 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSAIC-Net: A Multi-Scale Attention and Imbalance-Aware Contrastive Network for ECG-Based Myocardial Substrate Abnormality Detection
Jun 04, 2026Myocardial substrate abnormalities, such as myocardial scar and myocardial infarction (MI), are associated with adverse cardiovascular outcomes. Electrocardiography (ECG) provides a low-cost and widely available tool for detecting these abnormalities, but ECG-based detection remains challenging due to heterogeneous lead-dependent manifestations, high-dimensional multi-lead signals, class imbalance, and the limited interpretability of deep learning models. We propose a multi-scale attention-enhanced convolutional network (MSAIC-Net) for ECG-based myocardial substrate abnormality detection. MSAIC-Net employs parallel atrous convolutional branches to extract ECG features across multiple temporal receptive fields. %, enabling the model to capture both local and longer-range temporal patterns. Channel attention is then used to adaptively reweight informative lead-wise and feature-channel representations. To address class imbalance and improve feature separability, we introduce a novel imbalance-aware supervised contrastive learning strategy that encourages samples from the same class to form compact representations while increasing separation between abnormal and normal samples. Lead-wise permutation importance is further incorporated to quantify the contribution of each ECG lead and improve model interpretability. The proposed method was evaluated on two complementary datasets: a low-data institutional cohort from the University of Virginia (UVA) Health System for myocardial scar classification and the large-scale public PTB-XL dataset from PhysioNet for MI identification. Experimental results show that MSAIC-Net outperforms baseline models, with particularly pronounced improvements in the low-data UVA cohort. Overall, the proposed framework provides an effective and interpretable approach for ECG-based detection of myocardial substrate abnormalities.
Contextual Distributionally Robust Optimization with Causal and Continuous Structure: An Interpretable and Tractable Approach
Jan 16, 2026In this paper, we introduce a framework for contextual distributionally robust optimization (DRO) that considers the causal and continuous structure of the underlying distribution by developing interpretable and tractable decision rules that prescribe decisions using covariates. We first introduce the causal Sinkhorn discrepancy (CSD), an entropy-regularized causal Wasserstein distance that encourages continuous transport plans while preserving the causal consistency. We then formulate a contextual DRO model with a CSD-based ambiguity set, termed Causal Sinkhorn DRO (Causal-SDRO), and derive its strong dual reformulation where the worst-case distribution is characterized as a mixture of Gibbs distributions. To solve the corresponding infinite-dimensional policy optimization, we propose the Soft Regression Forest (SRF) decision rule, which approximates optimal policies within arbitrary measurable function spaces. The SRF preserves the interpretability of classical decision trees while being fully parametric, differentiable, and Lipschitz smooth, enabling intrinsic interpretation from both global and local perspectives. To solve the Causal-SDRO with parametric decision rules, we develop an efficient stochastic compositional gradient algorithm that converges to an $\varepsilon$-stationary point at a rate of $O(\varepsilon^{-4})$, matching the convergence rate of standard stochastic gradient descent. Finally, we validate our method through numerical experiments on synthetic and real-world datasets, demonstrating its superior performance and interpretability.
MVC-VPR: Mutual Learning of Viewpoint Classification and Visual Place Recognition
Dec 13, 2024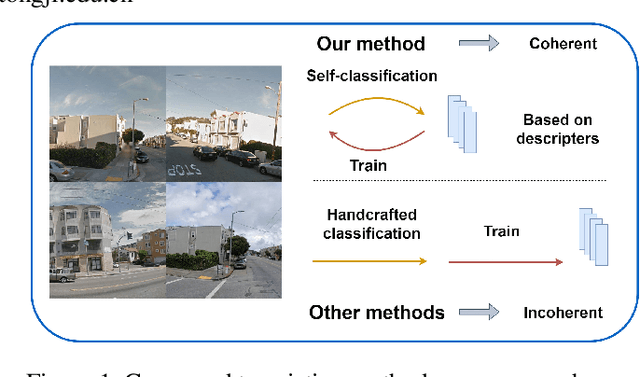
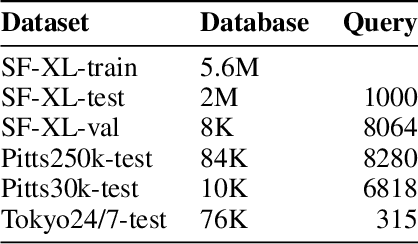
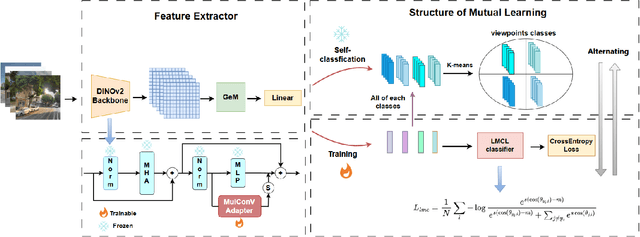
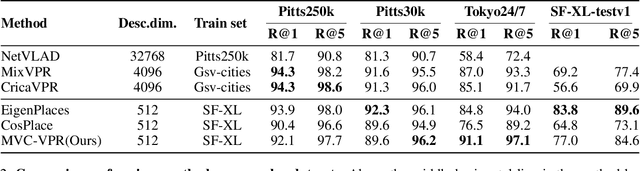
Visual Place Recognition (VPR) aims to robustly identify locations by leveraging image retrieval based on descriptors encoded from environmental images. However, drastic appearance changes of images captured from different viewpoints at the same location pose incoherent supervision signals for descriptor learning, which severely hinder the performance of VPR. Previous work proposes classifying images based on manually defined rules or ground truth labels for viewpoints, followed by descriptor training based on the classification results. However, not all datasets have ground truth labels of viewpoints and manually defined rules may be suboptimal, leading to degraded descriptor performance.To address these challenges, we introduce the mutual learning of viewpoint self-classification and VPR. Starting from coarse classification based on geographical coordinates, we progress to finer classification of viewpoints using simple clustering techniques. The dataset is partitioned in an unsupervised manner while simultaneously training a descriptor extractor for place recognition. Experimental results show that this approach almost perfectly partitions the dataset based on viewpoints, thus achieving mutually reinforcing effects. Our method even excels state-of-the-art (SOTA) methods that partition datasets using ground truth labels.
An Aerial Transport System in Marine GNSS-Denied Environment
Nov 03, 2024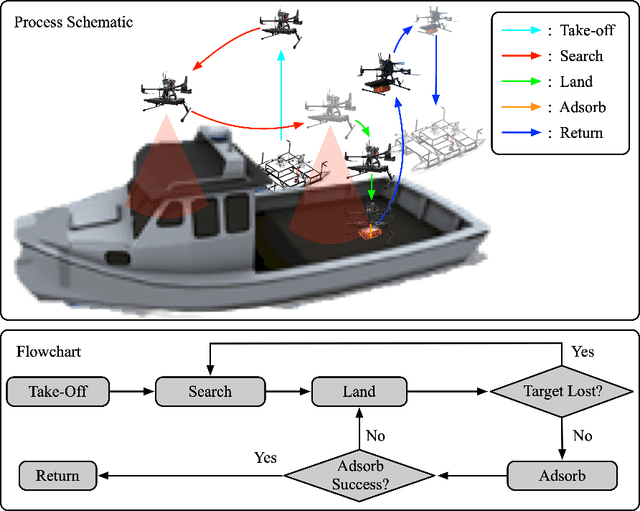
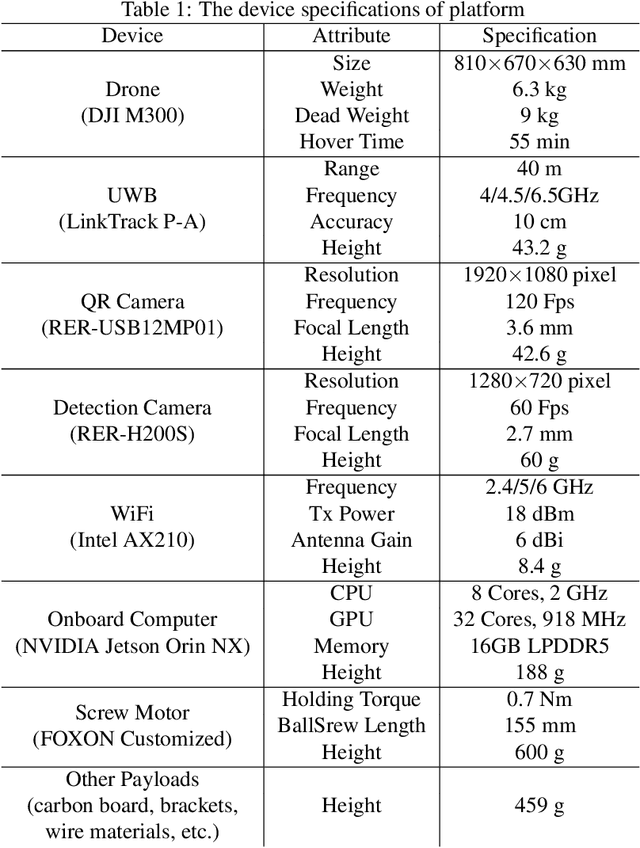
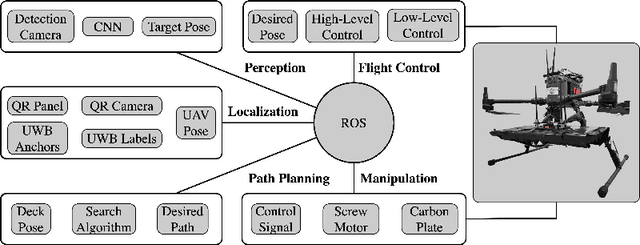

This paper presents an autonomous aerial system specifically engineered for operation in challenging marine GNSS-denied environments, aimed at transporting small cargo from a target vessel. In these environments, characterized by weakly textured sea surfaces with few feature points, chaotic deck oscillations due to waves, and significant wind gusts, conventional navigation methods often prove inadequate. Leveraging the DJI M300 platform, our system is designed to autonomously navigate and transport cargo while overcoming these environmental challenges. In particular, this paper proposes an anchor-based localization method using ultrawideband (UWB) and QR codes facilities, which decouples the UAV's attitude from that of the moving landing platform, thus reducing control oscillations caused by platform movement. Additionally, a motor-driven attachment mechanism for cargo is designed, which enhances the UAV's field of view during descent and ensures a reliable attachment to the cargo upon landing. The system's reliability and effectiveness were progressively enhanced through multiple outdoor experimental iterations and were validated by the successful cargo transport during the 2024 Mohamed BinZayed International Robotics Challenge (MBZIRC2024) competition. Crucially, the system addresses uncertainties and interferences inherent in maritime transportation missions without prior knowledge of cargo locations on the deck and with strict limitations on intervention throughout the transportation.
VNI-Net: Vector Neurons-based Rotation-Invariant Descriptor for LiDAR Place Recognition
Aug 24, 2023LiDAR-based place recognition plays a crucial role in Simultaneous Localization and Mapping (SLAM) and LiDAR localization. Despite the emergence of various deep learning-based and hand-crafting-based methods, rotation-induced place recognition failure remains a critical challenge. Existing studies address this limitation through specific training strategies or network structures. However, the former does not produce satisfactory results, while the latter focuses mainly on the reduced problem of SO(2) rotation invariance. Methods targeting SO(3) rotation invariance suffer from limitations in discrimination capability. In this paper, we propose a new method that employs Vector Neurons Network (VNN) to achieve SO(3) rotation invariance. We first extract rotation-equivariant features from neighboring points and map low-dimensional features to a high-dimensional space through VNN. Afterwards, we calculate the Euclidean and Cosine distance in the rotation-equivariant feature space as rotation-invariant feature descriptors. Finally, we aggregate the features using GeM pooling to obtain global descriptors. To address the significant information loss when formulating rotation-invariant descriptors, we propose computing distances between features at different layers within the Euclidean space neighborhood. This greatly improves the discriminability of the point cloud descriptors while ensuring computational efficiency. Experimental results on public datasets show that our approach significantly outperforms other baseline methods implementing rotation invariance, while achieving comparable results with current state-of-the-art place recognition methods that do not consider rotation issues.
Learning Sequence Descriptor based on Spatiotemporal Attention for Visual Place Recognition
May 19, 2023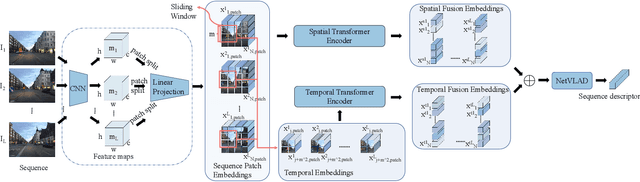
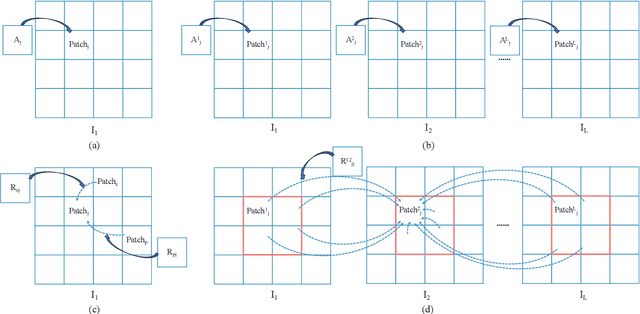
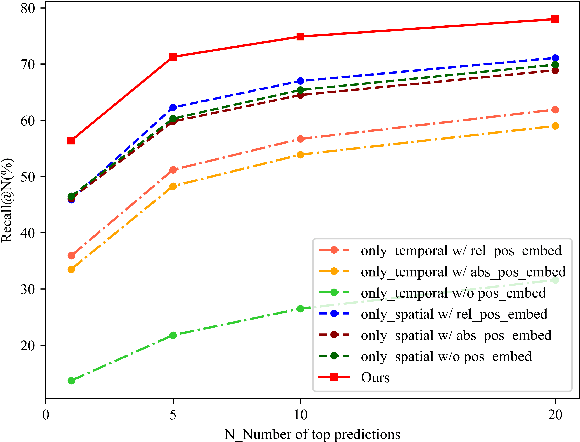
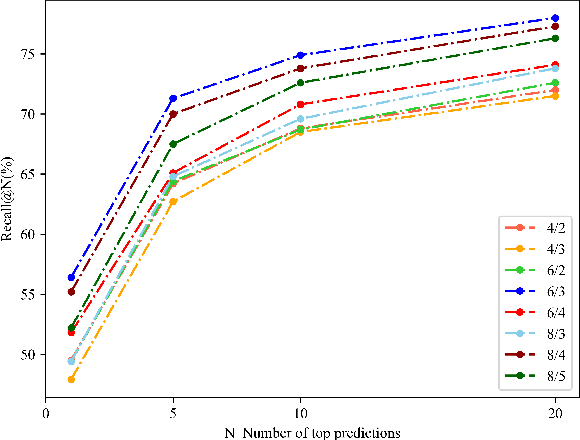
Sequence-based visual place recognition (sVPR) aims to match frame sequences with frames stored in a reference map for localization. Existing methods include sequence matching and sequence descriptor-based retrieval. The former is based on the assumption of constant velocity, which is difficult to hold in real scenarios and does not get rid of the intrinsic single frame descriptor mismatch. The latter solves this problem by extracting a descriptor for the whole sequence, but current sequence descriptors are only constructed by feature aggregation of multi-frames, with no temporal information interaction. In this paper, we propose a sequential descriptor extraction method to fuse spatiotemporal information effectively and generate discriminative descriptors. Specifically, similar features on the same frame focu on each other and learn space structure, and the same local regions of different frames learn local feature changes over time. And we use sliding windows to control the temporal self-attention range and adpot relative position encoding to construct the positional relationships between different features, which allows our descriptor to capture the inherent dynamics in the frame sequence and local feature motion.
Patch-NetVLAD+: Learned patch descriptor and weighted matching strategy for place recognition
Feb 11, 2022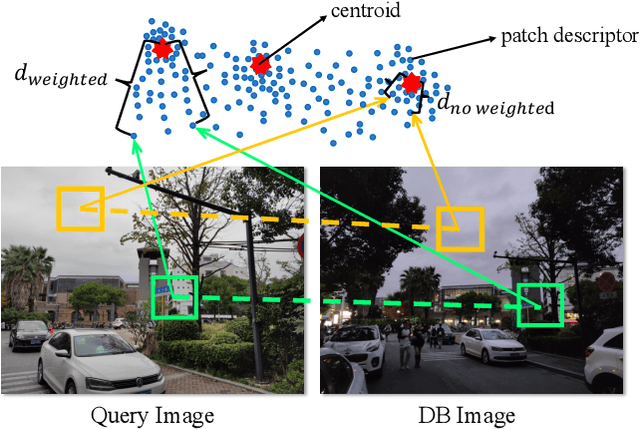
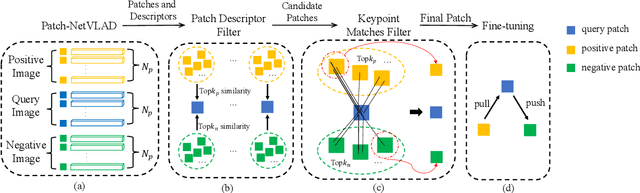
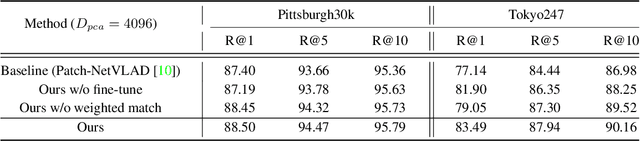
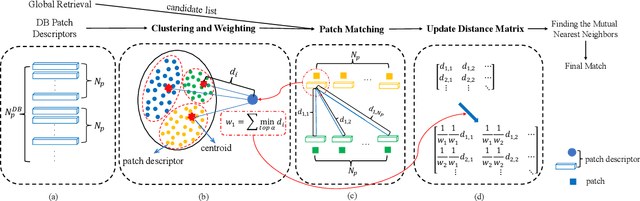
Visual Place Recognition (VPR) in areas with similar scenes such as urban or indoor scenarios is a major challenge. Existing VPR methods using global descriptors have difficulty capturing local specific regions (LSR) in the scene and are therefore prone to localization confusion in such scenarios. As a result, finding the LSR that are critical for location recognition becomes key. To address this challenge, we introduced Patch-NetVLAD+, which was inspired by patch-based VPR researches. Our method proposed a fine-tuning strategy with triplet loss to make NetVLAD suitable for extracting patch-level descriptors. Moreover, unlike existing methods that treat all patches in an image equally, our method extracts patches of LSR, which present less frequently throughout the dataset, and makes them play an important role in VPR by assigning proper weights to them. Experiments on Pittsburgh30k and Tokyo247 datasets show that our approach achieved up to 6.35\% performance improvement than existing patch-based methods.