 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePensieve: Retrospect-then-Compare Mitigates Visual Hallucination
Paper and Code

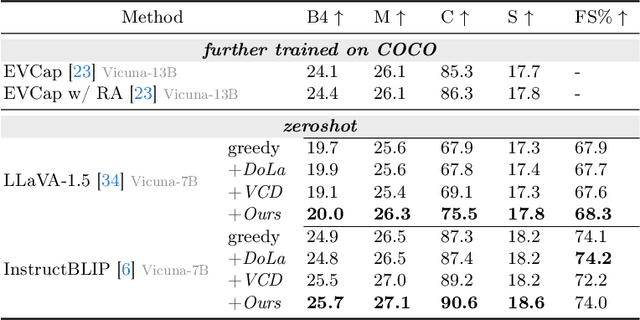
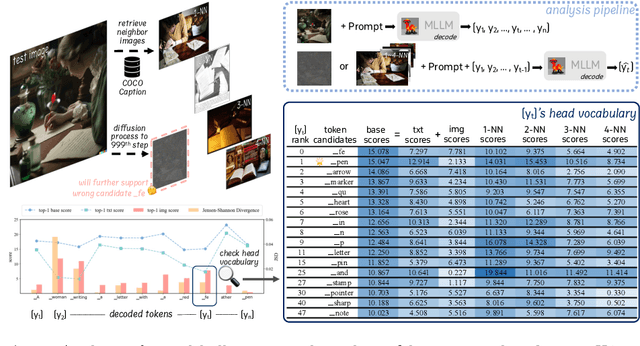
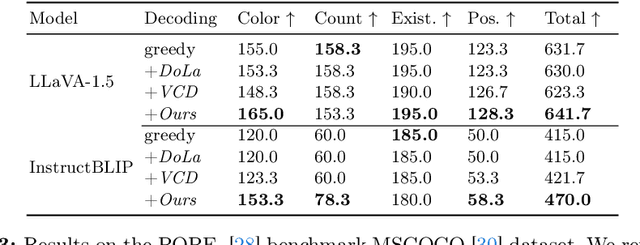
Multi-modal Large Language Models (MLLMs) demonstrate remarkable success across various vision-language tasks. However, they suffer from visual hallucination, where the generated responses diverge from the provided image. Are MLLMs completely oblivious to accurate visual cues when they hallucinate? Our investigation reveals that the visual branch may simultaneously advocate both accurate and non-existent content. To address this issue, we propose Pensieve, a training-free method inspired by our observation that analogous visual hallucinations can arise among images sharing common semantic and appearance characteristics. During inference, Pensieve enables MLLMs to retrospect relevant images as references and compare them with the test image. This paradigm assists MLLMs in downgrading hallucinatory content mistakenly supported by the visual input. Experiments on Whoops, MME, POPE, and LLaVA Bench demonstrate the efficacy of Pensieve in mitigating visual hallucination, surpassing other advanced decoding strategies. Additionally, Pensieve aids MLLMs in identifying details in the image and enhancing the specificity of image descriptions.