 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Intermediate States: Explaining Visual Redundancy through Language
Mar 26, 2025Multi-modal Large Langue Models (MLLMs) often process thousands of visual tokens, which consume a significant portion of the context window and impose a substantial computational burden. Prior work has empirically explored visual token pruning methods based on MLLMs' intermediate states (e.g., attention scores). However, they have limitations in precisely defining visual redundancy due to their inability to capture the influence of visual tokens on MLLMs' visual understanding (i.e., the predicted probabilities for textual token candidates). To address this issue, we manipulate the visual input and investigate variations in the textual output from both token-centric and context-centric perspectives, achieving intuitive and comprehensive analysis. Experimental results reveal that visual tokens with low ViT-[cls] association and low text-to-image attention scores can contain recognizable information and significantly contribute to images' overall information. To develop a more reliable method for identifying and pruning redundant visual tokens, we integrate these two perspectives and introduce a context-independent condition to identify redundant prototypes from training images, which probes the redundancy of each visual token during inference. Extensive experiments on single-image, multi-image and video comprehension tasks demonstrate the effectiveness of our method, notably achieving 90% to 110% of the performance while pruning 80% to 90% of visual tokens.
Pensieve: Retrospect-then-Compare Mitigates Visual Hallucination
Mar 21, 2024
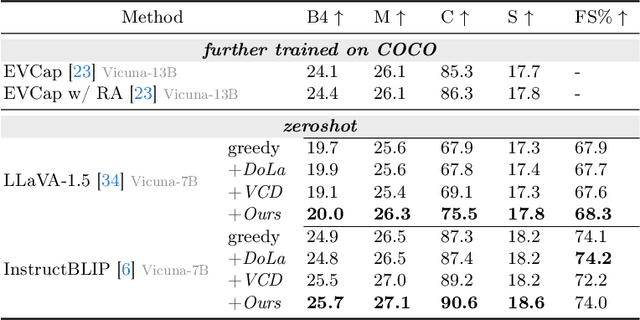
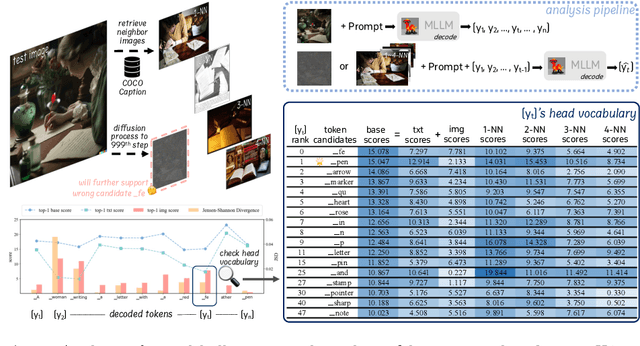
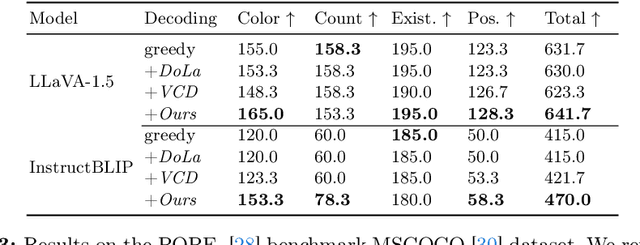
Multi-modal Large Language Models (MLLMs) demonstrate remarkable success across various vision-language tasks. However, they suffer from visual hallucination, where the generated responses diverge from the provided image. Are MLLMs completely oblivious to accurate visual cues when they hallucinate? Our investigation reveals that the visual branch may simultaneously advocate both accurate and non-existent content. To address this issue, we propose Pensieve, a training-free method inspired by our observation that analogous visual hallucinations can arise among images sharing common semantic and appearance characteristics. During inference, Pensieve enables MLLMs to retrospect relevant images as references and compare them with the test image. This paradigm assists MLLMs in downgrading hallucinatory content mistakenly supported by the visual input. Experiments on Whoops, MME, POPE, and LLaVA Bench demonstrate the efficacy of Pensieve in mitigating visual hallucination, surpassing other advanced decoding strategies. Additionally, Pensieve aids MLLMs in identifying details in the image and enhancing the specificity of image descriptions.
3D Data Augmentation for Driving Scenes on Camera
Mar 18, 2023



Driving scenes are extremely diverse and complicated that it is impossible to collect all cases with human effort alone. While data augmentation is an effective technique to enrich the training data, existing methods for camera data in autonomous driving applications are confined to the 2D image plane, which may not optimally increase data diversity in 3D real-world scenarios. To this end, we propose a 3D data augmentation approach termed Drive-3DAug, aiming at augmenting the driving scenes on camera in the 3D space. We first utilize Neural Radiance Field (NeRF) to reconstruct the 3D models of background and foreground objects. Then, augmented driving scenes can be obtained by placing the 3D objects with adapted location and orientation at the pre-defined valid region of backgrounds. As such, the training database could be effectively scaled up. However, the 3D object modeling is constrained to the image quality and the limited viewpoints. To overcome these problems, we modify the original NeRF by introducing a geometric rectified loss and a symmetric-aware training strategy. We evaluate our method for the camera-only monocular 3D detection task on the Waymo and nuScences datasets. The proposed data augmentation approach contributes to a gain of 1.7% and 1.4% in terms of detection accuracy, on Waymo and nuScences respectively. Furthermore, the constructed 3D models serve as digital driving assets and could be recycled for different detectors or other 3D perception tasks.