 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-DC: When to retrieve and When to generate? Self Divide-and-Conquer for Compositional Unknown Questions
Feb 21, 2024



Retrieve-then-read and generate-then-read are two typical solutions to handle unknown and known questions in open-domain question-answering, while the former retrieves necessary external knowledge and the later prompt the large language models to generate internal known knowledge encoded in the parameters. However, few of previous works consider the compositional unknown questions, which consist of several known or unknown sub-questions. Thus, simple binary classification (known or unknown) becomes sub-optimal and inefficient since it will call external retrieval excessively for each compositional unknown question. To this end, we propose the first Compositional unknown Question-Answering dataset (CuQA), and introduce a Self Divide-and-Conquer (Self-DC) framework to empower LLMs to adaptively call different methods on-demand, resulting in better performance and efficiency. Experimental results on two datasets (CuQA and FreshQA) demonstrate that Self-DC can achieve comparable or even better performance with much more less retrieval times compared with several strong baselines.
X-Mark: Towards Lossless Watermarking Through Lexical Redundancy
Nov 16, 2023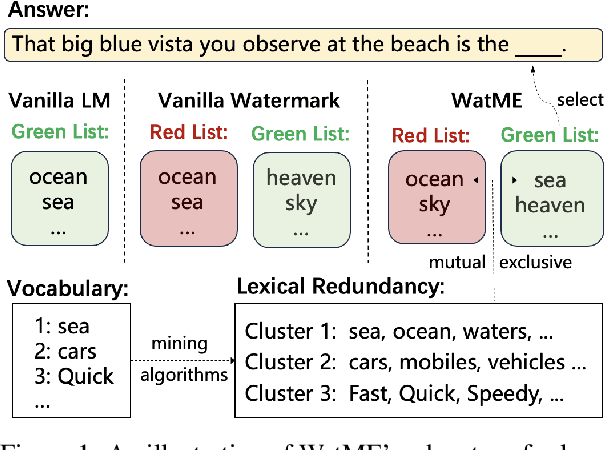
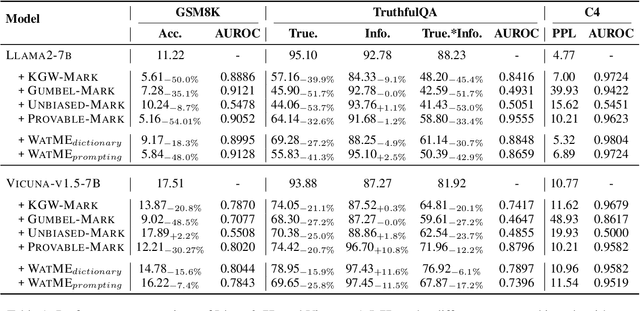
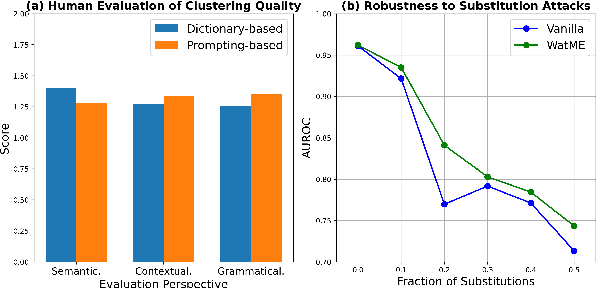
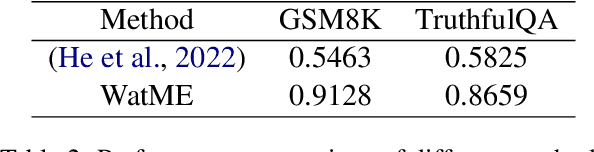
Text watermarking has emerged as an important technique for detecting machine-generated text. However, existing methods can severely degrade text quality due to arbitrary vocabulary partitioning, which disrupts the language model's expressiveness and impedes textual coherence. To mitigate this, we introduce XMark, a novel approach that capitalizes on text redundancy within the lexical space. Specifically, XMark incorporates a mutually exclusive rule for synonyms during the language model decoding process, thereby integrating prior knowledge into vocabulary partitioning and preserving the capabilities of language generation. We present theoretical analyses and empirical evidence demonstrating that XMark substantially enhances text generation fluency while maintaining watermark detectability. Furthermore, we investigate watermarking's impact on the emergent abilities of large language models, including zero-shot and few-shot knowledge recall, logical reasoning, and instruction following. Our comprehensive experiments confirm that XMark consistently outperforms existing methods in retaining these crucial capabilities of LLMs.
UniTRec: A Unified Text-to-Text Transformer and Joint Contrastive Learning Framework for Text-based Recommendation
May 25, 2023Prior study has shown that pretrained language models (PLM) can boost the performance of text-based recommendation. In contrast to previous works that either use PLM to encode user history as a whole input text, or impose an additional aggregation network to fuse multi-turn history representations, we propose a unified local- and global-attention Transformer encoder to better model two-level contexts of user history. Moreover, conditioned on user history encoded by Transformer encoders, our framework leverages Transformer decoders to estimate the language perplexity of candidate text items, which can serve as a straightforward yet significant contrastive signal for user-item text matching. Based on this, our framework, UniTRec, unifies the contrastive objectives of discriminative matching scores and candidate text perplexity to jointly enhance text-based recommendation. Extensive evaluation shows that UniTRec delivers SOTA performance on three text-based recommendation tasks. Code is available at https://github.com/Veason-silverbullet/UniTRec.