 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Mark: Towards Lossless Watermarking Through Lexical Redundancy
Paper and Code
Nov 16, 2023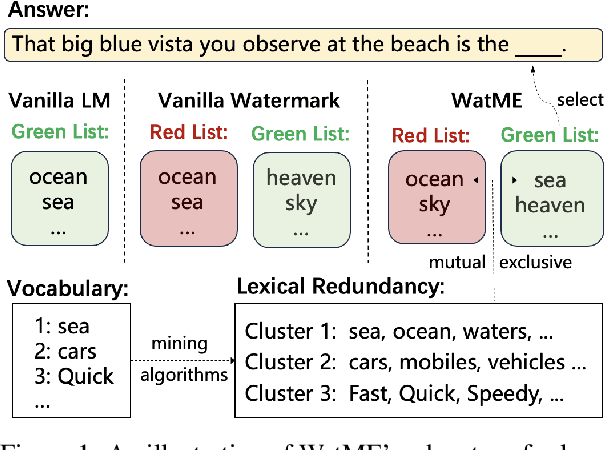
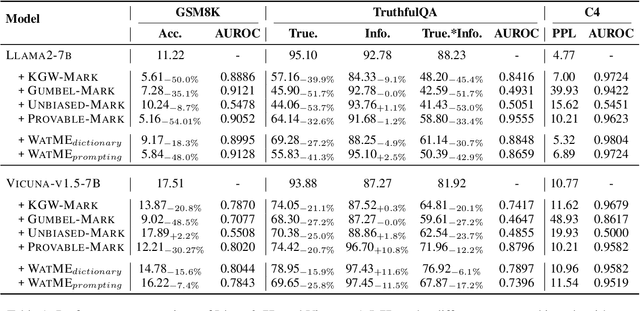
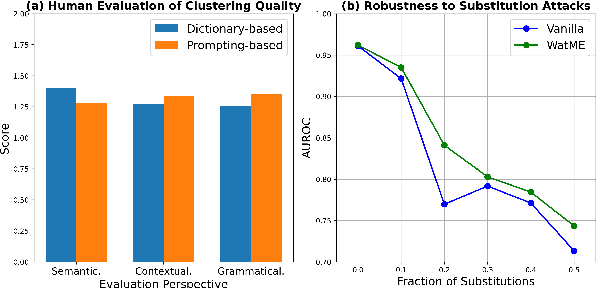
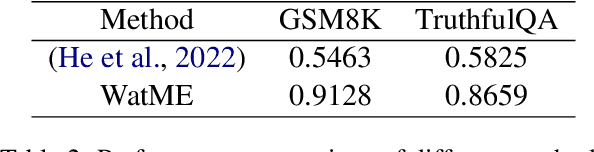
Text watermarking has emerged as an important technique for detecting machine-generated text. However, existing methods can severely degrade text quality due to arbitrary vocabulary partitioning, which disrupts the language model's expressiveness and impedes textual coherence. To mitigate this, we introduce XMark, a novel approach that capitalizes on text redundancy within the lexical space. Specifically, XMark incorporates a mutually exclusive rule for synonyms during the language model decoding process, thereby integrating prior knowledge into vocabulary partitioning and preserving the capabilities of language generation. We present theoretical analyses and empirical evidence demonstrating that XMark substantially enhances text generation fluency while maintaining watermark detectability. Furthermore, we investigate watermarking's impact on the emergent abilities of large language models, including zero-shot and few-shot knowledge recall, logical reasoning, and instruction following. Our comprehensive experiments confirm that XMark consistently outperforms existing methods in retaining these crucial capabilities of LLMs.