 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMU-GeNeRF: Multi-view Uncertainty-guided Generalizable Neural Radiance Fields for Distractor-aware Scene
Apr 20, 2026Generalizable Neural Radiance Fields (GeNeRFs) enable high-quality scene reconstruction from sparse views and can generalize to unseen scenes. However, in real-world settings, transient distractors break cross-view structural consistency, corrupting supervision and degrading reconstruction quality. Existing distractor-free NeRF methods rely on per-scene optimization and estimate uncertainty from per-view reconstruction errors, which are not reliable for GeNeRFs and often misjudge inconsistent static structures as distractors. To this end, we propose MU-GeNeRF, a Multi-view Uncertainty-guided distractor-aware GeNeRF framework designed to alleviate GeNeRF's robust modeling challenges in the presence of transient distractions. We decompose distractor awareness into two complementary uncertainty components: Source-view Uncertainty, which captures structural discrepancies across source views caused by viewpoint changes or dynamic factors; and Target-view Uncertainty, which detects observation anomalies in the target image induced by transient distractors.These two uncertainties address distinct error sources and are combined through a heteroscedastic reconstruction loss, which guides the model to adaptively modulate supervision, enabling more robust distractor suppression and geometric modeling.Extensive experiments show that our method not only surpasses existing GeNeRFs but also achieves performance comparable to scene-specific distractor-free NeRFs.
VNI-Net: Vector Neurons-based Rotation-Invariant Descriptor for LiDAR Place Recognition
Aug 24, 2023LiDAR-based place recognition plays a crucial role in Simultaneous Localization and Mapping (SLAM) and LiDAR localization. Despite the emergence of various deep learning-based and hand-crafting-based methods, rotation-induced place recognition failure remains a critical challenge. Existing studies address this limitation through specific training strategies or network structures. However, the former does not produce satisfactory results, while the latter focuses mainly on the reduced problem of SO(2) rotation invariance. Methods targeting SO(3) rotation invariance suffer from limitations in discrimination capability. In this paper, we propose a new method that employs Vector Neurons Network (VNN) to achieve SO(3) rotation invariance. We first extract rotation-equivariant features from neighboring points and map low-dimensional features to a high-dimensional space through VNN. Afterwards, we calculate the Euclidean and Cosine distance in the rotation-equivariant feature space as rotation-invariant feature descriptors. Finally, we aggregate the features using GeM pooling to obtain global descriptors. To address the significant information loss when formulating rotation-invariant descriptors, we propose computing distances between features at different layers within the Euclidean space neighborhood. This greatly improves the discriminability of the point cloud descriptors while ensuring computational efficiency. Experimental results on public datasets show that our approach significantly outperforms other baseline methods implementing rotation invariance, while achieving comparable results with current state-of-the-art place recognition methods that do not consider rotation issues.
Learning Sequence Descriptor based on Spatiotemporal Attention for Visual Place Recognition
May 19, 2023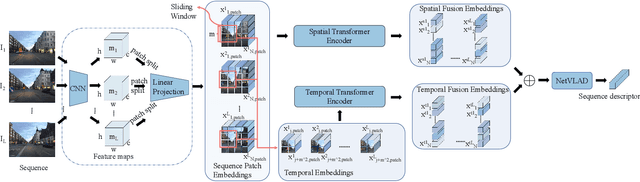
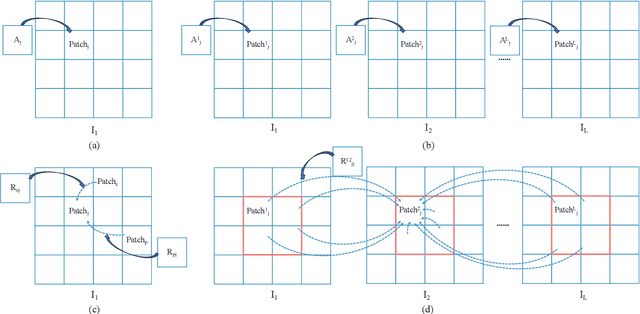
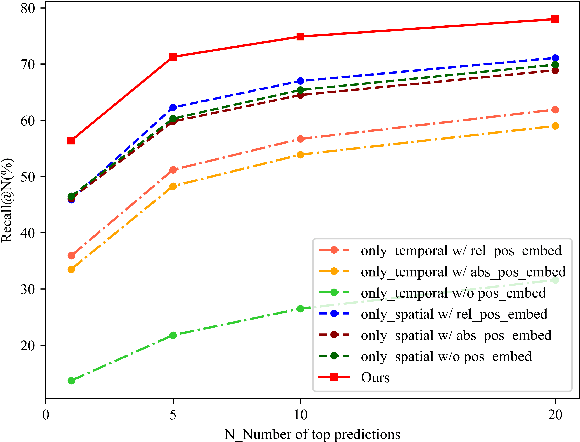
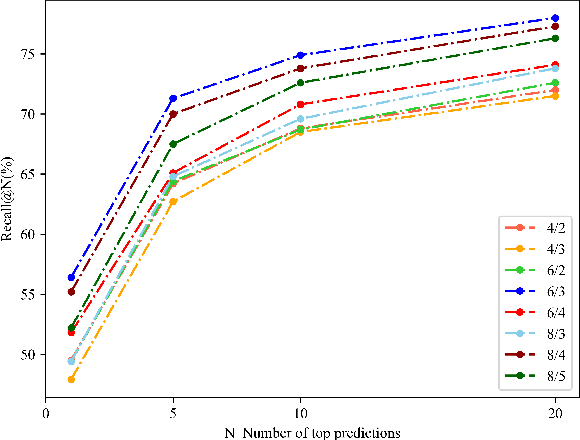
Sequence-based visual place recognition (sVPR) aims to match frame sequences with frames stored in a reference map for localization. Existing methods include sequence matching and sequence descriptor-based retrieval. The former is based on the assumption of constant velocity, which is difficult to hold in real scenarios and does not get rid of the intrinsic single frame descriptor mismatch. The latter solves this problem by extracting a descriptor for the whole sequence, but current sequence descriptors are only constructed by feature aggregation of multi-frames, with no temporal information interaction. In this paper, we propose a sequential descriptor extraction method to fuse spatiotemporal information effectively and generate discriminative descriptors. Specifically, similar features on the same frame focu on each other and learn space structure, and the same local regions of different frames learn local feature changes over time. And we use sliding windows to control the temporal self-attention range and adpot relative position encoding to construct the positional relationships between different features, which allows our descriptor to capture the inherent dynamics in the frame sequence and local feature motion.