 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Attribution Blind Spot: Detecting When Language Models Rely on Memory Rather Than Retrieved Context
May 26, 2026Retrieval-augmented generation promises to ground language model outputs in external evidence, yet the field has no reliable way to verify whether retrieved context actually governs generation -- a prerequisite for any high-stakes deployment. The standard assumption, that context-consistent output implies context-governed output, breaks when the retrieved document overlaps with the model's pretraining data: the model can produce faithful-looking text entirely from parametric memory, and both pathways yield indistinguishable output. We name this failure the attribution blind spot and introduce Computational Reality Monitoring (CRM) to address it. CRM operationalizes a principle adapted from cognitive science's reality monitoring framework: comparing internal representations with and without context reveals membership-conditioned representational divergence that output-level monitors systematically miss. CRM does not certify which source an individual generation used; it detects whether pretraining exposure leaves a measurable internal trajectory signature, establishing a necessary substrate for source attribution. Across nine model variants spanning three families, this divergence concentrates in architecture-specific layer patterns, receives converging support from block-level noise intervention, and generalizes across tasks and datasets while collapsing on domain-confounded benchmarks. The attribution blind spot is measurable and partially addressable: internal representations carry a diagnostic signal invisible at the output level, establishing a foundation for systems whose internal awareness of evidence provenance governs their external behavior.
Detecting Is Not Resolving: The Monitoring Control Gap in Retrieval Augmented LLMs
May 26, 2026Retrieval-augmented LLMs are deployed for tasks where evidence quality determines action safety, yet evaluation protocols assume that single-turn robustness predicts robustness when evidence accumulates across turns. We show this assumption is fundamentally incorrect. Models exhibit a monitoring-control gap: they readily acknowledge contradictory evidence, yet this awareness fails to constrain their final recommendations - detecting epistemic conflict does not imply resolving it safely. Through a multi-turn document accumulation protocol across four model families (1.5B-32B parameters) and over 50,000 turn-level evaluations, we demonstrate that single-turn diagnostics systematically overestimate RAG safety, that contradiction acknowledgement is uncorrelated with safe resolution, a pattern corroborated by targeted human validation, and that no universal prompt fix exists. Converging mechanism evidence - hidden-state probing, attention analysis, and response-strategy taxonomy - points to action selection as the most plausible locus of the deficit: danger-relevant information is internally represented and receives enhanced attention during unsafe generation, yet fails to constrain output behavior. The gap between what models recognize and what they do must be measured and closed before retrieval-augmented systems can be trusted in high-stakes settings.
MU-GeNeRF: Multi-view Uncertainty-guided Generalizable Neural Radiance Fields for Distractor-aware Scene
Apr 20, 2026Generalizable Neural Radiance Fields (GeNeRFs) enable high-quality scene reconstruction from sparse views and can generalize to unseen scenes. However, in real-world settings, transient distractors break cross-view structural consistency, corrupting supervision and degrading reconstruction quality. Existing distractor-free NeRF methods rely on per-scene optimization and estimate uncertainty from per-view reconstruction errors, which are not reliable for GeNeRFs and often misjudge inconsistent static structures as distractors. To this end, we propose MU-GeNeRF, a Multi-view Uncertainty-guided distractor-aware GeNeRF framework designed to alleviate GeNeRF's robust modeling challenges in the presence of transient distractions. We decompose distractor awareness into two complementary uncertainty components: Source-view Uncertainty, which captures structural discrepancies across source views caused by viewpoint changes or dynamic factors; and Target-view Uncertainty, which detects observation anomalies in the target image induced by transient distractors.These two uncertainties address distinct error sources and are combined through a heteroscedastic reconstruction loss, which guides the model to adaptively modulate supervision, enabling more robust distractor suppression and geometric modeling.Extensive experiments show that our method not only surpasses existing GeNeRFs but also achieves performance comparable to scene-specific distractor-free NeRFs.
Stroke Modeling Enables Vectorized Character Generation with Large Vectorized Glyph Model
Nov 14, 2025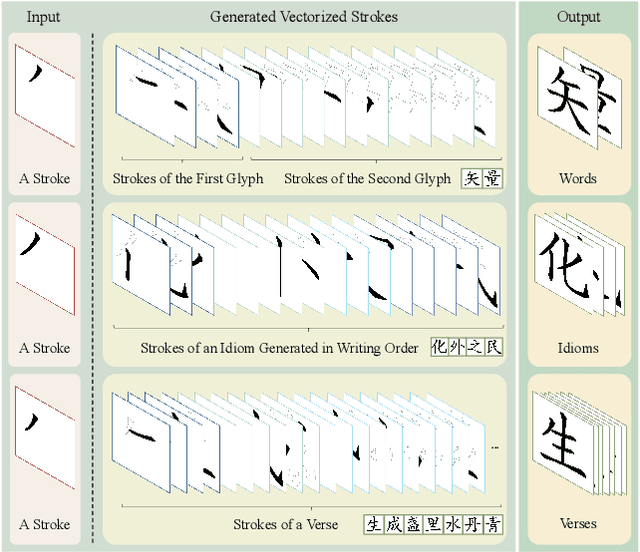
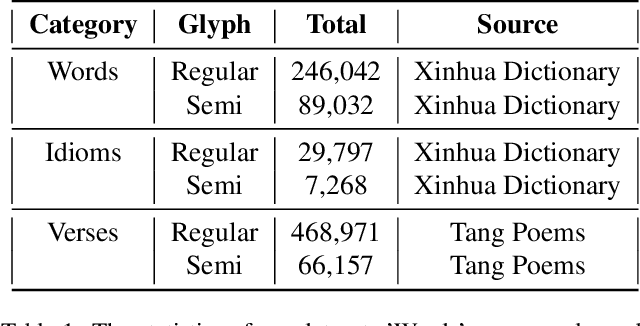
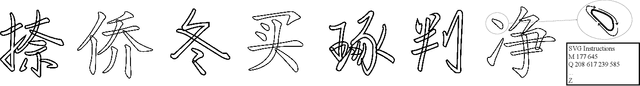
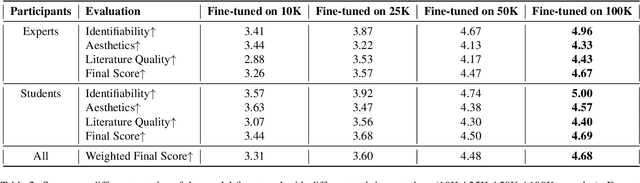
Vectorized glyphs are widely used in poster design, network animation, art display, and various other fields due to their scalability and flexibility. In typography, they are often seen as special sequences composed of ordered strokes. This concept extends to the token sequence prediction abilities of large language models (LLMs), enabling vectorized character generation through stroke modeling. In this paper, we propose a novel Large Vectorized Glyph Model (LVGM) designed to generate vectorized Chinese glyphs by predicting the next stroke. Initially, we encode strokes into discrete latent variables called stroke embeddings. Subsequently, we train our LVGM via fine-tuning DeepSeek LLM by predicting the next stroke embedding. With limited strokes given, it can generate complete characters, semantically elegant words, and even unseen verses in vectorized form. Moreover, we release a new large-scale Chinese SVG dataset containing 907,267 samples based on strokes for dynamically vectorized glyph generation. Experimental results show that our model has scaling behaviors on data scales. Our generated vectorized glyphs have been validated by experts and relevant individuals.
PanTS: The Pancreatic Tumor Segmentation Dataset
Jul 02, 2025PanTS is a large-scale, multi-institutional dataset curated to advance research in pancreatic CT analysis. It contains 36,390 CT scans from 145 medical centers, with expert-validated, voxel-wise annotations of over 993,000 anatomical structures, covering pancreatic tumors, pancreas head, body, and tail, and 24 surrounding anatomical structures such as vascular/skeletal structures and abdominal/thoracic organs. Each scan includes metadata such as patient age, sex, diagnosis, contrast phase, in-plane spacing, slice thickness, etc. AI models trained on PanTS achieve significantly better performance in pancreatic tumor detection, localization, and segmentation compared to those trained on existing public datasets. Our analysis indicates that these gains are directly attributable to the 16x larger-scale tumor annotations and indirectly supported by the 24 additional surrounding anatomical structures. As the largest and most comprehensive resource of its kind, PanTS offers a new benchmark for developing and evaluating AI models in pancreatic CT analysis.
Convex Hull-based Algebraic Constraint for Visual Quadric SLAM
Mar 03, 2025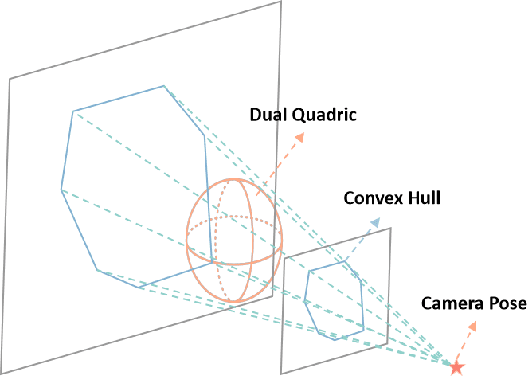

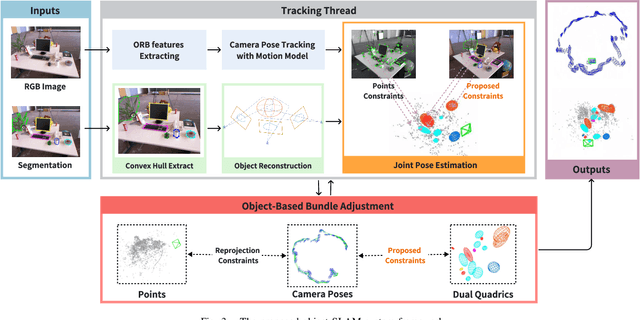

Using Quadrics as the object representation has the benefits of both generality and closed-form projection derivation between image and world spaces. Although numerous constraints have been proposed for dual quadric reconstruction, we found that many of them are imprecise and provide minimal improvements to localization.After scrutinizing the existing constraints, we introduce a concise yet more precise convex hull-based algebraic constraint for object landmarks, which is applied to object reconstruction, frontend pose estimation, and backend bundle adjustment.This constraint is designed to fully leverage precise semantic segmentation, effectively mitigating mismatches between complex-shaped object contours and dual quadrics.Experiments on public datasets demonstrate that our approach is applicable to both monocular and RGB-D SLAM and achieves improved object mapping and localization than existing quadric SLAM methods. The implementation of our method is available at https://github.com/tiev-tongji/convexhull-based-algebraic-constraint.
MVC-VPR: Mutual Learning of Viewpoint Classification and Visual Place Recognition
Dec 13, 2024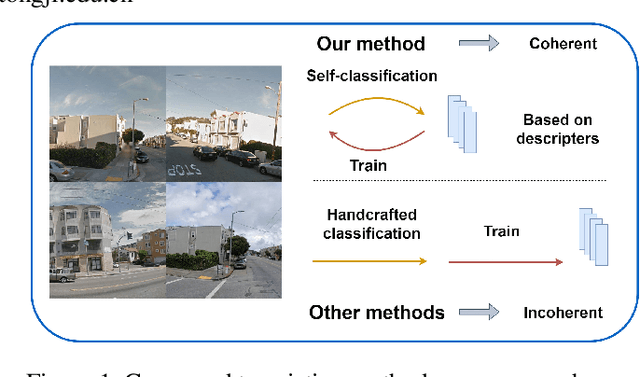
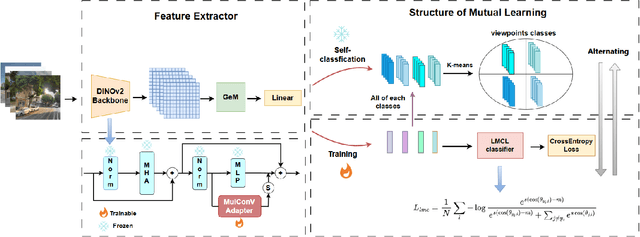
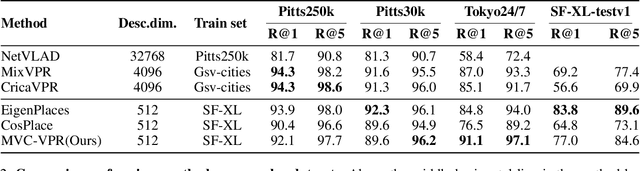
Visual Place Recognition (VPR) aims to robustly identify locations by leveraging image retrieval based on descriptors encoded from environmental images. However, drastic appearance changes of images captured from different viewpoints at the same location pose incoherent supervision signals for descriptor learning, which severely hinder the performance of VPR. Previous work proposes classifying images based on manually defined rules or ground truth labels for viewpoints, followed by descriptor training based on the classification results. However, not all datasets have ground truth labels of viewpoints and manually defined rules may be suboptimal, leading to degraded descriptor performance.To address these challenges, we introduce the mutual learning of viewpoint self-classification and VPR. Starting from coarse classification based on geographical coordinates, we progress to finer classification of viewpoints using simple clustering techniques. The dataset is partitioned in an unsupervised manner while simultaneously training a descriptor extractor for place recognition. Experimental results show that this approach almost perfectly partitions the dataset based on viewpoints, thus achieving mutually reinforcing effects. Our method even excels state-of-the-art (SOTA) methods that partition datasets using ground truth labels.
Exploring Mathematical Extrapolation of Large Language Models with Synthetic Data
Jun 04, 2024



Large Language Models (LLMs) have shown excellent performance in language understanding, text generation, code synthesis, and many other tasks, while they still struggle in complex multi-step reasoning problems, such as mathematical reasoning. In this paper, through a newly proposed arithmetical puzzle problem, we show that the model can perform well on multi-step reasoning tasks via fine-tuning on high-quality synthetic data. Experimental results with the open-llama-3B model on three different test datasets show that not only the model can reach a zero-shot pass@1 at 0.44 on the in-domain dataset, it also demonstrates certain generalization capabilities on the out-of-domain datasets. Specifically, this paper has designed two out-of-domain datasets in the form of extending the numerical range and the composing components of the arithmetical puzzle problem separately. The fine-tuned models have shown encouraging performance on these two far more difficult tasks with the zero-shot pass@1 at 0.33 and 0.35, respectively.
POWQMIX: Weighted Value Factorization with Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
May 15, 2024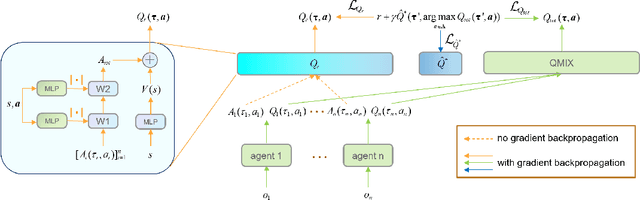
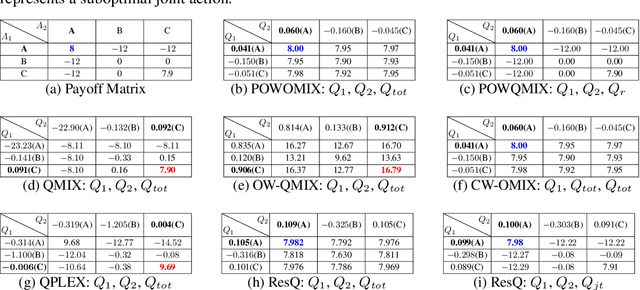
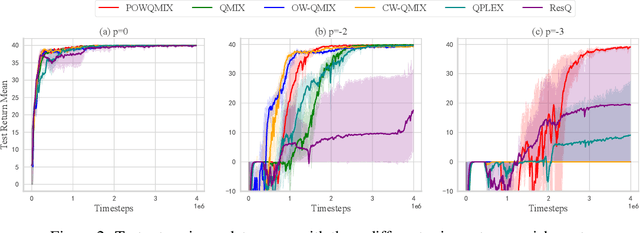
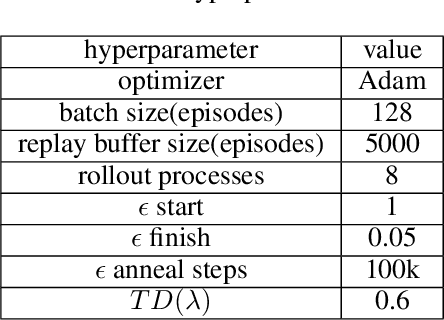
Value function factorization methods are commonly used in cooperative multi-agent reinforcement learning, with QMIX receiving significant attention. Many QMIX-based methods introduce monotonicity constraints between the joint action value and individual action values to achieve decentralized execution. However, such constraints limit the representation capacity of value factorization, restricting the joint action values it can represent and hindering the learning of the optimal policy. To address this challenge, we propose the Potentially Optimal joint actions Weighted QMIX (POWQMIX) algorithm, which recognizes the potentially optimal joint actions and assigns higher weights to the corresponding losses of these joint actions during training. We theoretically prove that with such a weighted training approach the optimal policy is guaranteed to be recovered. Experiments in matrix games, predator-prey, and StarCraft II Multi-Agent Challenge environments demonstrate that our algorithm outperforms the state-of-the-art value-based multi-agent reinforcement learning methods.
LOG-LIO2: A LiDAR-Inertial Odometry with Efficient Uncertainty Analysis
May 02, 2024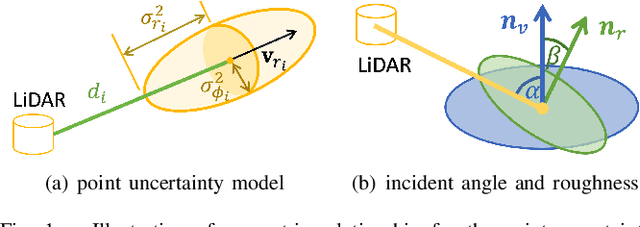
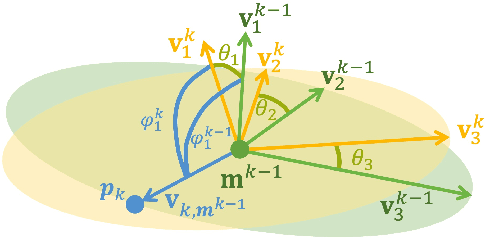
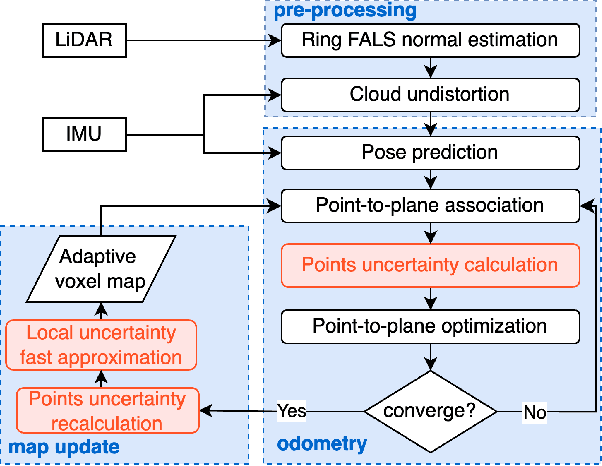
Uncertainty in LiDAR measurements, stemming from factors such as range sensing, is crucial for LIO (LiDAR-Inertial Odometry) systems as it affects the accurate weighting in the loss function. While recent LIO systems address uncertainty related to range sensing, the impact of incident angle on uncertainty is often overlooked by the community. Moreover, the existing uncertainty propagation methods suffer from computational inefficiency. This paper proposes a comprehensive point uncertainty model that accounts for both the uncertainties from LiDAR measurements and surface characteristics, along with an efficient local uncertainty analytical method for LiDAR-based state estimation problem. We employ a projection operator that separates the uncertainty into the ray direction and its orthogonal plane. Then, we derive incremental Jacobian matrices of eigenvalues and eigenvectors w.r.t. points, which enables a fast approximation of uncertainty propagation. This approach eliminates the requirement for redundant traversal of points, significantly reducing the time complexity of uncertainty propagation from $\mathcal{O} (n)$ to $\mathcal{O} (1)$ when a new point is added. Simulations and experiments on public datasets are conducted to validate the accuracy and efficiency of our formulations. The proposed methods have been integrated into a LIO system, which is available at https://github.com/tiev-tongji/LOG-LIO2.