 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Optimal Bayesian Inference for Structural Missingness
Jan 27, 2026Structural missingness breaks 'just impute and train': values can be undefined by causal or logical constraints, and the mask may depend on observed variables, unobserved variables (MNAR), and other missingness indicators. It simultaneously brings (i) a catch-22 situation with causal loop, prediction needs the missing features, yet inferring them depends on the missingness mechanism, (ii) under MNAR, the unseen are different, the missing part can come from a shifted distribution, and (iii) plug-in imputation, a single fill-in can lock in uncertainty and yield overconfident, biased decisions. In the Bayesian view, prediction via the posterior predictive distribution integrates over the full model posterior uncertainty, rather than relying on a single point estimate. This framework decouples (i) learning an in-model missing-value posterior from (ii) label prediction by optimizing the predictive posterior distribution, enabling posterior integration. This decoupling yields an in-model almost-free-lunch: once the posterior is learned, prediction is plug-and-play while preserving uncertainty propagation. It achieves SOTA on 43 classification and 15 imputation benchmarks, with finite-sample near Bayes-optimality guarantees under our SCM prior.
Towards Poisoning Fair Representations
Sep 28, 2023Fair machine learning seeks to mitigate model prediction bias against certain demographic subgroups such as elder and female. Recently, fair representation learning (FRL) trained by deep neural networks has demonstrated superior performance, whereby representations containing no demographic information are inferred from the data and then used as the input to classification or other downstream tasks. Despite the development of FRL methods, their vulnerability under data poisoning attack, a popular protocol to benchmark model robustness under adversarial scenarios, is under-explored. Data poisoning attacks have been developed for classical fair machine learning methods which incorporate fairness constraints into shallow-model classifiers. Nonetheless, these attacks fall short in FRL due to notably different fairness goals and model architectures. This work proposes the first data poisoning framework attacking FRL. We induce the model to output unfair representations that contain as much demographic information as possible by injecting carefully crafted poisoning samples into the training data. This attack entails a prohibitive bilevel optimization, wherefore an effective approximated solution is proposed. A theoretical analysis on the needed number of poisoning samples is derived and sheds light on defending against the attack. Experiments on benchmark fairness datasets and state-of-the-art fair representation learning models demonstrate the superiority of our attack.
Towards Controllable Diffusion Models via Reward-Guided Exploration
Apr 14, 2023



By formulating data samples' formation as a Markov denoising process, diffusion models achieve state-of-the-art performances in a collection of tasks. Recently, many variants of diffusion models have been proposed to enable controlled sample generation. Most of these existing methods either formulate the controlling information as an input (i.e.,: conditional representation) for the noise approximator, or introduce a pre-trained classifier in the test-phase to guide the Langevin dynamic towards the conditional goal. However, the former line of methods only work when the controlling information can be formulated as conditional representations, while the latter requires the pre-trained guidance classifier to be differentiable. In this paper, we propose a novel framework named RGDM (Reward-Guided Diffusion Model) that guides the training-phase of diffusion models via reinforcement learning (RL). The proposed training framework bridges the objective of weighted log-likelihood and maximum entropy RL, which enables calculating policy gradients via samples from a pay-off distribution proportional to exponential scaled rewards, rather than from policies themselves. Such a framework alleviates the high gradient variances and enables diffusion models to explore for highly rewarded samples in the reverse process. Experiments on 3D shape and molecule generation tasks show significant improvements over existing conditional diffusion models.
ImDrug: A Benchmark for Deep Imbalanced Learning in AI-aided Drug Discovery
Sep 16, 2022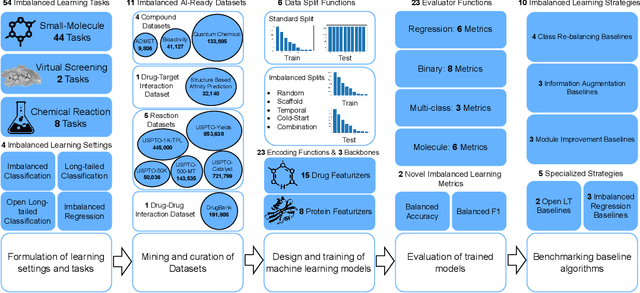

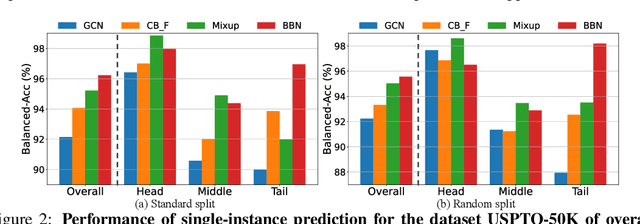
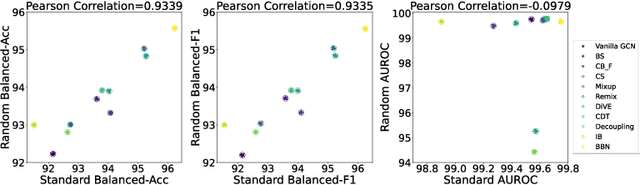
The last decade has witnessed a prosperous development of computational methods and dataset curation for AI-aided drug discovery (AIDD). However, real-world pharmaceutical datasets often exhibit highly imbalanced distribution, which is largely overlooked by the current literature but may severely compromise the fairness and generalization of machine learning applications. Motivated by this observation, we introduce ImDrug, a comprehensive benchmark with an open-source Python library which consists of 4 imbalance settings, 11 AI-ready datasets, 54 learning tasks and 16 baseline algorithms tailored for imbalanced learning. It provides an accessible and customizable testbed for problems and solutions spanning a broad spectrum of the drug discovery pipeline such as molecular modeling, drug-target interaction and retrosynthesis. We conduct extensive empirical studies with novel evaluation metrics, to demonstrate that the existing algorithms fall short of solving medicinal and pharmaceutical challenges in the data imbalance scenario. We believe that ImDrug opens up avenues for future research and development, on real-world challenges at the intersection of AIDD and deep imbalanced learning.
MDM: Molecular Diffusion Model for 3D Molecule Generation
Sep 13, 2022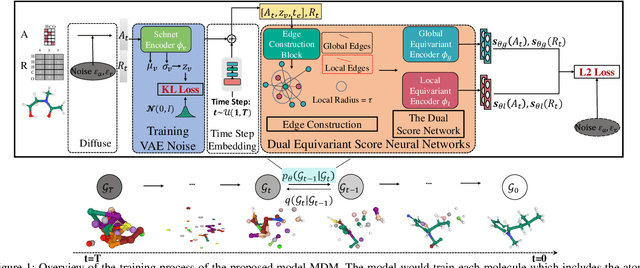
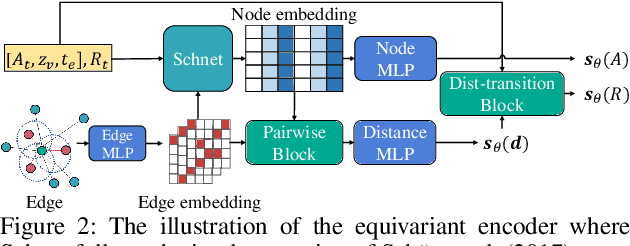
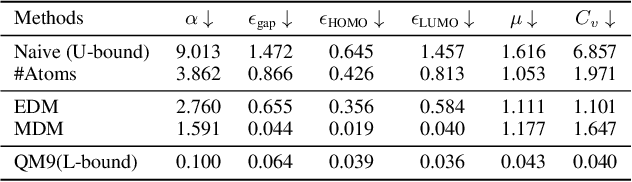
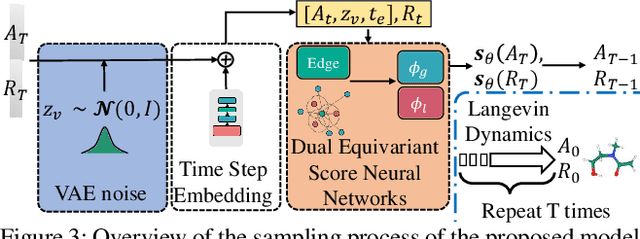
Molecule generation, especially generating 3D molecular geometries from scratch (i.e., 3D \textit{de novo} generation), has become a fundamental task in drug designs. Existing diffusion-based 3D molecule generation methods could suffer from unsatisfactory performances, especially when generating large molecules. At the same time, the generated molecules lack enough diversity. This paper proposes a novel diffusion model to address those two challenges. First, interatomic relations are not in molecules' 3D point cloud representations. Thus, it is difficult for existing generative models to capture the potential interatomic forces and abundant local constraints. To tackle this challenge, we propose to augment the potential interatomic forces and further involve dual equivariant encoders to encode interatomic forces of different strengths. Second, existing diffusion-based models essentially shift elements in geometry along the gradient of data density. Such a process lacks enough exploration in the intermediate steps of the Langevin dynamics. To address this issue, we introduce a distributional controlling variable in each diffusion/reverse step to enforce thorough explorations and further improve generation diversity. Extensive experiments on multiple benchmarks demonstrate that the proposed model significantly outperforms existing methods for both unconditional and conditional generation tasks. We also conduct case studies to help understand the physicochemical properties of the generated molecules.
A Survey of Trustworthy Graph Learning: Reliability, Explainability, and Privacy Protection
May 23, 2022



Deep graph learning has achieved remarkable progresses in both business and scientific areas ranging from finance and e-commerce, to drug and advanced material discovery. Despite these progresses, how to ensure various deep graph learning algorithms behave in a socially responsible manner and meet regulatory compliance requirements becomes an emerging problem, especially in risk-sensitive domains. Trustworthy graph learning (TwGL) aims to solve the above problems from a technical viewpoint. In contrast to conventional graph learning research which mainly cares about model performance, TwGL considers various reliability and safety aspects of the graph learning framework including but not limited to robustness, explainability, and privacy. In this survey, we provide a comprehensive review of recent leading approaches in the TwGL field from three dimensions, namely, reliability, explainability, and privacy protection. We give a general categorization for existing work and review typical work for each category. To give further insights for TwGL research, we provide a unified view to inspect previous works and build the connection between them. We also point out some important open problems remaining to be solved in the future developments of TwGL.
Towards Data Poisoning Attack against Knowledge Graph Embedding
Apr 26, 2019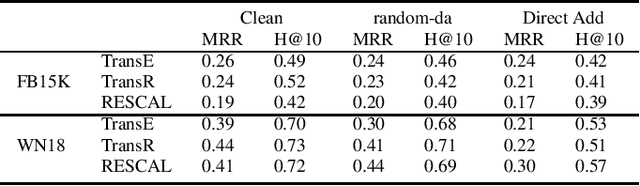
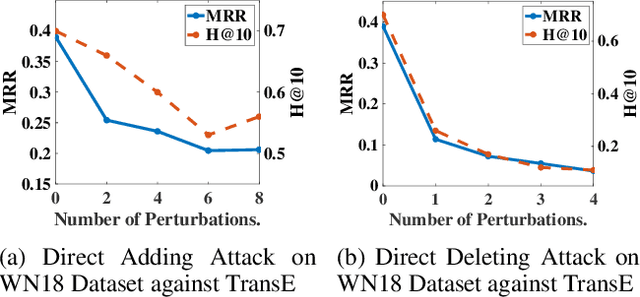
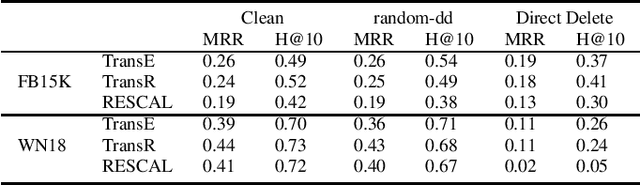
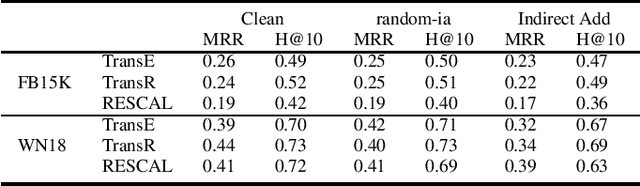
Knowledge graph embedding (KGE) is a technique for learning continuous embeddings for entities and relations in the knowledge graph.Due to its benefit to a variety of downstream tasks such as knowledge graph completion, question answering and recommendation, KGE has gained significant attention recently. Despite its effectiveness in a benign environment, KGE' robustness to adversarial attacks is not well-studied. Existing attack methods on graph data cannot be directly applied to attack the embeddings of knowledge graph due to its heterogeneity. To fill this gap, we propose a collection of data poisoning attack strategies, which can effectively manipulate the plausibility of arbitrary targeted facts in a knowledge graph by adding or deleting facts on the graph. The effectiveness and efficiency of the proposed attack strategies are verified by extensive evaluations on two widely-used benchmarks.