 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: A Motif-based Autoregressive Model for Retrosynthesis Prediction
Sep 27, 2022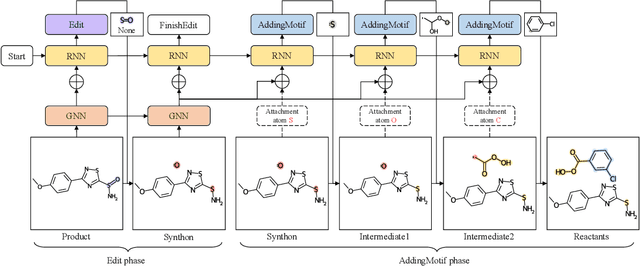
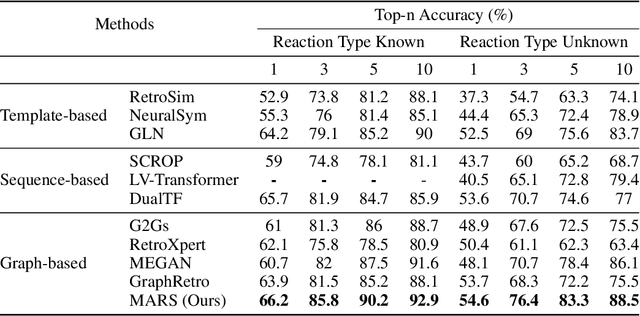
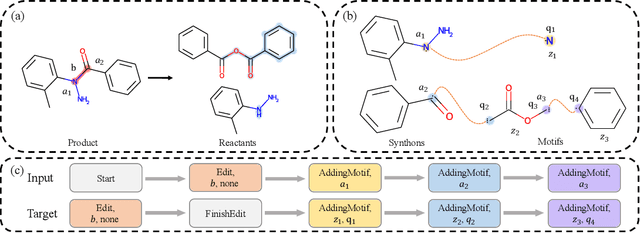
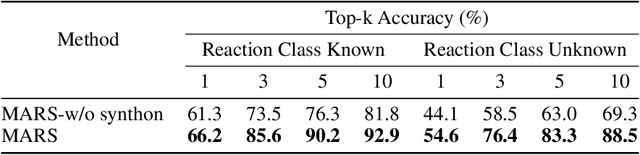
Retrosynthesis is a major task for drug discovery. It is formulated as a graph-generating problem by many existing approaches. Specifically, these methods firstly identify the reaction center, and break target molecule accordingly to generate synthons. Reactants are generated by either adding atoms sequentially to synthon graphs or directly adding proper leaving groups. However, both two strategies suffer since adding atoms results in a long prediction sequence which increases generation difficulty, while adding leaving groups can only consider the ones in the training set which results in poor generalization. In this paper, we propose a novel end-to-end graph generation model for retrosynthesis prediction, which sequentially identifies the reaction center, generates the synthons, and adds motifs to the synthons to generate reactants. Since chemically meaningful motifs are bigger than atoms and smaller than leaving groups, our method enjoys lower prediction complexity than adding atoms and better generalization than adding leaving groups. Experiments on a benchmark dataset show that the proposed model significantly outperforms previous state-of-the-art algorithms.
ImDrug: A Benchmark for Deep Imbalanced Learning in AI-aided Drug Discovery
Sep 16, 2022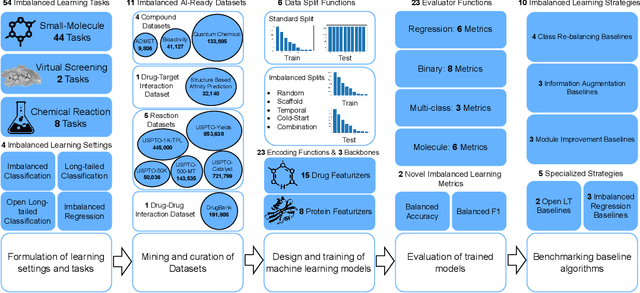

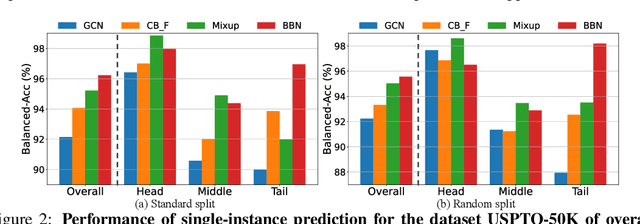
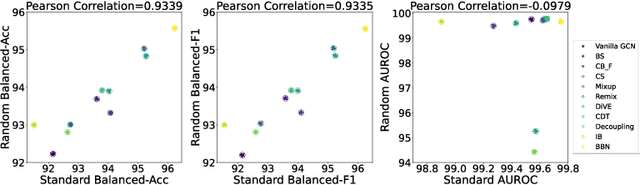
The last decade has witnessed a prosperous development of computational methods and dataset curation for AI-aided drug discovery (AIDD). However, real-world pharmaceutical datasets often exhibit highly imbalanced distribution, which is largely overlooked by the current literature but may severely compromise the fairness and generalization of machine learning applications. Motivated by this observation, we introduce ImDrug, a comprehensive benchmark with an open-source Python library which consists of 4 imbalance settings, 11 AI-ready datasets, 54 learning tasks and 16 baseline algorithms tailored for imbalanced learning. It provides an accessible and customizable testbed for problems and solutions spanning a broad spectrum of the drug discovery pipeline such as molecular modeling, drug-target interaction and retrosynthesis. We conduct extensive empirical studies with novel evaluation metrics, to demonstrate that the existing algorithms fall short of solving medicinal and pharmaceutical challenges in the data imbalance scenario. We believe that ImDrug opens up avenues for future research and development, on real-world challenges at the intersection of AIDD and deep imbalanced learning.
RetroComposer: Discovering Novel Reactions by Composing Templates for Retrosynthesis Prediction
Dec 20, 2021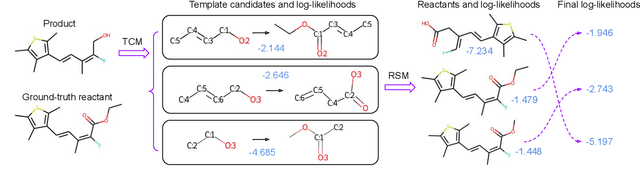
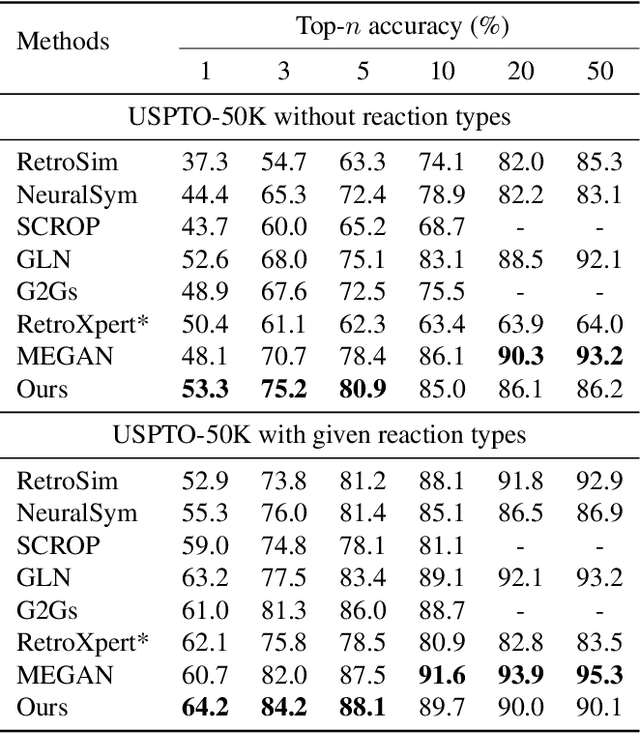
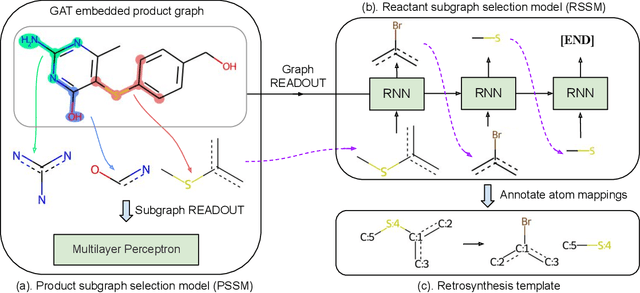
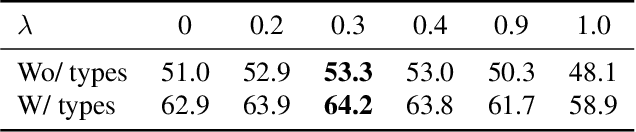
The main target of retrosynthesis is to recursively decompose desired molecules into available building blocks. Existing template-based retrosynthesis methods follow a template selection stereotype and suffer from the limited training templates, which prevents them from discovering novel reactions. To overcome the limitation, we propose an innovative retrosynthesis prediction framework that can compose novel templates beyond training templates. So far as we know, this is the first method that can find novel templates for retrosynthesis prediction. Besides, we propose an effective reactant candidates scoring model that can capture atom-level transformation information, and it helps our method outperform existing methods by a large margin. Experimental results show that our method can produce novel templates for 328 test reactions in the USPTO-50K dataset, including 21 test reactions that are not covered by the training templates.
Towards Photo-Realistic Visible Watermark Removal with Conditional Generative Adversarial Networks
May 31, 2019
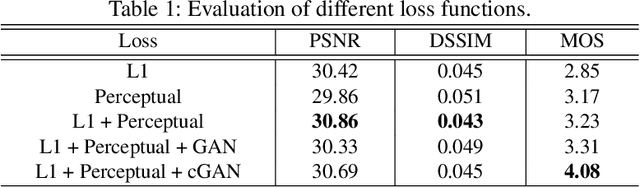
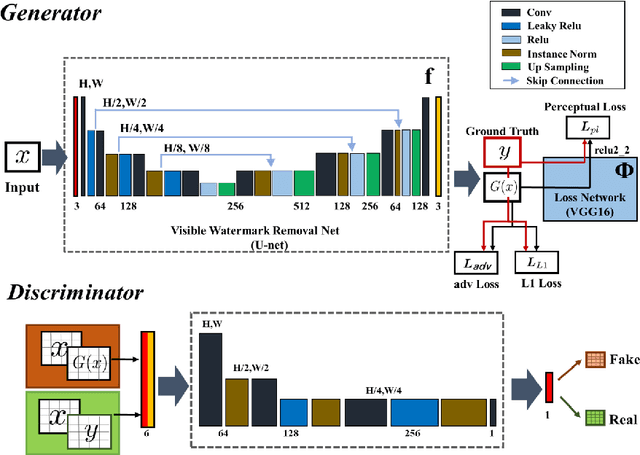
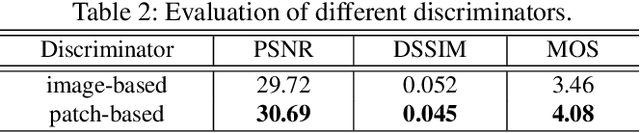
Visible watermark plays an important role in image copyright protection and the robustness of a visible watermark to an attack is shown to be essential. To evaluate and improve the effectiveness of watermark, watermark removal attracts increasing attention and becomes a hot research top. Current methods cast the watermark removal as an image-to-image translation problem where the encode-decode architectures with pixel-wise loss are adopted to transfer the transparent watermarked pixels into unmarked pixels. However, when a number of realistic images are presented, the watermarks are more likely to be unknown and diverse (i.e., the watermarks might be opaque or semi-transparent; the category and pattern of watermarks are unknown). When applying existing methods to the real-world scenarios, they mostly can not satisfactorily reconstruct the hidden information obscured under the complex and various watermarks (i.e., the residual watermark traces remain and the reconstructed images lack reality). To address this difficulty, in this paper, we present a new watermark processing framework using the conditional generative adversarial networks (cGANs) for visible watermark removal in the real-world application. The proposed method enables the watermark removal solution to be more closed to the photo-realistic reconstruction using a patch-based discriminator conditioned on the watermarked images, which is adversarially trained to differentiate the difference between the recovered images and original watermark-free images. Extensive experimental results on a large-scale visible watermark dataset demonstrate the effectiveness of the proposed method and clearly indicate that our proposed approach can produce more photo-realistic and convincing results compared with the state-of-the-art methods.