 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdam's Law: Textual Frequency Law on Large Language Models
Apr 02, 2026While textual frequency has been validated as relevant to human cognition in reading speed, its relatedness to Large Language Models (LLMs) is seldom studied. We propose a novel research direction in terms of textual data frequency, which is an understudied topic, to the best of our knowledge. Our framework is composed of three units. First, this paper proposes Textual Frequency Law (TFL), which indicates that frequent textual data should be preferred for LLMs for both prompting and fine-tuning. Since many LLMs are closed-source in their training data, we propose using online resources to estimate the sentence-level frequency. We then utilize an input paraphraser to paraphrase the input into a more frequent textual expression. Next, we propose Textual Frequency Distillation (TFD) by querying LLMs to conduct story completion by further extending the sentences in the datasets, and the resulting corpora are used to adjust the initial estimation. Finally, we propose Curriculum Textual Frequency Training (CTFT) that fine-tunes LLMs in an increasing order of sentence-level frequency. Experiments are conducted on our curated dataset Textual Frequency Paired Dataset (TFPD) on math reasoning, machine translation, commonsense reasoning and agentic tool calling. Results show the effectiveness of our framework.
From Abstract to Contextual: What LLMs Still Cannot Do in Mathematics
Jan 30, 2026Large language models now solve many benchmark math problems at near-expert levels, yet this progress has not fully translated into reliable performance in real-world applications. We study this gap through contextual mathematical reasoning, where the mathematical core must be formulated from descriptive scenarios. We introduce ContextMATH, a benchmark that repurposes AIME and MATH-500 problems into two contextual settings: Scenario Grounding (SG), which embeds abstract problems into realistic narratives without increasing reasoning complexity, and Complexity Scaling (CS), which transforms explicit conditions into sub-problems to capture how constraints often appear in practice. Evaluating 61 proprietary and open-source models, we observe sharp drops: on average, open-source models decline by 13 and 34 points on SG and CS, while proprietary models drop by 13 and 20. Error analysis shows that errors are dominated by incorrect problem formulation, with formulation accuracy declining as original problem difficulty increases. Correct formulation emerges as a prerequisite for success, and its sufficiency improves with model scale, indicating that larger models advance in both understanding and reasoning. Nevertheless, formulation and reasoning remain two complementary bottlenecks that limit contextual mathematical problem solving. Finally, we find that fine-tuning with scenario data improves performance, whereas formulation-only training is ineffective. However, performance gaps are only partially alleviated, highlighting contextual mathematical reasoning as a central unsolved challenge for LLMs.
AdaCtrl: Towards Adaptive and Controllable Reasoning via Difficulty-Aware Budgeting
May 24, 2025Modern large reasoning models demonstrate impressive problem-solving capabilities by employing sophisticated reasoning strategies. However, they often struggle to balance efficiency and effectiveness, frequently generating unnecessarily lengthy reasoning chains for simple problems. In this work, we propose AdaCtrl, a novel framework to support both difficulty-aware adaptive reasoning budget allocation and explicit user control over reasoning depth. AdaCtrl dynamically adjusts its reasoning length based on self-assessed problem difficulty, while also allowing users to manually control the budget to prioritize either efficiency or effectiveness. This is achieved through a two-stage training pipeline: an initial cold-start fine-tuning phase to instill the ability to self-aware difficulty and adjust reasoning budget, followed by a difficulty-aware reinforcement learning (RL) stage that refines the model's adaptive reasoning strategies and calibrates its difficulty assessments based on its evolving capabilities during online training. To enable intuitive user interaction, we design explicit length-triggered tags that function as a natural interface for budget control. Empirical results show that AdaCtrl adapts reasoning length based on estimated difficulty, compared to the standard training baseline that also incorporates fine-tuning and RL, it yields performance improvements and simultaneously reduces response length by 10.06% and 12.14% on the more challenging AIME2024 and AIME2025 datasets, which require elaborate reasoning, and by 62.05% and 91.04% on the MATH500 and GSM8K datasets, where more concise responses are sufficient. Furthermore, AdaCtrl enables precise user control over the reasoning budget, allowing for tailored responses to meet specific needs.
InfiniteICL: Breaking the Limit of Context Window Size via Long Short-term Memory Transformation
Apr 03, 2025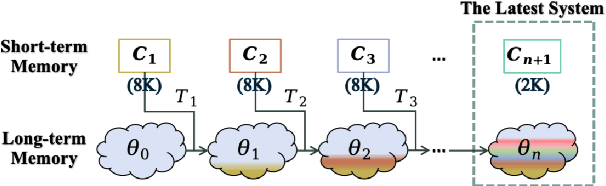
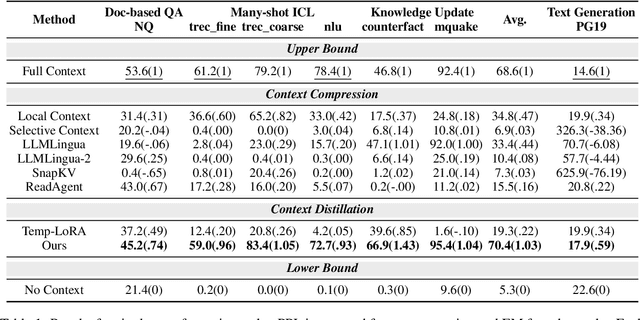
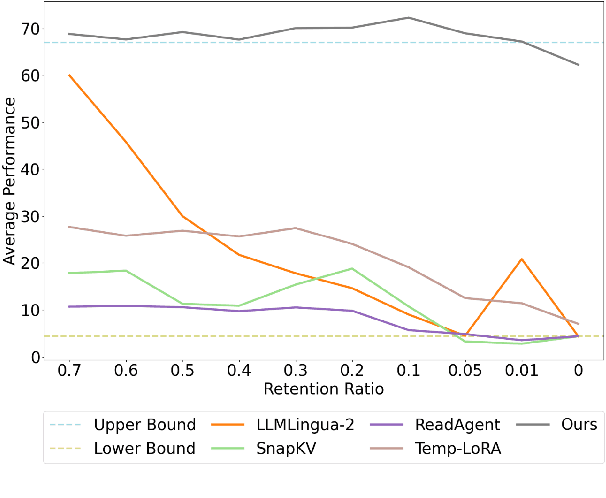
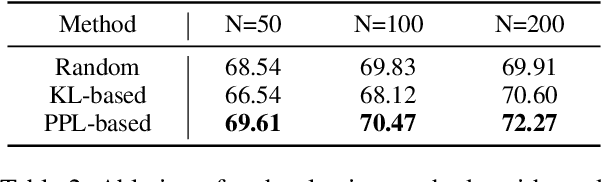
In-context learning (ICL) is critical for large language models (LLMs), but its effectiveness is constrained by finite context windows, particularly in ultra-long contexts. To overcome this, we introduce InfiniteICL, a framework that parallels context and parameters in LLMs with short- and long-term memory in human cognitive systems, focusing on transforming temporary context knowledge into permanent parameter updates. This approach significantly reduces memory usage, maintains robust performance across varying input lengths, and theoretically enables infinite context integration through the principles of context knowledge elicitation, selection, and consolidation. Evaluations demonstrate that our method reduces context length by 90% while achieving 103% average performance of full-context prompting across fact recall, grounded reasoning, and skill acquisition tasks. When conducting sequential multi-turn transformations on complex, real-world contexts (with length up to 2M tokens), our approach surpasses full-context prompting while using only 0.4% of the original contexts. These findings highlight InfiniteICL's potential to enhance the scalability and efficiency of LLMs by breaking the limitations of conventional context window sizes.
Beyond Intermediate States: Explaining Visual Redundancy through Language
Mar 26, 2025Multi-modal Large Langue Models (MLLMs) often process thousands of visual tokens, which consume a significant portion of the context window and impose a substantial computational burden. Prior work has empirically explored visual token pruning methods based on MLLMs' intermediate states (e.g., attention scores). However, they have limitations in precisely defining visual redundancy due to their inability to capture the influence of visual tokens on MLLMs' visual understanding (i.e., the predicted probabilities for textual token candidates). To address this issue, we manipulate the visual input and investigate variations in the textual output from both token-centric and context-centric perspectives, achieving intuitive and comprehensive analysis. Experimental results reveal that visual tokens with low ViT-[cls] association and low text-to-image attention scores can contain recognizable information and significantly contribute to images' overall information. To develop a more reliable method for identifying and pruning redundant visual tokens, we integrate these two perspectives and introduce a context-independent condition to identify redundant prototypes from training images, which probes the redundancy of each visual token during inference. Extensive experiments on single-image, multi-image and video comprehension tasks demonstrate the effectiveness of our method, notably achieving 90% to 110% of the performance while pruning 80% to 90% of visual tokens.
On the Transformations across Reward Model, Parameter Update, and In-Context Prompt
Jun 24, 2024Despite the general capabilities of pre-trained large language models (LLMs), they still need further adaptation to better serve practical applications. In this paper, we demonstrate the interchangeability of three popular and distinct adaptation tools: parameter updating, reward modeling, and in-context prompting. This interchangeability establishes a triangular framework with six transformation directions, each of which facilitates a variety of applications. Our work offers a holistic view that unifies numerous existing studies and suggests potential research directions. We envision our work as a useful roadmap for future research on LLMs.
On the Worst Prompt Performance of Large Language Models
Jun 08, 2024
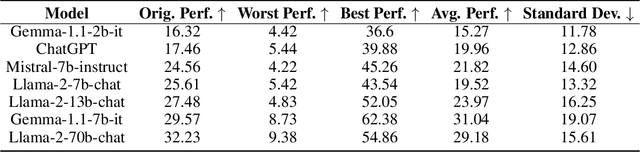
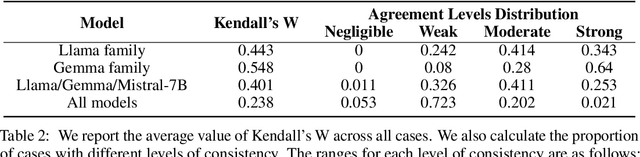
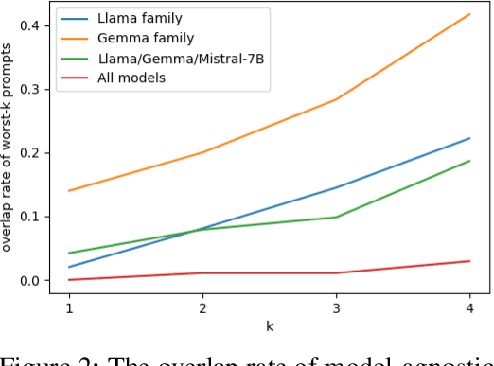
The performance of large language models (LLMs) is acutely sensitive to the phrasing of prompts, which raises significant concerns about their reliability in real-world scenarios. Existing studies often divide prompts into task-level instructions and case-level inputs and primarily focus on evaluating and improving robustness against variations in tasks-level instructions. However, this setup fails to fully address the diversity of real-world user queries and assumes the existence of task-specific datasets. To address these limitations, we introduce RobustAlpacaEval, a new benchmark that consists of semantically equivalent case-level queries and emphasizes the importance of using the worst prompt performance to gauge the lower bound of model performance. Extensive experiments on RobustAlpacaEval with ChatGPT and six open-source LLMs from the Llama, Mistral, and Gemma families uncover substantial variability in model performance; for instance, a difference of 45.48% between the worst and best performance for the Llama-2-70B-chat model, with its worst performance dipping as low as 9.38%. We further illustrate the difficulty in identifying the worst prompt from both model-agnostic and model-dependent perspectives, emphasizing the absence of a shortcut to characterize the worst prompt. We also attempt to enhance the worst prompt performance using existing prompt engineering and prompt consistency methods, but find that their impact is limited. These findings underscore the need to create more resilient LLMs that can maintain high performance across diverse prompts.
Pensieve: Retrospect-then-Compare Mitigates Visual Hallucination
Mar 21, 2024
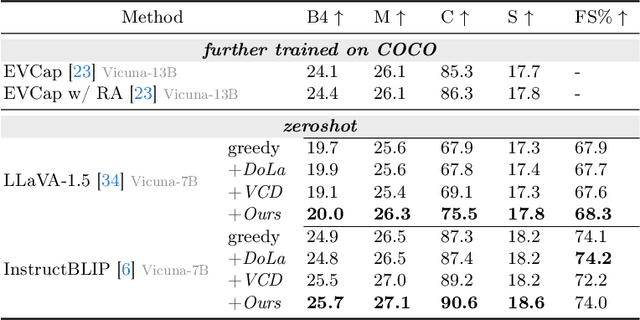
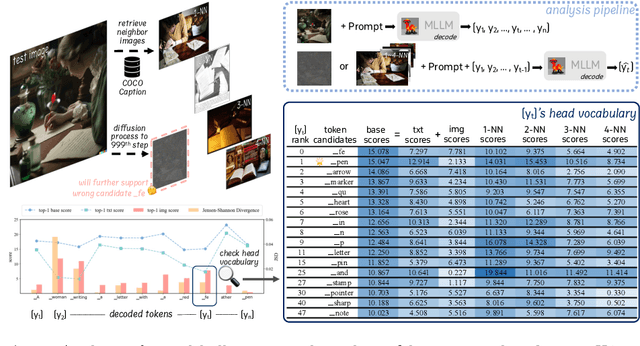
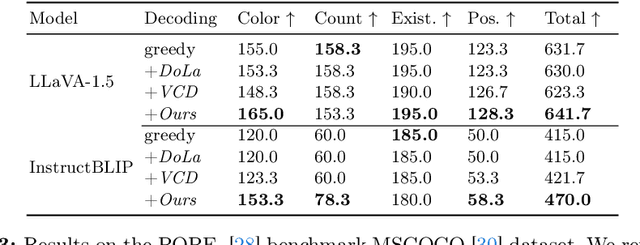
Multi-modal Large Language Models (MLLMs) demonstrate remarkable success across various vision-language tasks. However, they suffer from visual hallucination, where the generated responses diverge from the provided image. Are MLLMs completely oblivious to accurate visual cues when they hallucinate? Our investigation reveals that the visual branch may simultaneously advocate both accurate and non-existent content. To address this issue, we propose Pensieve, a training-free method inspired by our observation that analogous visual hallucinations can arise among images sharing common semantic and appearance characteristics. During inference, Pensieve enables MLLMs to retrospect relevant images as references and compare them with the test image. This paradigm assists MLLMs in downgrading hallucinatory content mistakenly supported by the visual input. Experiments on Whoops, MME, POPE, and LLaVA Bench demonstrate the efficacy of Pensieve in mitigating visual hallucination, surpassing other advanced decoding strategies. Additionally, Pensieve aids MLLMs in identifying details in the image and enhancing the specificity of image descriptions.
Retrieval is Accurate Generation
Feb 29, 2024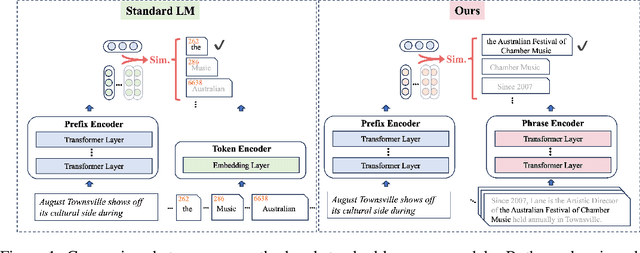
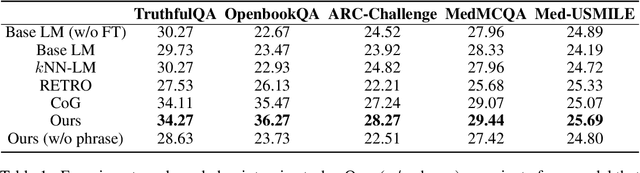

Standard language models generate text by selecting tokens from a fixed, finite, and standalone vocabulary. We introduce a novel method that selects context-aware phrases from a collection of supporting documents. One of the most significant challenges for this paradigm shift is determining the training oracles, because a string of text can be segmented in various ways and each segment can be retrieved from numerous possible documents. To address this, we propose to initialize the training oracles using linguistic heuristics and, more importantly, bootstrap the oracles through iterative self-reinforcement. Extensive experiments show that our model not only outperforms standard language models on a variety of knowledge-intensive tasks but also demonstrates improved generation quality in open-ended text generation. For instance, compared to the standard language model counterpart, our model raises the accuracy from 23.47% to 36.27% on OpenbookQA, and improves the MAUVE score from 42.61% to 81.58% in open-ended text generation. Remarkably, our model also achieves the best performance and the lowest latency among several retrieval-augmented baselines. In conclusion, we assert that retrieval is more accurate generation and hope that our work will encourage further research on this new paradigm shift.
ML-LMCL: Mutual Learning and Large-Margin Contrastive Learning for Improving ASR Robustness in Spoken Language Understanding
Nov 19, 2023Spoken language understanding (SLU) is a fundamental task in the task-oriented dialogue systems. However, the inevitable errors from automatic speech recognition (ASR) usually impair the understanding performance and lead to error propagation. Although there are some attempts to address this problem through contrastive learning, they (1) treat clean manual transcripts and ASR transcripts equally without discrimination in fine-tuning; (2) neglect the fact that the semantically similar pairs are still pushed away when applying contrastive learning; (3) suffer from the problem of Kullback-Leibler (KL) vanishing. In this paper, we propose Mutual Learning and Large-Margin Contrastive Learning (ML-LMCL), a novel framework for improving ASR robustness in SLU. Specifically, in fine-tuning, we apply mutual learning and train two SLU models on the manual transcripts and the ASR transcripts, respectively, aiming to iteratively share knowledge between these two models. We also introduce a distance polarization regularizer to avoid pushing away the intra-cluster pairs as much as possible. Moreover, we use a cyclical annealing schedule to mitigate KL vanishing issue. Experiments on three datasets show that ML-LMCL outperforms existing models and achieves new state-of-the-art performance.