, 2022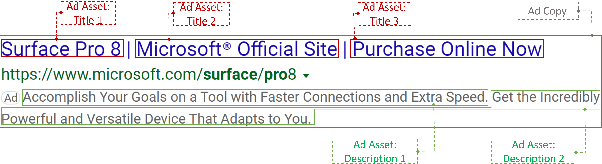


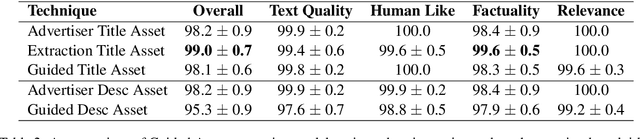
We present DeepGen, a system deployed at web scale for automatically creating sponsored search advertisements (ads) for BingAds customers. We leverage state-of-the-art natural language generation (NLG) models to generate fluent ads from advertiser's web pages in an abstractive fashion and solve practical issues such as factuality and inference speed. In addition, our system creates a customized ad in real-time in response to the user's search query, therefore highlighting different aspects of the same product based on what the user is looking for. To achieve this, our system generates a diverse choice of smaller pieces of the ad ahead of time and, at query time, selects the most relevant ones to be stitched into a complete ad. We improve generation diversity by training a controllable NLG model to generate multiple ads for the same web page highlighting different selling points. Our system design further improves diversity horizontally by first running an ensemble of generation models trained with different objectives and then using a diversity sampling algorithm to pick a diverse subset of generation results for online selection. Experimental results show the effectiveness of our proposed system design. Our system is currently deployed in production, serving ${\sim}4\%$ of global ads served in Bing.
Automatic Construction of Enterprise Knowledge Base
Jun 29, 2021


In this paper, we present an automatic knowledge base construction system from large scale enterprise documents with minimal efforts of human intervention. In the design and deployment of such a knowledge mining system for enterprise, we faced several challenges including data distributional shift, performance evaluation, compliance requirements and other practical issues. We leveraged state-of-the-art deep learning models to extract information (named entities and definitions) at per document level, then further applied classical machine learning techniques to process global statistical information to improve the knowledge base. Experimental results are reported on actual enterprise documents. This system is currently serving as part of a Microsoft 365 service.
An Ontology-driven Framework for Supporting Complex Decision Process
Jul 15, 2011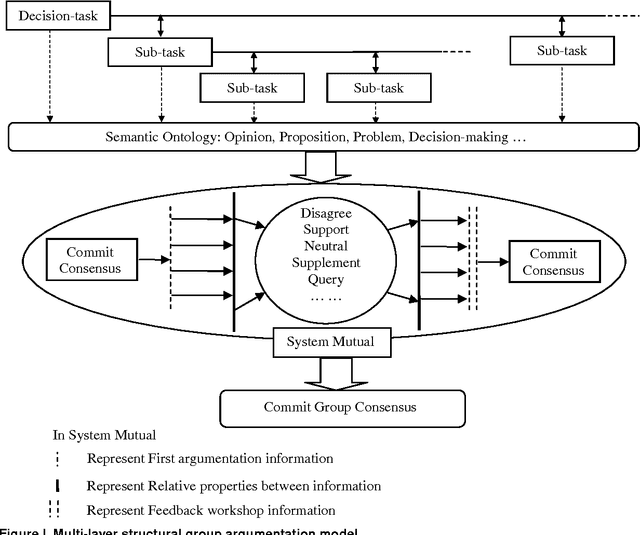
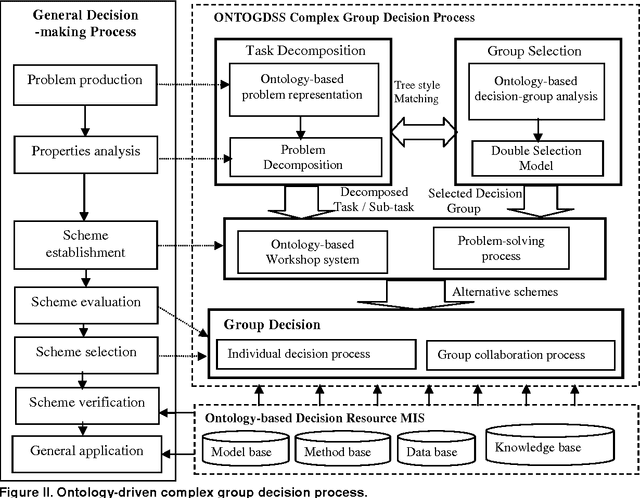
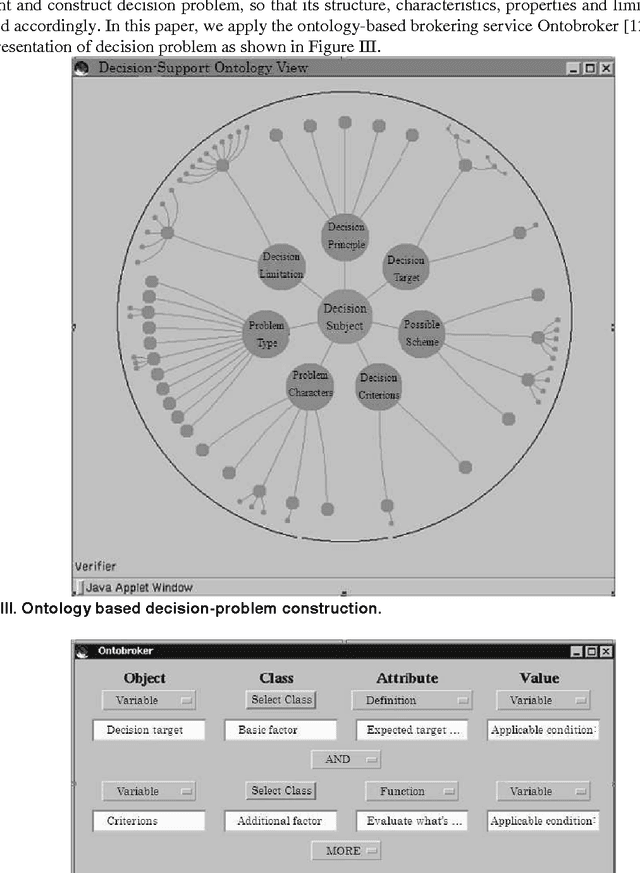
The study proposes a framework of ONTOlogy-based Group Decision Support System (ONTOGDSS) for decision process which exhibits the complex structure of decision-problem and decision-group. It is capable of reducing the complexity of problem structure and group relations. The system allows decision makers to participate in group decision-making through the web environment, via the ontology relation. It facilitates the management of decision process as a whole, from criteria generation, alternative evaluation, and opinion interaction to decision aggregation. The embedded ontology structure in ONTOGDSS provides the important formal description features to facilitate decision analysis and verification. It examines the software architecture, the selection methods, the decision path, etc. Finally, the ontology application of this system is illustrated with specific real case to demonstrate its potentials towards decision-making development.
A Novel Multicriteria Group Decision Making Approach With Intuitionistic Fuzzy SIR Method
Jul 06, 2011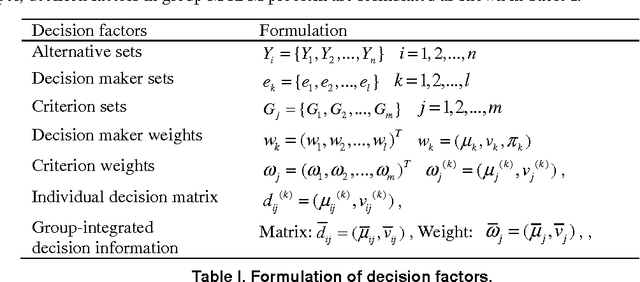
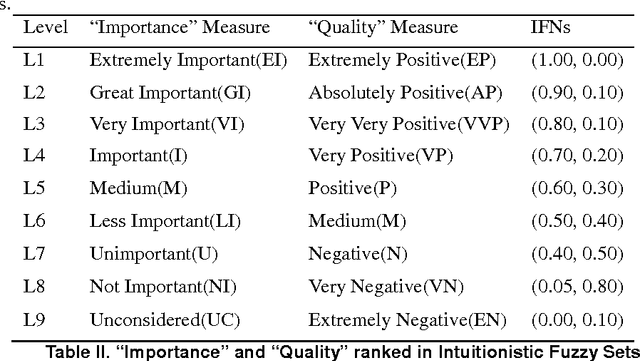
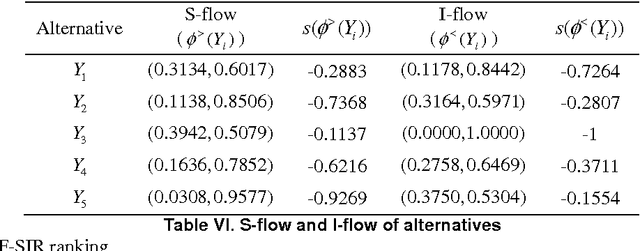
The superiority and inferiority ranking (SIR) method is a generation of the well-known PROMETHEE method, which can be more efficient to deal with multi-criterion decision making (MCDM) problem. Intuitionistic fuzzy sets (IFSs), as an important extension of fuzzy sets (IFs), include both membership functions and non-membership functions and can be used to, more precisely describe uncertain information. In real world, decision situations are usually under uncertain environment and involve multiple individuals who have their own points of view on handing of decision problems. In order to solve uncertainty group MCDM problem, we propose a novel intuitionistic fuzzy SIR method in this paper. This approach uses intuitionistic fuzzy aggregation operators and SIR ranking methods to handle uncertain information; integrate individual opinions into group opinions; make decisions on multiple-criterion; and finally structure a specific decision map. The proposed approach is illustrated in a simulation of group decision making problem related to supply chain management.
Class-based Rough Approximation with Dominance Principle
Jul 05, 2011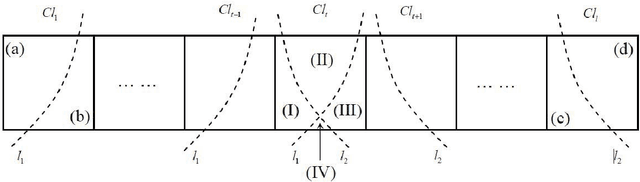
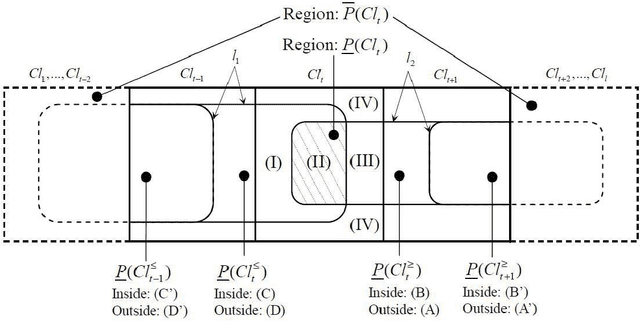

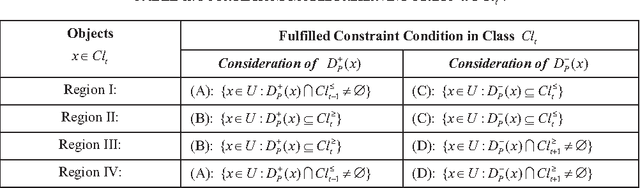
Dominance-based Rough Set Approach (DRSA), as the extension of Pawlak's Rough Set theory, is effective and fundamentally important in Multiple Criteria Decision Analysis (MCDA). In previous DRSA models, the definitions of the upper and lower approximations are preserving the class unions rather than the singleton class. In this paper, we propose a new Class-based Rough Approximation with respect to a series of previous DRSA models, including Classical DRSA model, VC-DRSA model and VP-DRSA model. In addition, the new class-based reducts are investigated.
Towards a Reliable Framework of Uncertainty-Based Group Decision Support System
Jul 01, 2011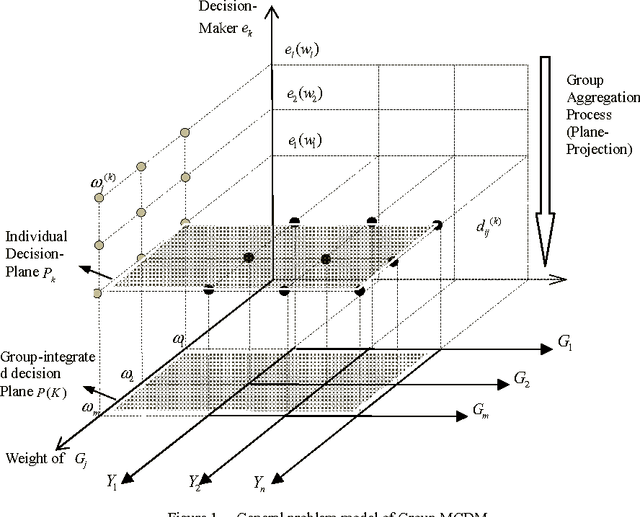
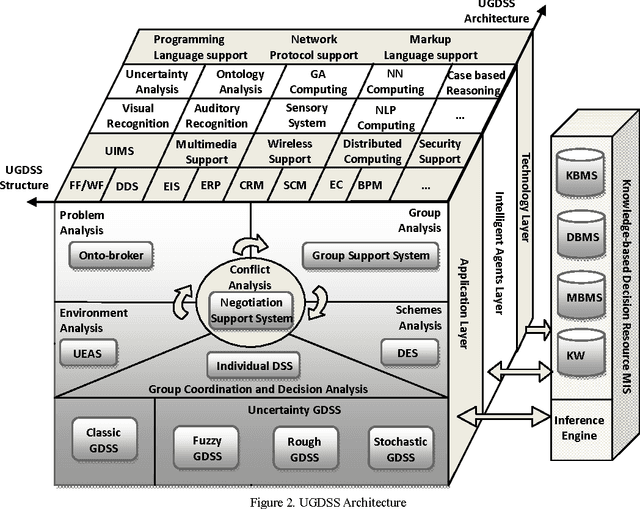
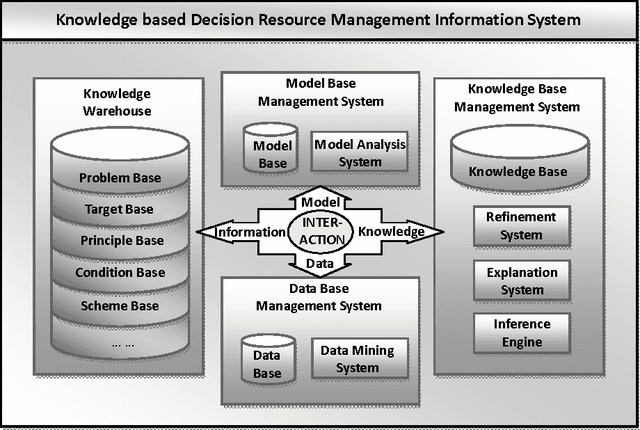

This study proposes a framework of Uncertainty-based Group Decision Support System (UGDSS). It provides a platform for multiple criteria decision analysis in six aspects including (1) decision environment, (2) decision problem, (3) decision group, (4) decision conflict, (5) decision schemes and (6) group negotiation. Based on multiple artificial intelligent technologies, this framework provides reliable support for the comprehensive manipulation of applications and advanced decision approaches through the design of an integrated multi-agents architecture.