 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGist: Towards General and Hardware-aligned Sequence-level Long Context Compression
Sep 19, 2025Large language models are increasingly capable of handling long-context inputs, but the memory overhead of key-value (KV) cache remains a major bottleneck for general-purpose deployment. While various compression strategies have been explored, sequence-level compression, which drops the full KV caches for certain tokens, is particularly challenging as it can lead to the loss of important contextual information. To address this, we introduce UniGist, a sequence-level long-context compression framework that efficiently preserves context information by replacing raw tokens with special compression tokens (gists) in a fine-grained manner. We adopt a chunk-free training strategy and design an efficient kernel with a gist shift trick, enabling optimized GPU training. Our scheme also supports flexible inference by allowing the actual removal of compressed tokens, resulting in real-time memory savings. Experiments across multiple long-context tasks demonstrate that UniGist significantly improves compression quality, with especially strong performance in detail-recalling tasks and long-range dependency modeling.
InComeS: Integrating Compression and Selection Mechanisms into LLMs for Efficient Model Editing
May 28, 2025Although existing model editing methods perform well in recalling exact edit facts, they often struggle in complex scenarios that require deeper semantic understanding rather than mere knowledge regurgitation. Leveraging the strong contextual reasoning abilities of large language models (LLMs), in-context learning (ICL) becomes a promising editing method by comprehending edit information through context encoding. However, this method is constrained by the limited context window of LLMs, leading to degraded performance and efficiency as the number of edits increases. To overcome this limitation, we propose InComeS, a flexible framework that enhances LLMs' ability to process editing contexts through explicit compression and selection mechanisms. Specifically, InComeS compresses each editing context into the key-value (KV) cache of a special gist token, enabling efficient handling of multiple edits without being restricted by the model's context window. Furthermore, specialized cross-attention modules are added to dynamically select the most relevant information from the gist pools, enabling adaptive and effective utilization of edit information. We conduct experiments on diverse model editing benchmarks with various editing formats, and the results demonstrate the effectiveness and efficiency of our method.
A Silver Bullet or a Compromise for Full Attention? A Comprehensive Study of Gist Token-based Context Compression
Dec 23, 2024



In this work, we provide a thorough investigation of gist-based context compression methods to improve long-context processing in large language models. We focus on two key questions: (1) How well can these methods replace full attention models? and (2) What potential failure patterns arise due to compression? Through extensive experiments, we show that while gist-based compression can achieve near-lossless performance on tasks like retrieval-augmented generation and long-document QA, it faces challenges in tasks like synthetic recall. Furthermore, we identify three key failure patterns: lost by the boundary, lost if surprise, and lost along the way. To mitigate these issues, we propose two effective strategies: fine-grained autoencoding, which enhances the reconstruction of original token information, and segment-wise token importance estimation, which adjusts optimization based on token dependencies. Our work provides valuable insights into the understanding of gist token-based context compression and offers practical strategies for improving compression capabilities.
Attention Entropy is a Key Factor: An Analysis of Parallel Context Encoding with Full-attention-based Pre-trained Language Models
Dec 21, 2024



Large language models have shown remarkable performance across a wide range of language tasks, owing to their exceptional capabilities in context modeling. The most commonly used method of context modeling is full self-attention, as seen in standard decoder-only Transformers. Although powerful, this method can be inefficient for long sequences and may overlook inherent input structures. To address these problems, an alternative approach is parallel context encoding, which splits the context into sub-pieces and encodes them parallelly. Because parallel patterns are not encountered during training, naively applying parallel encoding leads to performance degradation. However, the underlying reasons and potential mitigations are unclear. In this work, we provide a detailed analysis of this issue and identify that unusually high attention entropy can be a key factor. Furthermore, we adopt two straightforward methods to reduce attention entropy by incorporating attention sinks and selective mechanisms. Experiments on various tasks reveal that these methods effectively lower irregular attention entropy and narrow performance gaps. We hope this study can illuminate ways to enhance context modeling mechanisms.
Knowledge Boundary of Large Language Models: A Survey
Dec 17, 2024



Although large language models (LLMs) store vast amount of knowledge in their parameters, they still have limitations in the memorization and utilization of certain knowledge, leading to undesired behaviors such as generating untruthful and inaccurate responses. This highlights the critical need to understand the knowledge boundary of LLMs, a concept that remains inadequately defined in existing research. In this survey, we propose a comprehensive definition of the LLM knowledge boundary and introduce a formalized taxonomy categorizing knowledge into four distinct types. Using this foundation, we systematically review the field through three key lenses: the motivation for studying LLM knowledge boundaries, methods for identifying these boundaries, and strategies for mitigating the challenges they present. Finally, we discuss open challenges and potential research directions in this area. We aim for this survey to offer the community a comprehensive overview, facilitate access to key issues, and inspire further advancements in LLM knowledge research.
On the Transformations across Reward Model, Parameter Update, and In-Context Prompt
Jun 24, 2024Despite the general capabilities of pre-trained large language models (LLMs), they still need further adaptation to better serve practical applications. In this paper, we demonstrate the interchangeability of three popular and distinct adaptation tools: parameter updating, reward modeling, and in-context prompting. This interchangeability establishes a triangular framework with six transformation directions, each of which facilitates a variety of applications. Our work offers a holistic view that unifies numerous existing studies and suggests potential research directions. We envision our work as a useful roadmap for future research on LLMs.
Consecutive Model Editing with Batch alongside HooK Layers
Mar 08, 2024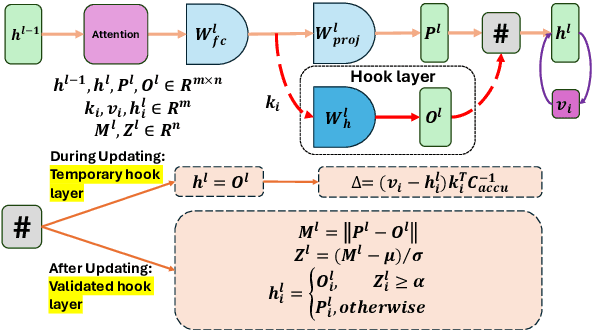



As the typical retraining paradigm is unacceptably time- and resource-consuming, researchers are turning to model editing in order to seek an effective, consecutive, and batch-supportive way to edit the model behavior directly. Despite all these practical expectations, existing model editing methods fail to realize all of them. Furthermore, the memory demands for such succession-supportive model editing approaches tend to be prohibitive, frequently necessitating an external memory that grows incrementally over time. To cope with these challenges, we propose COMEBA-HK, a model editing method that is both consecutive and batch-supportive. COMEBA-HK is memory-friendly as it only needs a small amount of it to store several hook layers with updated weights. Experimental results demonstrate the superiority of our method over other batch-supportive model editing methods under both single-round and consecutive batch editing scenarios. Extensive analyses of COMEBA-HK have been conducted to verify the stability of our method over 1) the number of consecutive steps and 2) the number of editing instance.
X-Mark: Towards Lossless Watermarking Through Lexical Redundancy
Nov 16, 2023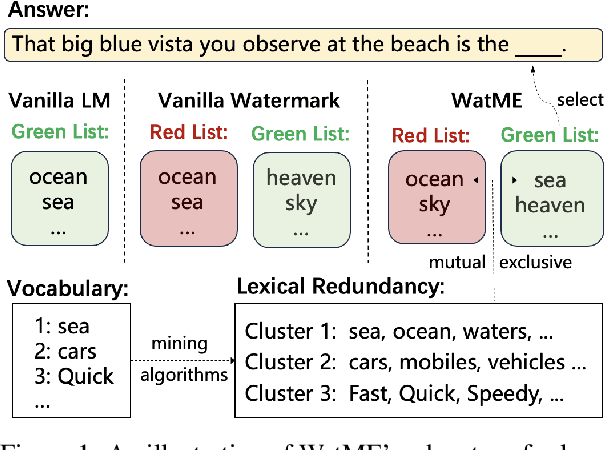
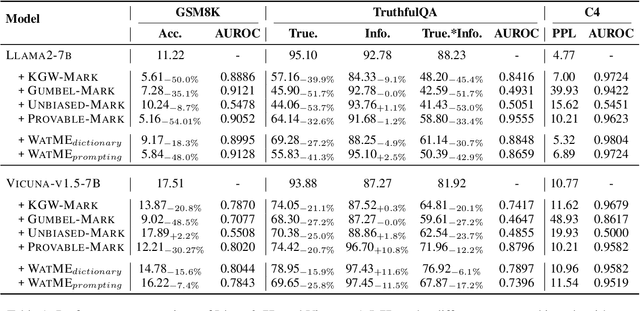
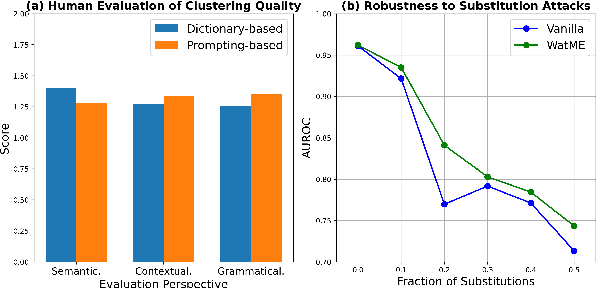
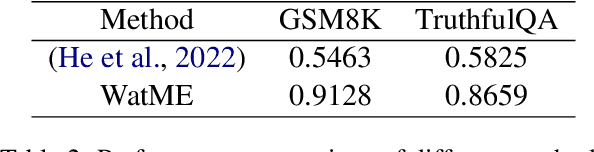
Text watermarking has emerged as an important technique for detecting machine-generated text. However, existing methods can severely degrade text quality due to arbitrary vocabulary partitioning, which disrupts the language model's expressiveness and impedes textual coherence. To mitigate this, we introduce XMark, a novel approach that capitalizes on text redundancy within the lexical space. Specifically, XMark incorporates a mutually exclusive rule for synonyms during the language model decoding process, thereby integrating prior knowledge into vocabulary partitioning and preserving the capabilities of language generation. We present theoretical analyses and empirical evidence demonstrating that XMark substantially enhances text generation fluency while maintaining watermark detectability. Furthermore, we investigate watermarking's impact on the emergent abilities of large language models, including zero-shot and few-shot knowledge recall, logical reasoning, and instruction following. Our comprehensive experiments confirm that XMark consistently outperforms existing methods in retaining these crucial capabilities of LLMs.
DepWiGNN: A Depth-wise Graph Neural Network for Multi-hop Spatial Reasoning in Text
Oct 19, 2023
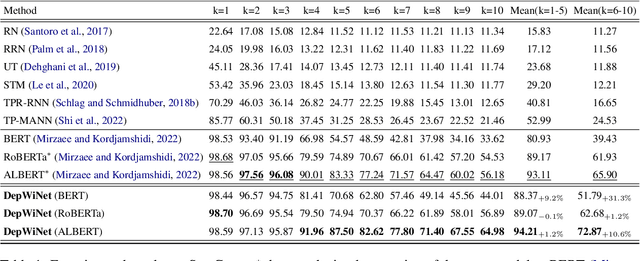
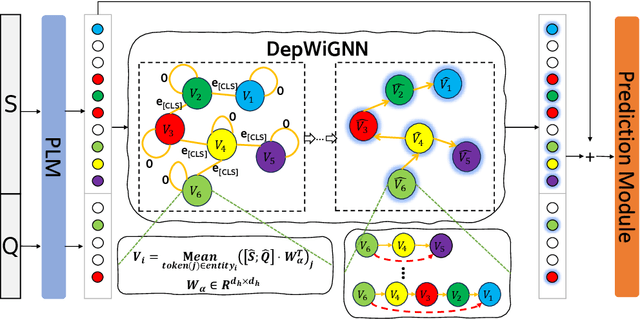
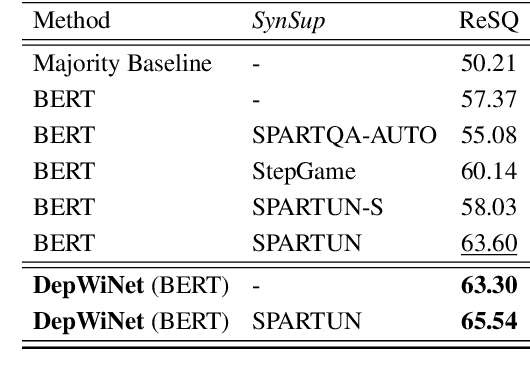
Spatial reasoning in text plays a crucial role in various real-world applications. Existing approaches for spatial reasoning typically infer spatial relations from pure text, which overlook the gap between natural language and symbolic structures. Graph neural networks (GNNs) have showcased exceptional proficiency in inducing and aggregating symbolic structures. However, classical GNNs face challenges in handling multi-hop spatial reasoning due to the over-smoothing issue, \textit{i.e.}, the performance decreases substantially as the number of graph layers increases. To cope with these challenges, we propose a novel \textbf{Dep}th-\textbf{Wi}se \textbf{G}raph \textbf{N}eural \textbf{N}etwork (\textbf{DepWiGNN}). Specifically, we design a novel node memory scheme and aggregate the information over the depth dimension instead of the breadth dimension of the graph, which empowers the ability to collect long dependencies without stacking multiple layers. Experimental results on two challenging multi-hop spatial reasoning datasets show that DepWiGNN outperforms existing spatial reasoning methods. The comparisons with the other three GNNs further demonstrate its superiority in capturing long dependency in the graph.