 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sequence Descriptor based on Spatiotemporal Attention for Visual Place Recognition
Paper and Code
May 19, 2023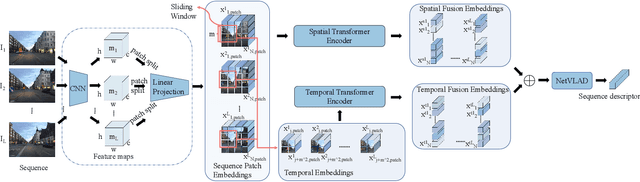
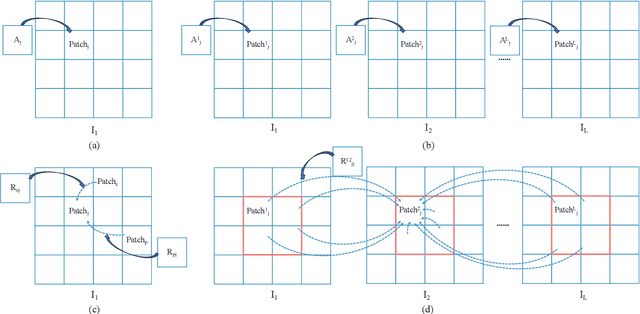
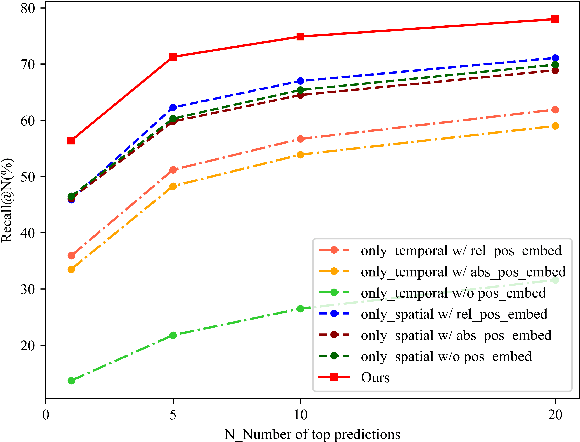
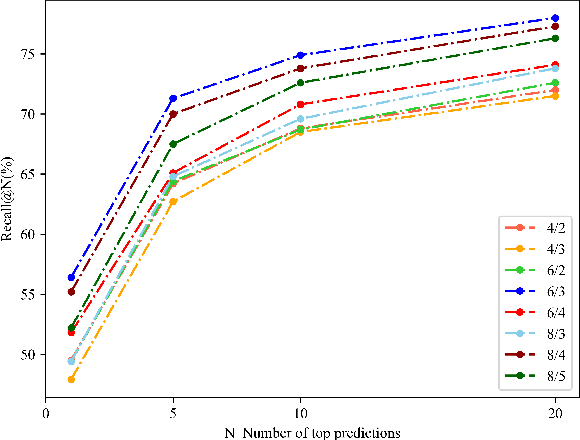
Sequence-based visual place recognition (sVPR) aims to match frame sequences with frames stored in a reference map for localization. Existing methods include sequence matching and sequence descriptor-based retrieval. The former is based on the assumption of constant velocity, which is difficult to hold in real scenarios and does not get rid of the intrinsic single frame descriptor mismatch. The latter solves this problem by extracting a descriptor for the whole sequence, but current sequence descriptors are only constructed by feature aggregation of multi-frames, with no temporal information interaction. In this paper, we propose a sequential descriptor extraction method to fuse spatiotemporal information effectively and generate discriminative descriptors. Specifically, similar features on the same frame focu on each other and learn space structure, and the same local regions of different frames learn local feature changes over time. And we use sliding windows to control the temporal self-attention range and adpot relative position encoding to construct the positional relationships between different features, which allows our descriptor to capture the inherent dynamics in the frame sequence and local feature motion.