 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace-Time-Frequency Synthetic Integrated Sensing and Communication Networks
Nov 19, 2025Integrated sensing and communication (ISAC) promises high spectral and power efficiencies by sharing waveforms, spectrum, and hardware across sensing and data links. Yet commercial cellular networks struggle to deliver fine angular, range, and Doppler resolution due to limited aperture, bandwidth, and coherent observation time. In this paper, we propose a space-time-frequency synthetic ISAC architecture that fuses observations from distributed transmitters and receivers across time intervals and frequency bands. We develop a unified signal model for multistatic and monostatic configurations, derive Cramer-Rao lower bounds (CRLBs) for the estimations of position and velocity. The analysis shows how spatial diversity, multiband operation, and observation scheduling impact the Fisher information. We also compare the estimation performance between a concentrated maximum likelihood estimator (MLE) and a two stage information fusion (TSIF) method that first estimates per-path delay and radial speed and then fuses them by solving a weighted nonlinear least-squares problem via the Gauss-Newton algorithm. Numerical results show that MLE approaches the CRLB in the high signal-to-noise ratio (SNR) regime, while the two stage method remains competitive at moderate to high SNR but degrades at low SNR. A central finding is that fully synthesized network processing is essential, as estimations by individual base stations (BSs) followed by fusion are consistently inferior and unstable at low SNR. This framework offers a practical guidance for upgrading existing communication infrastructure into dense sensing networks.
Towards Privacy-Preserving and Heterogeneity-aware Split Federated Learning via Probabilistic Masking
Sep 18, 2025Split Federated Learning (SFL) has emerged as an efficient alternative to traditional Federated Learning (FL) by reducing client-side computation through model partitioning. However, exchanging of intermediate activations and model updates introduces significant privacy risks, especially from data reconstruction attacks that recover original inputs from intermediate representations. Existing defenses using noise injection often degrade model performance. To overcome these challenges, we present PM-SFL, a scalable and privacy-preserving SFL framework that incorporates Probabilistic Mask training to add structured randomness without relying on explicit noise. This mitigates data reconstruction risks while maintaining model utility. To address data heterogeneity, PM-SFL employs personalized mask learning that tailors submodel structures to each client's local data. For system heterogeneity, we introduce a layer-wise knowledge compensation mechanism, enabling clients with varying resources to participate effectively under adaptive model splitting. Theoretical analysis confirms its privacy protection, and experiments on image and wireless sensing tasks demonstrate that PM-SFL consistently improves accuracy, communication efficiency, and robustness to privacy attacks, with particularly strong performance under data and system heterogeneity.
OTFS-ISAC System with Sub-Nyquist ADC Sampling Rate
Feb 07, 2025



Integrated sensing and communication (ISAC) has emerged as a pivotal technology for next-generation wireless communication and radar systems, enabling high-resolution sensing and high-throughput communication with shared spectrum and hardware. However, achieving a fine radar resolution often requires high-rate analog-to-digital converters (ADCs) and substantial storage, making it both expensive and impractical for many commercial applications. To address these challenges, this paper proposes an orthogonal time frequency space (OTFS)-based ISAC architecture that operates at reduced ADC sampling rates, yet preserves accurate radar estimation and supports simultaneous communication. The proposed architecture introduces pilot symbols directly in the delay-Doppler (DD) domain to leverage the transformation mapping between the DD and time-frequency (TF) domains to keep selected subcarriers active while others are inactive, allowing the radar receiver to exploit under-sampling aliasing and recover the original DD signal at much lower sampling rates. To further enhance the radar accuracy, we develop an iterative interference estimation and cancellation algorithm that mitigates data symbol interference. We propose a code-based spreading technique that distributes data across the DD domain to preserve the maximum unambiguous radar sensing range. For communication, we implement a complete transceiver pipeline optimized for reduced sampling rate system, including synchronization, channel estimation, and iterative data detection. Experimental results from a software-defined radio (SDR)-based testbed confirm that our method substantially lowers the required sampling rate without sacrificing radar sensing performance and ensures reliable communication.
FIARSE: Model-Heterogeneous Federated Learning via Importance-Aware Submodel Extraction
Jul 28, 2024
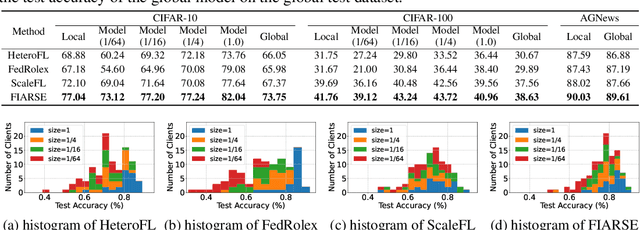
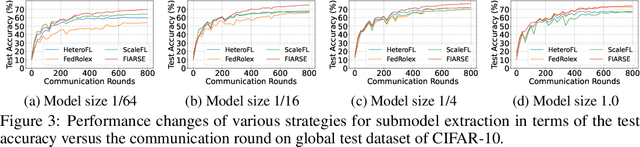

In federated learning (FL), accommodating clients' varied computational capacities poses a challenge, often limiting the participation of those with constrained resources in global model training. To address this issue, the concept of model heterogeneity through submodel extraction has emerged, offering a tailored solution that aligns the model's complexity with each client's computational capacity. In this work, we propose Federated Importance-Aware Submodel Extraction (FIARSE), a novel approach that dynamically adjusts submodels based on the importance of model parameters, thereby overcoming the limitations of previous static and dynamic submodel extraction methods. Compared to existing works, the proposed method offers a theoretical foundation for the submodel extraction and eliminates the need for additional information beyond the model parameters themselves to determine parameter importance, significantly reducing the overhead on clients. Extensive experiments are conducted on various datasets to showcase superior performance of the proposed FIARSE.
Towards Poisoning Fair Representations
Sep 28, 2023Fair machine learning seeks to mitigate model prediction bias against certain demographic subgroups such as elder and female. Recently, fair representation learning (FRL) trained by deep neural networks has demonstrated superior performance, whereby representations containing no demographic information are inferred from the data and then used as the input to classification or other downstream tasks. Despite the development of FRL methods, their vulnerability under data poisoning attack, a popular protocol to benchmark model robustness under adversarial scenarios, is under-explored. Data poisoning attacks have been developed for classical fair machine learning methods which incorporate fairness constraints into shallow-model classifiers. Nonetheless, these attacks fall short in FRL due to notably different fairness goals and model architectures. This work proposes the first data poisoning framework attacking FRL. We induce the model to output unfair representations that contain as much demographic information as possible by injecting carefully crafted poisoning samples into the training data. This attack entails a prohibitive bilevel optimization, wherefore an effective approximated solution is proposed. A theoretical analysis on the needed number of poisoning samples is derived and sheds light on defending against the attack. Experiments on benchmark fairness datasets and state-of-the-art fair representation learning models demonstrate the superiority of our attack.
Peer-to-Peer Federated Continual Learning for Naturalistic Driving Action Recognition
Apr 14, 2023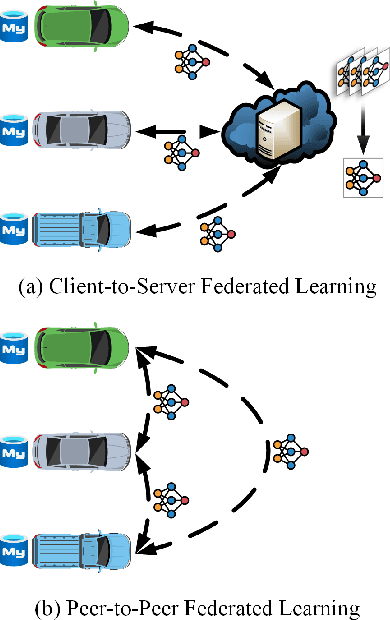
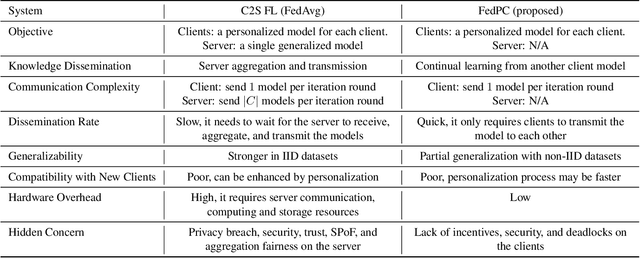
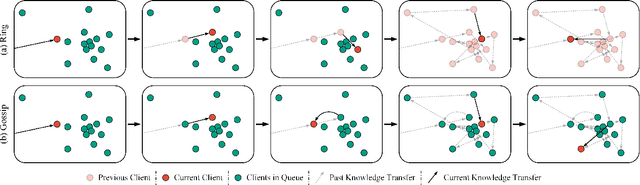

Naturalistic driving action recognition (NDAR) has proven to be an effective method for detecting driver distraction and reducing the risk of traffic accidents. However, the intrusive design of in-cabin cameras raises concerns about driver privacy. To address this issue, we propose a novel peer-to-peer (P2P) federated learning (FL) framework with continual learning, namely FedPC, which ensures privacy and enhances learning efficiency while reducing communication, computational, and storage overheads. Our framework focuses on addressing the clients' objectives within a serverless FL framework, with the goal of delivering personalized and accurate NDAR models. We demonstrate and evaluate the performance of FedPC on two real-world NDAR datasets, including the State Farm Distracted Driver Detection and Track 3 NDAR dataset in the 2023 AICity Challenge. The results of our experiments highlight the strong competitiveness of FedPC compared to the conventional client-to-server (C2S) FLs in terms of performance, knowledge dissemination rate, and compatibility with new clients.
SimFair: A Unified Framework for Fairness-Aware Multi-Label Classification
Feb 22, 2023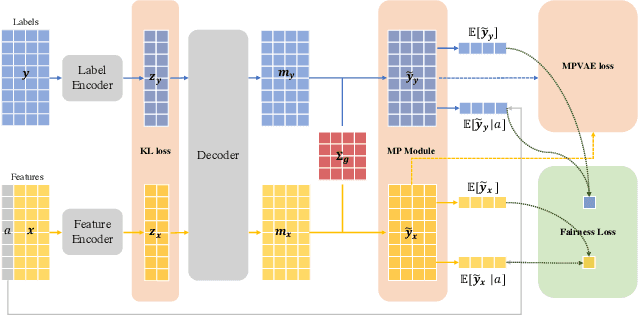
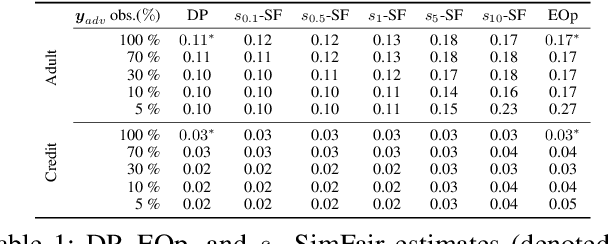
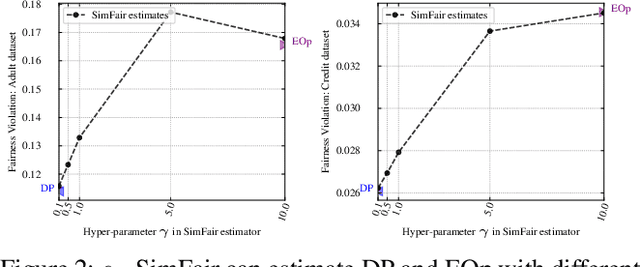

Recent years have witnessed increasing concerns towards unfair decisions made by machine learning algorithms. To improve fairness in model decisions, various fairness notions have been proposed and many fairness-aware methods are developed. However, most of existing definitions and methods focus only on single-label classification. Fairness for multi-label classification, where each instance is associated with more than one labels, is still yet to establish. To fill this gap, we study fairness-aware multi-label classification in this paper. We start by extending Demographic Parity (DP) and Equalized Opportunity (EOp), two popular fairness notions, to multi-label classification scenarios. Through a systematic study, we show that on multi-label data, because of unevenly distributed labels, EOp usually fails to construct a reliable estimate on labels with few instances. We then propose a new framework named Similarity $s$-induced Fairness ($s_\gamma$-SimFair). This new framework utilizes data that have similar labels when estimating fairness on a particular label group for better stability, and can unify DP and EOp. Theoretical analysis and experimental results on real-world datasets together demonstrate the advantage of over existing methods $s_\gamma$-SimFair on multi-label classification tasks.
Federated Transfer-Ordered-Personalized Learning for Driver Monitoring Application
Jan 12, 2023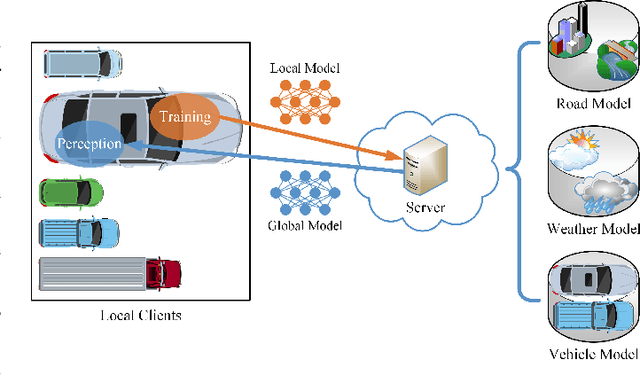
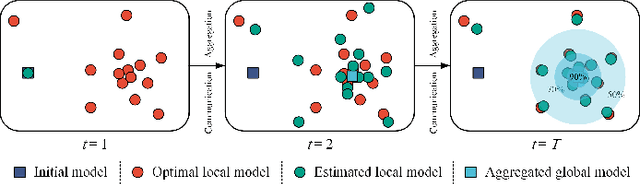
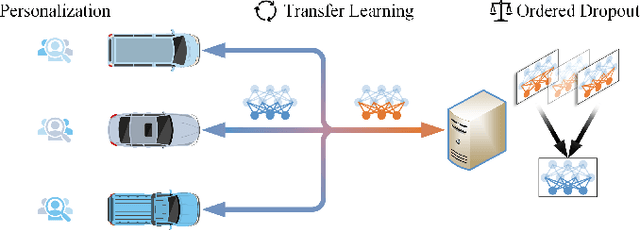

Federated learning (FL) shines through in the internet of things (IoT) with its ability to realize collaborative learning and improve learning efficiency by sharing client model parameters trained on local data. Although FL has been successfully applied to various domains, including driver monitoring application (DMA) on the internet of vehicles (IoV), its usages still face some open issues, such as data and system heterogeneity, large-scale parallelism communication resources, malicious attacks, and data poisoning. This paper proposes a federated transfer-ordered-personalized learning (FedTOP) framework to address the above problems and test on two real-world datasets with and without system heterogeneity. The performance of the three extensions, transfer, ordered, and personalized, is compared by an ablation study and achieves 92.32% and 95.96% accuracy on the test clients of two datasets, respectively. Compared to the baseline, there is a 462% improvement in accuracy and a 37.46% reduction in communication resource consumption. The results demonstrate that the proposed FedTOP can be used as a highly accurate, streamlined, privacy-preserving, cybersecurity-oriented, personalized framework for DMA.
Towards Data Poisoning Attack against Knowledge Graph Embedding
Apr 26, 2019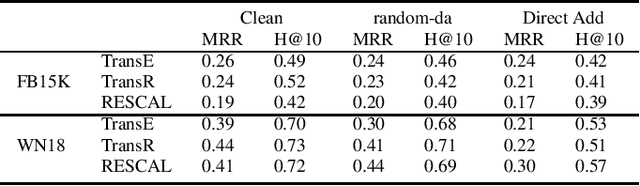
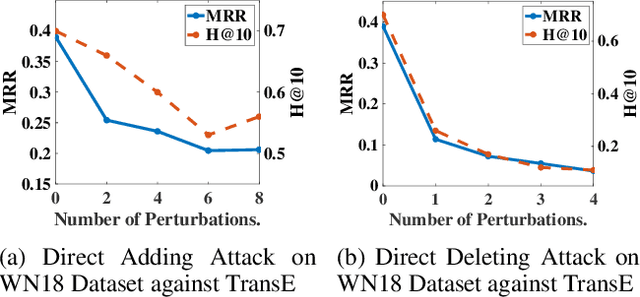
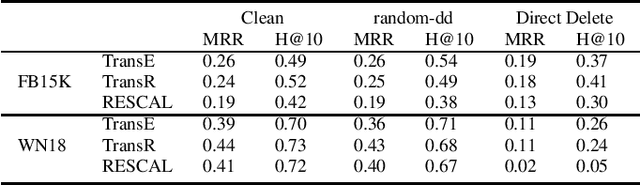
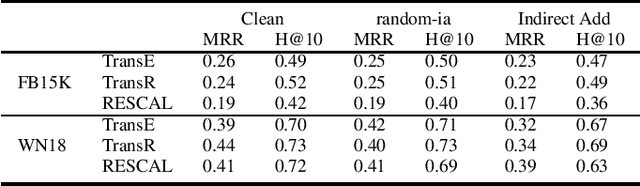
Knowledge graph embedding (KGE) is a technique for learning continuous embeddings for entities and relations in the knowledge graph.Due to its benefit to a variety of downstream tasks such as knowledge graph completion, question answering and recommendation, KGE has gained significant attention recently. Despite its effectiveness in a benign environment, KGE' robustness to adversarial attacks is not well-studied. Existing attack methods on graph data cannot be directly applied to attack the embeddings of knowledge graph due to its heterogeneity. To fill this gap, we propose a collection of data poisoning attack strategies, which can effectively manipulate the plausibility of arbitrary targeted facts in a knowledge graph by adding or deleting facts on the graph. The effectiveness and efficiency of the proposed attack strategies are verified by extensive evaluations on two widely-used benchmarks.
STFNets: Learning Sensing Signals from the Time-Frequency Perspective with Short-Time Fourier Neural Networks
Feb 21, 2019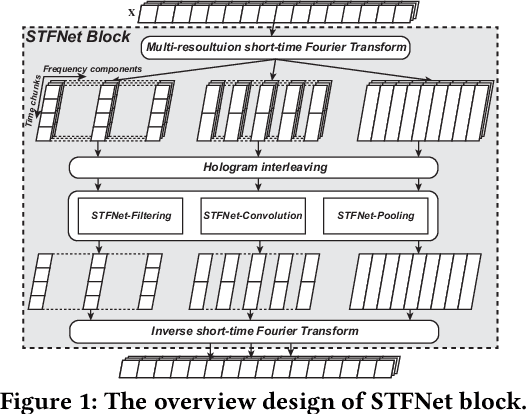
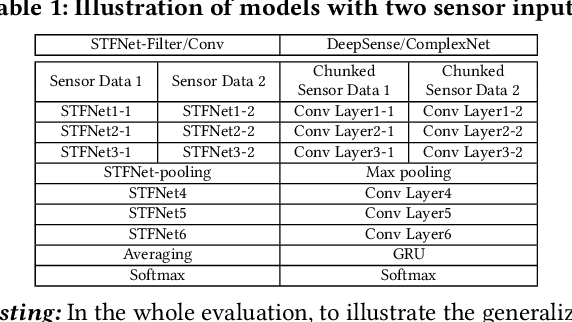
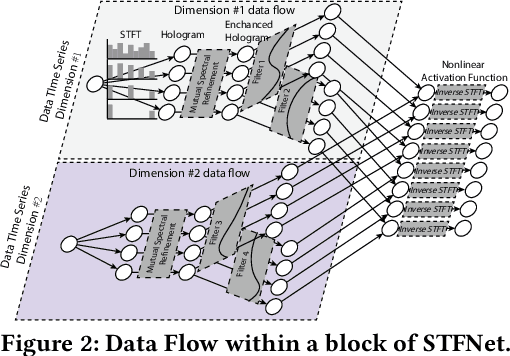
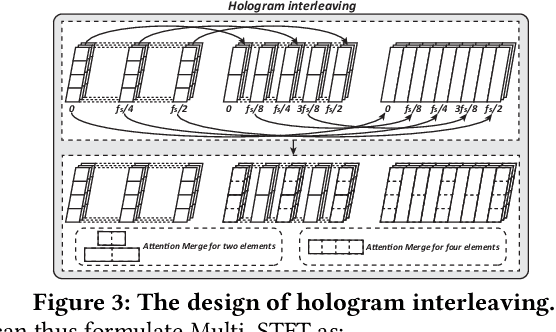
Recent advances in deep learning motivate the use of deep neural networks in Internet-of-Things (IoT) applications. These networks are modelled after signal processing in the human brain, thereby leading to significant advantages at perceptual tasks such as vision and speech recognition. IoT applications, however, often measure physical phenomena, where the underlying physics (such as inertia, wireless signal propagation, or the natural frequency of oscillation) are fundamentally a function of signal frequencies, offering better features in the frequency domain. This observation leads to a fundamental question: For IoT applications, can one develop a new brand of neural network structures that synthesize features inspired not only by the biology of human perception but also by the fundamental nature of physics? Hence, in this paper, instead of using conventional building blocks (e.g., convolutional and recurrent layers), we propose a new foundational neural network building block, the Short-Time Fourier Neural Network (STFNet). It integrates a widely-used time-frequency analysis method, the Short-Time Fourier Transform, into data processing to learn features directly in the frequency domain, where the physics of underlying phenomena leave better foot-prints. STFNets bring additional flexibility to time-frequency analysis by offering novel nonlinear learnable operations that are spectral-compatible. Moreover, STFNets show that transforming signals to a domain that is more connected to the underlying physics greatly simplifies the learning process. We demonstrate the effectiveness of STFNets with extensive experiments. STFNets significantly outperform the state-of-the-art deep learning models in all experiments. A STFNet, therefore, demonstrates superior capability as the fundamental building block of deep neural networks for IoT applications for various sensor inputs.