 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Paradigm Graph Backdoor Attacks with Promptable Subgraph Triggers
Oct 26, 2025Graph Neural Networks(GNNs) are vulnerable to backdoor attacks, where adversaries implant malicious triggers to manipulate model predictions. Existing trigger generators are often simplistic in structure and overly reliant on specific features, confining them to a single graph learning paradigm, such as graph supervised learning, graph contrastive learning, or graph prompt learning. This specialized design, which aligns the trigger with one learning objective, results in poor transferability when applied to other learning paradigms. For instance, triggers generated for the graph supervised learning paradigm perform poorly when tested within graph contrastive learning or graph prompt learning environments. Furthermore, these simple generators often fail to utilize complex structural information or node diversity within the graph data. These constraints limit the attack success rates of such methods in general testing scenarios. Therefore, to address these limitations, we propose Cross-Paradigm Graph Backdoor Attacks with Promptable Subgraph Triggers(CP-GBA), a new transferable graph backdoor attack that employs graph prompt learning(GPL) to train a set of universal subgraph triggers. First, we distill a compact yet expressive trigger set from target graphs, which is structured as a queryable repository, by jointly enforcing class-awareness, feature richness, and structural fidelity. Second, we conduct the first exploration of the theoretical transferability of GPL to train these triggers under prompt-based objectives, enabling effective generalization to diverse and unseen test-time paradigms. Extensive experiments across multiple real-world datasets and defense scenarios show that CP-GBA achieves state-of-the-art attack success rates.
CFBenchmark-MM: Chinese Financial Assistant Benchmark for Multimodal Large Language Model
Jun 16, 2025Multimodal Large Language Models (MLLMs) have rapidly evolved with the growth of Large Language Models (LLMs) and are now applied in various fields. In finance, the integration of diverse modalities such as text, charts, and tables is crucial for accurate and efficient decision-making. Therefore, an effective evaluation system that incorporates these data types is essential for advancing financial application. In this paper, we introduce CFBenchmark-MM, a Chinese multimodal financial benchmark with over 9,000 image-question pairs featuring tables, histogram charts, line charts, pie charts, and structural diagrams. Additionally, we develop a staged evaluation system to assess MLLMs in handling multimodal information by providing different visual content step by step. Despite MLLMs having inherent financial knowledge, experimental results still show limited efficiency and robustness in handling multimodal financial context. Further analysis on incorrect responses reveals the misinterpretation of visual content and the misunderstanding of financial concepts are the primary issues. Our research validates the significant, yet underexploited, potential of MLLMs in financial analysis, highlighting the need for further development and domain-specific optimization to encourage the enhanced use in financial domain.
FinLMM-R1: Enhancing Financial Reasoning in LMM through Scalable Data and Reward Design
Jun 16, 2025Large Multimodal Models (LMMs) demonstrate significant cross-modal reasoning capabilities. However, financial applications face challenges due to the lack of high-quality multimodal reasoning datasets and the inefficiency of existing training paradigms for reasoning enhancement. To address these issues, we propose an integrated framework, FinLMM-R1, combining an automated and scalable pipeline for data construction with enhanced training strategies to improve the multimodal reasoning of LMM. The Automated and Scalable Pipeline (ASP) resolves textual-visual misalignment in financial reports through a separate paradigm of question-answer generation and image-question alignment, ensuring data integrity and extraction efficiency. Through ASP, we collect 89,378 aligned image-question pairs from 23,397 financial reports, covering tasks such as arithmetic reasoning, statistics reasoning, financial explanation, and financial knowledge. Moreover, we introduce the Thinking with Adversarial Reward in LMM (TAR-LMM), extending the prior two-stage training framework [1] with additional reward mechanisms. In the first stage, we focus on text-only tasks with format and accuracy rewards to guide the model in generating well-structured thinking contents. In the second stage, we construct multi-image contrastive samples with additional reward components including image selection, thinking content length, and adversarial reward to jointly optimize the LMM across visual perception, reasoning efficiency, and logical coherence. Extensive experiments on 7 benchmarks show ASP-derived dataset and training framework significantly improve answer accuracy and reasoning depth over existing reasoning LMMs in both general and financial multimodal contexts.
ALFEE: Adaptive Large Foundation Model for EEG Representation
May 07, 2025While foundation models excel in text, image, and video domains, the critical biological signals, particularly electroencephalography(EEG), remain underexplored. EEG benefits neurological research with its high temporal resolution, operational practicality, and safety profile. However, low signal-to-noise ratio, inter-subject variability, and cross-paradigm differences hinder the generalization of current models. Existing methods often employ simplified strategies, such as a single loss function or a channel-temporal joint representation module, and suffer from a domain gap between pretraining and evaluation tasks that compromises efficiency and adaptability. To address these limitations, we propose the Adaptive Large Foundation model for EEG signal representation(ALFEE) framework, a novel hybrid transformer architecture with two learning stages for robust EEG representation learning. ALFEE employs a hybrid attention that separates channel-wise feature aggregation from temporal dynamics modeling, enabling robust EEG representation with variable channel configurations. A channel encoder adaptively compresses variable channel information, a temporal encoder captures task-guided evolution, and a hybrid decoder reconstructs signals in both temporal and frequency domains. During pretraining, ALFEE optimizes task prediction, channel and temporal mask reconstruction, and temporal forecasting to enhance multi-scale and multi-channel representation. During fine-tuning, a full-model adaptation with a task-specific token dictionary and a cross-attention layer boosts performance across multiple tasks. After 25,000 hours of pretraining, extensive experimental results on six downstream EEG tasks demonstrate the superior performance of ALFEE over existing models. Our ALFEE framework establishes a scalable foundation for biological signal analysis with implementation at https://github.com/xw1216/ALFEE.
FinTSB: A Comprehensive and Practical Benchmark for Financial Time Series Forecasting
Feb 26, 2025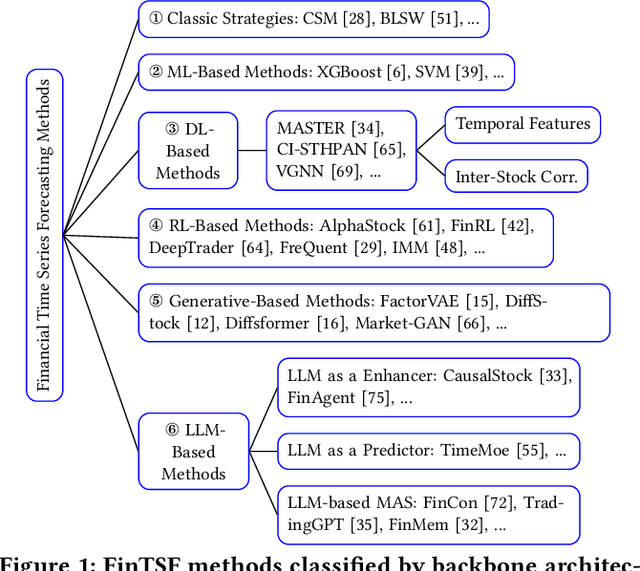



Financial time series (FinTS) record the behavior of human-brain-augmented decision-making, capturing valuable historical information that can be leveraged for profitable investment strategies. Not surprisingly, this area has attracted considerable attention from researchers, who have proposed a wide range of methods based on various backbones. However, the evaluation of the area often exhibits three systemic limitations: 1. Failure to account for the full spectrum of stock movement patterns observed in dynamic financial markets. (Diversity Gap), 2. The absence of unified assessment protocols undermines the validity of cross-study performance comparisons. (Standardization Deficit), and 3. Neglect of critical market structure factors, resulting in inflated performance metrics that lack practical applicability. (Real-World Mismatch). Addressing these limitations, we propose FinTSB, a comprehensive and practical benchmark for financial time series forecasting (FinTSF). To increase the variety, we categorize movement patterns into four specific parts, tokenize and pre-process the data, and assess the data quality based on some sequence characteristics. To eliminate biases due to different evaluation settings, we standardize the metrics across three dimensions and build a user-friendly, lightweight pipeline incorporating methods from various backbones. To accurately simulate real-world trading scenarios and facilitate practical implementation, we extensively model various regulatory constraints, including transaction fees, among others. Finally, we conduct extensive experiments on FinTSB, highlighting key insights to guide model selection under varying market conditions. Overall, FinTSB provides researchers with a novel and comprehensive platform for improving and evaluating FinTSF methods. The code is available at https://github.com/TongjiFinLab/FinTSBenchmark.
MVC-VPR: Mutual Learning of Viewpoint Classification and Visual Place Recognition
Dec 13, 2024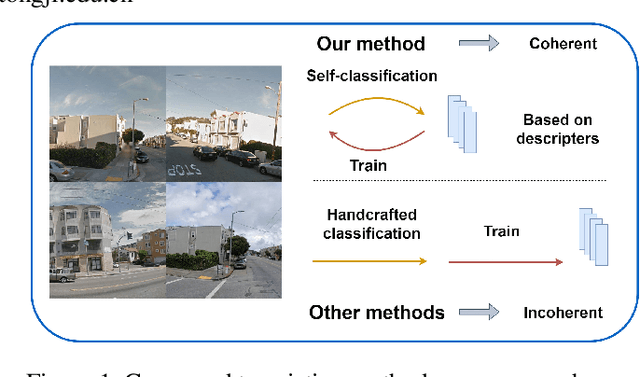
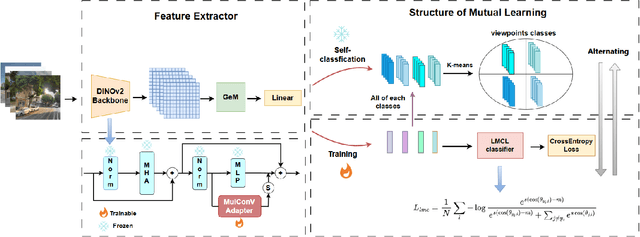
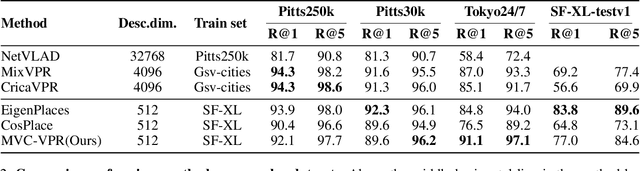
Visual Place Recognition (VPR) aims to robustly identify locations by leveraging image retrieval based on descriptors encoded from environmental images. However, drastic appearance changes of images captured from different viewpoints at the same location pose incoherent supervision signals for descriptor learning, which severely hinder the performance of VPR. Previous work proposes classifying images based on manually defined rules or ground truth labels for viewpoints, followed by descriptor training based on the classification results. However, not all datasets have ground truth labels of viewpoints and manually defined rules may be suboptimal, leading to degraded descriptor performance.To address these challenges, we introduce the mutual learning of viewpoint self-classification and VPR. Starting from coarse classification based on geographical coordinates, we progress to finer classification of viewpoints using simple clustering techniques. The dataset is partitioned in an unsupervised manner while simultaneously training a descriptor extractor for place recognition. Experimental results show that this approach almost perfectly partitions the dataset based on viewpoints, thus achieving mutually reinforcing effects. Our method even excels state-of-the-art (SOTA) methods that partition datasets using ground truth labels.
HGL: Hierarchical Geometry Learning for Test-time Adaptation in 3D Point Cloud Segmentation
Jul 17, 2024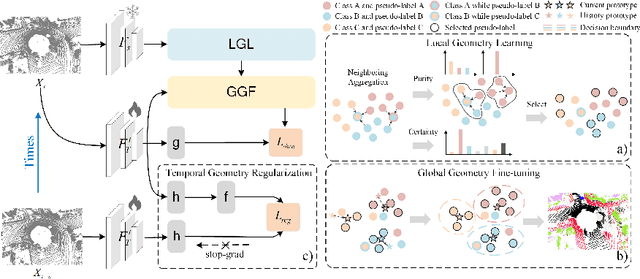
3D point cloud segmentation has received significant interest for its growing applications. However, the generalization ability of models suffers in dynamic scenarios due to the distribution shift between test and training data. To promote robustness and adaptability across diverse scenarios, test-time adaptation (TTA) has recently been introduced. Nevertheless, most existing TTA methods are developed for images, and limited approaches applicable to point clouds ignore the inherent hierarchical geometric structures in point cloud streams, i.e., local (point-level), global (object-level), and temporal (frame-level) structures. In this paper, we delve into TTA in 3D point cloud segmentation and propose a novel Hierarchical Geometry Learning (HGL) framework. HGL comprises three complementary modules from local, global to temporal learning in a bottom-up manner.Technically, we first construct a local geometry learning module for pseudo-label generation. Next, we build prototypes from the global geometry perspective for pseudo-label fine-tuning. Furthermore, we introduce a temporal consistency regularization module to mitigate negative transfer. Extensive experiments on four datasets demonstrate the effectiveness and superiority of our HGL. Remarkably, on the SynLiDAR to SemanticKITTI task, HGL achieves an overall mIoU of 46.91\%, improving GIPSO by 3.0\% and significantly reducing the required adaptation time by 80\%. The code is available at https://github.com/tpzou/HGL.
GeoNLF: Geometry guided Pose-Free Neural LiDAR Fields
Jul 08, 2024Although recent efforts have extended Neural Radiance Fields (NeRF) into LiDAR point cloud synthesis, the majority of existing works exhibit a strong dependence on precomputed poses. However, point cloud registration methods struggle to achieve precise global pose estimation, whereas previous pose-free NeRFs overlook geometric consistency in global reconstruction. In light of this, we explore the geometric insights of point clouds, which provide explicit registration priors for reconstruction. Based on this, we propose Geometry guided Neural LiDAR Fields(GeoNLF), a hybrid framework performing alternately global neural reconstruction and pure geometric pose optimization. Furthermore, NeRFs tend to overfit individual frames and easily get stuck in local minima under sparse-view inputs. To tackle this issue, we develop a selective-reweighting strategy and introduce geometric constraints for robust optimization. Extensive experiments on NuScenes and KITTI-360 datasets demonstrate the superiority of GeoNLF in both novel view synthesis and multi-view registration of low-frequency large-scale point clouds.
RCDN: Towards Robust Camera-Insensitivity Collaborative Perception via Dynamic Feature-based 3D Neural Modeling
May 27, 2024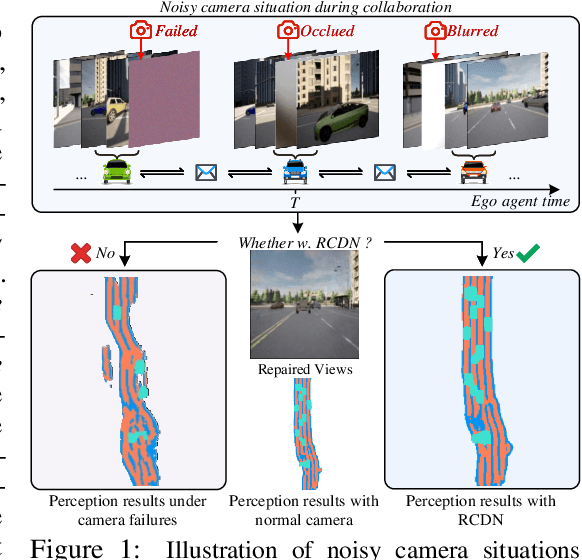
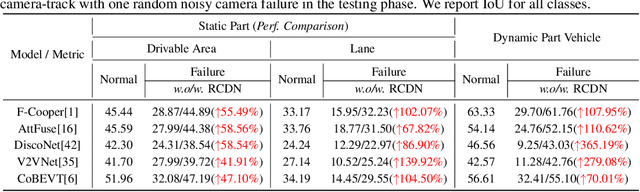
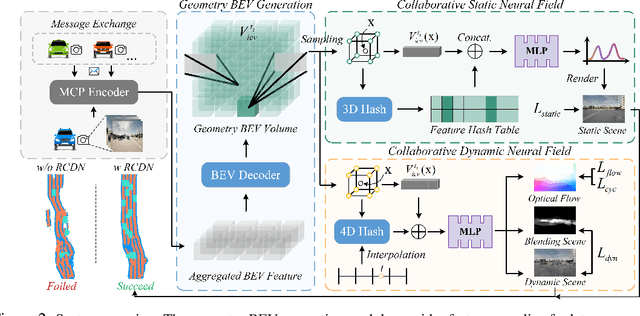
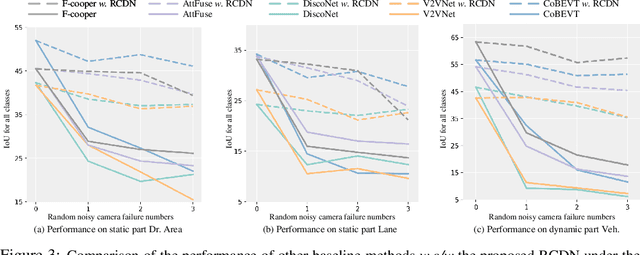
Collaborative perception is dedicated to tackling the constraints of single-agent perception, such as occlusions, based on the multiple agents' multi-view sensor inputs. However, most existing works assume an ideal condition that all agents' multi-view cameras are continuously available. In reality, cameras may be highly noisy, obscured or even failed during the collaboration. In this work, we introduce a new robust camera-insensitivity problem: how to overcome the issues caused by the failed camera perspectives, while stabilizing high collaborative performance with low calibration cost? To address above problems, we propose RCDN, a Robust Camera-insensitivity collaborative perception with a novel Dynamic feature-based 3D Neural modeling mechanism. The key intuition of RCDN is to construct collaborative neural rendering field representations to recover failed perceptual messages sent by multiple agents. To better model collaborative neural rendering field, RCDN first establishes a geometry BEV feature based time-invariant static field with other agents via fast hash grid modeling. Based on the static background field, the proposed time-varying dynamic field can model corresponding motion vectors for foregrounds with appropriate positions. To validate RCDN, we create OPV2V-N, a new large-scale dataset with manual labelling under different camera failed scenarios. Extensive experiments conducted on OPV2V-N show that RCDN can be ported to other baselines and improve their robustness in extreme camera-insensitivity settings. Our code and datasets will be available soon.
POWQMIX: Weighted Value Factorization with Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
May 15, 2024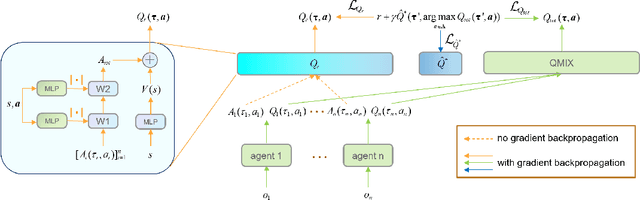
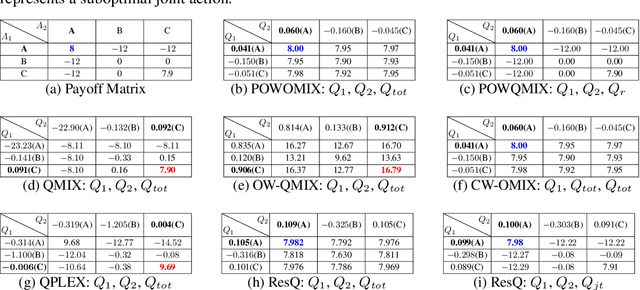
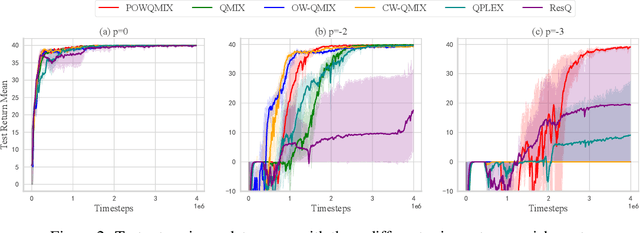
Value function factorization methods are commonly used in cooperative multi-agent reinforcement learning, with QMIX receiving significant attention. Many QMIX-based methods introduce monotonicity constraints between the joint action value and individual action values to achieve decentralized execution. However, such constraints limit the representation capacity of value factorization, restricting the joint action values it can represent and hindering the learning of the optimal policy. To address this challenge, we propose the Potentially Optimal joint actions Weighted QMIX (POWQMIX) algorithm, which recognizes the potentially optimal joint actions and assigns higher weights to the corresponding losses of these joint actions during training. We theoretically prove that with such a weighted training approach the optimal policy is guaranteed to be recovered. Experiments in matrix games, predator-prey, and StarCraft II Multi-Agent Challenge environments demonstrate that our algorithm outperforms the state-of-the-art value-based multi-agent reinforcement learning methods.