 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHAIRO: Contextual Hierarchical Analogical Induction and Reasoning Optimization for LLMs
Apr 12, 2026Content moderation in online platforms faces persistent challenges due to the evolving complexity of user-generated content and the limitations of traditional rule-based and machine learning approaches. While recent advances in large language models (LLMs) have enabled more sophisticated moderation via direct prompting or fine-tuning, these approaches often exhibit limited generalization, interpretability, and adaptability to unseen or ambiguous cases. In this work, we propose a novel moderation framework that leverages analogical examples to enhance rule induction and decision reliability. Our approach integrates end-to-end optimization of analogical retrieval, rule generation, and moderation classification, enabling the dynamic adaptation of moderation rules to diverse content scenarios. Through comprehensive experiments, we demonstrate that our method significantly outperforms both rule-injected fine-tuning baselines and multi-stage static RAG pipelines in terms of moderation accuracy and rule quality. Further evaluations, including human assessments and external model generalization tests, confirm that our framework produces rules with better clarity, interpretability, and applicability. These findings show that analogical example-driven methods can advance robust, explainable, and generalizable content moderation in real-world applications.
CARO: Chain-of-Analogy Reasoning Optimization for Robust Content Moderation
Apr 12, 2026Current large language models (LLMs), even those explicitly trained for reasoning, often struggle with ambiguous content moderation cases due to misleading "decision shortcuts" embedded in context. Inspired by cognitive psychology insights into expert moderation, we introduce \caro (Chain-of-Analogy Reasoning Optimization), a novel two-stage training framework to induce robust analogical reasoning in LLMs. First, \caro bootstraps analogical reasoning chains via retrieval-augmented generation (RAG) on moderation data and performs supervised fine-tuning (SFT). Second, we propose a customized direct preference optimization (DPO) approach to reinforce analogical reasoning behaviors explicitly. Unlike static retrieval methods, \caro dynamically generates tailored analogical references during inference, effectively mitigating harmful decision shortcuts. Extensive experiments demonstrate that \caro substantially outperforms state-of-the-art reasoning models (DeepSeek R1, QwQ), specialized moderation models (LLaMA Guard), and advanced fine-tuning and retrieval-augmented methods, achieving an average F1 score improvement of 24.9\% on challenging ambiguous moderation benchmarks.
IBCircuit: Towards Holistic Circuit Discovery with Information Bottleneck
Feb 26, 2026Circuit discovery has recently attracted attention as a potential research direction to explain the non-trivial behaviors of language models. It aims to find the computational subgraphs, also known as circuits, within the model that are responsible for solving specific tasks. However, most existing studies overlook the holistic nature of these circuits and require designing specific corrupted activations for different tasks, which is inaccurate and inefficient. In this work, we propose an end-to-end approach based on the principle of Information Bottleneck, called IBCircuit, to identify informative circuits holistically. IBCircuit is an optimization framework for holistic circuit discovery and can be applied to any given task without tediously corrupted activation design. In both the Indirect Object Identification (IOI) and Greater-Than tasks, IBCircuit identifies more faithful and minimal circuits in terms of critical node components and edge components compared to recent related work.
Sparsification and Reconstruction from the Perspective of Representation Geometry
May 28, 2025Sparse Autoencoders (SAEs) have emerged as a predominant tool in mechanistic interpretability, aiming to identify interpretable monosemantic features. However, how does sparse encoding organize the representations of activation vector from language models? What is the relationship between this organizational paradigm and feature disentanglement as well as reconstruction performance? To address these questions, we propose the SAEMA, which validates the stratified structure of the representation by observing the variability of the rank of the symmetric semipositive definite (SSPD) matrix corresponding to the modal tensor unfolded along the latent tensor with the level of noise added to the residual stream. To systematically investigate how sparse encoding alters representational structures, we define local and global representations, demonstrating that they amplify inter-feature distinctions by merging similar semantic features and introducing additional dimensionality. Furthermore, we intervene the global representation from an optimization perspective, proving a significant causal relationship between their separability and the reconstruction performance. This study explains the principles of sparsity from the perspective of representational geometry and demonstrates the impact of changes in representational structure on reconstruction performance. Particularly emphasizes the necessity of understanding representations and incorporating representational constraints, providing empirical references for developing new interpretable tools and improving SAEs. The code is available at \hyperlink{https://github.com/wenjie1835/SAERepGeo}{https://github.com/wenjie1835/SAERepGeo}.
Measuring Diversity in Synthetic Datasets
Feb 12, 2025Large language models (LLMs) are widely adopted to generate synthetic datasets for various natural language processing (NLP) tasks, such as text classification and summarization. However, accurately measuring the diversity of these synthetic datasets-an aspect crucial for robust model performance-remains a significant challenge. In this paper, we introduce DCScore, a novel method for measuring synthetic dataset diversity from a classification perspective. Specifically, DCScore formulates diversity evaluation as a sample classification task, leveraging mutual relationships among samples. We further provide theoretical verification of the diversity-related axioms satisfied by DCScore, highlighting its role as a principled diversity evaluation method. Experimental results on synthetic datasets reveal that DCScore enjoys a stronger correlation with multiple diversity pseudo-truths of evaluated datasets, underscoring its effectiveness. Moreover, both empirical and theoretical evidence demonstrate that DCScore substantially reduces computational costs compared to existing approaches. Code is available at: https://github.com/BlueWhaleLab/DCScore.
Probing the Safety Response Boundary of Large Language Models via Unsafe Decoding Path Generation
Aug 21, 2024



Large Language Models (LLMs) are implicit troublemakers. While they provide valuable insights and assist in problem-solving, they can also potentially serve as a resource for malicious activities. Implementing safety alignment could mitigate the risk of LLMs generating harmful responses. We argue that: even when an LLM appears to successfully block harmful queries, there may still be hidden vulnerabilities that could act as ticking time bombs. To identify these underlying weaknesses, we propose to use a cost value model as both a detector and an attacker. Trained on external or self-generated harmful datasets, the cost value model could successfully influence the original safe LLM to output toxic content in decoding process. For instance, LLaMA-2-chat 7B outputs 39.18% concrete toxic content, along with only 22.16% refusals without any harmful suffixes. These potential weaknesses can then be exploited via prompt optimization such as soft prompts on images. We name this decoding strategy: Jailbreak Value Decoding (JVD), emphasizing that seemingly secure LLMs may not be as safe as we initially believe. They could be used to gather harmful data or launch covert attacks.
RiskAwareBench: Towards Evaluating Physical Risk Awareness for High-level Planning of LLM-based Embodied Agents
Aug 08, 2024



The integration of large language models (LLMs) into robotics significantly enhances the capabilities of embodied agents in understanding and executing complex natural language instructions. However, the unmitigated deployment of LLM-based embodied systems in real-world environments may pose potential physical risks, such as property damage and personal injury. Existing security benchmarks for LLMs overlook risk awareness for LLM-based embodied agents. To address this gap, we propose RiskAwareBench, an automated framework designed to assess physical risks awareness in LLM-based embodied agents. RiskAwareBench consists of four modules: safety tips generation, risky scene generation, plan generation, and evaluation, enabling comprehensive risk assessment with minimal manual intervention. Utilizing this framework, we compile the PhysicalRisk dataset, encompassing diverse scenarios with associated safety tips, observations, and instructions. Extensive experiments reveal that most LLMs exhibit insufficient physical risk awareness, and baseline risk mitigation strategies yield limited enhancement, which emphasizes the urgency and cruciality of improving risk awareness in LLM-based embodied agents in the future.
Parameter-Efficient Fine-Tuning with Discrete Fourier Transform
May 05, 2024Low-rank adaptation~(LoRA) has recently gained much interest in fine-tuning foundation models. It effectively reduces the number of trainable parameters by incorporating low-rank matrices $A$ and $B$ to represent the weight change, i.e., $\Delta W=BA$. Despite LoRA's progress, it faces storage challenges when handling extensive customization adaptations or larger base models. In this work, we aim to further compress trainable parameters by enjoying the powerful expressiveness of the Fourier transform. Specifically, we introduce FourierFT, which treats $\Delta W$ as a matrix in the spatial domain and learns only a small fraction of its spectral coefficients. With the trained spectral coefficients, we implement the inverse discrete Fourier transform to recover $\Delta W$. Empirically, our FourierFT method shows comparable or better performance with fewer parameters than LoRA on various tasks, including natural language understanding, natural language generation, instruction tuning, and image classification. For example, when performing instruction tuning on the LLaMA2-7B model, FourierFT surpasses LoRA with only 0.064M trainable parameters, compared to LoRA's 33.5M. Our code is released at \url{https://github.com/Chaos96/fourierft}.
LLM Inference Unveiled: Survey and Roofline Model Insights
Mar 11, 2024The field of efficient Large Language Model (LLM) inference is rapidly evolving, presenting a unique blend of opportunities and challenges. Although the field has expanded and is vibrant, there hasn't been a concise framework that analyzes the various methods of LLM Inference to provide a clear understanding of this domain. Our survey stands out from traditional literature reviews by not only summarizing the current state of research but also by introducing a framework based on roofline model for systematic analysis of LLM inference techniques. This framework identifies the bottlenecks when deploying LLMs on hardware devices and provides a clear understanding of practical problems, such as why LLMs are memory-bound, how much memory and computation they need, and how to choose the right hardware. We systematically collate the latest advancements in efficient LLM inference, covering crucial areas such as model compression (e.g., Knowledge Distillation and Quantization), algorithm improvements (e.g., Early Exit and Mixture-of-Expert), and both hardware and system-level enhancements. Our survey stands out by analyzing these methods with roofline model, helping us understand their impact on memory access and computation. This distinctive approach not only showcases the current research landscape but also delivers valuable insights for practical implementation, positioning our work as an indispensable resource for researchers new to the field as well as for those seeking to deepen their understanding of efficient LLM deployment. The analyze tool, LLM-Viewer, is open-sourced.
Invariant Test-Time Adaptation for Vision-Language Model Generalization
Mar 01, 2024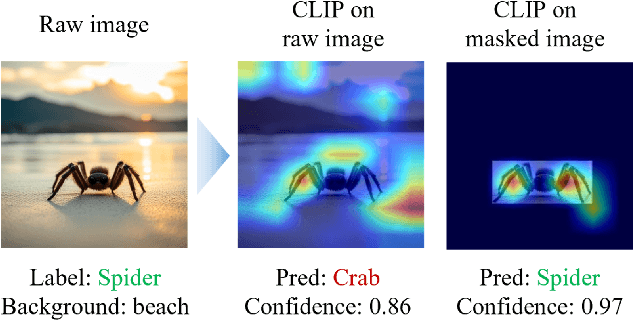

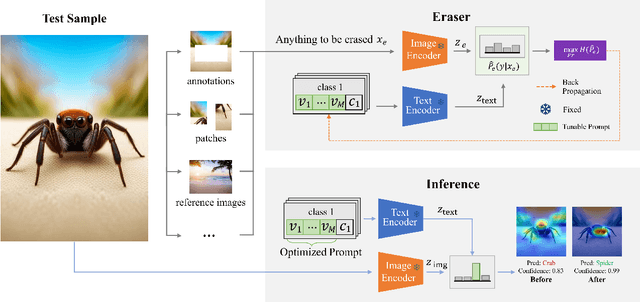

Vision-language foundation models have exhibited remarkable success across a multitude of downstream tasks due to their scalability on extensive image-text paired datasets. However, these models display significant limitations when applied to long-tail tasks, such as fine-grained image classification, as a result of "decision shortcuts" that hinders their generalization capabilities. In this work, we find that the CLIP model possesses a rich set of features, encompassing both \textit{desired invariant causal features} and \textit{undesired decision shortcuts}. Moreover, the underperformance of CLIP on downstream tasks originates from its inability to effectively utilize pre-trained features in accordance with specific task requirements. To address this challenge, this paper introduces a test-time prompt tuning paradigm that optimizes a learnable prompt, thereby compelling the model to exploit genuine causal invariant features while disregarding decision shortcuts during the inference phase. The proposed method effectively alleviates excessive dependence on potentially misleading, task-irrelevant contextual information, while concurrently emphasizing critical, task-related visual cues. We conduct comparative analysis of the proposed method against various approaches which validates its effectiveness.