 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Automated Tool for Abdominal CT Body Composition Analysis in Gastrointestinal Cancer Management
Mar 10, 2025



The incidence of gastrointestinal cancers remains significantly high, particularly in China, emphasizing the importance of accurate prognostic assessments and effective treatment strategies. Research shows a strong correlation between abdominal muscle and fat tissue composition and patient outcomes. However, existing manual methods for analyzing abdominal tissue composition are time-consuming and costly, limiting clinical research scalability. To address these challenges, we developed an AI-driven tool for automated analysis of abdominal CT scans to effectively identify and segment muscle, subcutaneous fat, and visceral fat. Our tool integrates a multi-view localization model and a high-precision 2D nnUNet-based segmentation model, demonstrating a localization accuracy of 90% and a Dice Score Coefficient of 0.967 for segmentation. Furthermore, it features an interactive interface that allows clinicians to refine the segmentation results, ensuring high-quality outcomes effectively. Our tool offers a standardized method for effectively extracting critical abdominal tissues, potentially enhancing the management and treatment for gastrointestinal cancers. The code is available at https://github.com/NanXinyu/AI-Tool4Abdominal-Seg.git}{https://github.com/NanXinyu/AI-Tool4Abdominal-Seg.git.
Adaptive Few-shot Prompting for Machine Translation with Pre-trained Language Models
Jan 03, 2025Recently, Large language models (LLMs) with in-context learning have demonstrated remarkable potential in handling neural machine translation. However, existing evidence shows that LLMs are prompt-sensitive and it is sub-optimal to apply the fixed prompt to any input for downstream machine translation tasks. To address this issue, we propose an adaptive few-shot prompting (AFSP) framework to automatically select suitable translation demonstrations for various source input sentences to further elicit the translation capability of an LLM for better machine translation. First, we build a translation demonstration retrieval module based on LLM's embedding to retrieve top-k semantic-similar translation demonstrations from aligned parallel translation corpus. Rather than using other embedding models for semantic demonstration retrieval, we build a hybrid demonstration retrieval module based on the embedding layer of the deployed LLM to build better input representation for retrieving more semantic-related translation demonstrations. Then, to ensure better semantic consistency between source inputs and target outputs, we force the deployed LLM itself to generate multiple output candidates in the target language with the help of translation demonstrations and rerank these candidates. Besides, to better evaluate the effectiveness of our AFSP framework on the latest language and extend the research boundary of neural machine translation, we construct a high-quality diplomatic Chinese-English parallel dataset that consists of 5,528 parallel Chinese-English sentences. Finally, extensive experiments on the proposed diplomatic Chinese-English parallel dataset and the United Nations Parallel Corpus (Chinese-English part) show the effectiveness and superiority of our proposed AFSP.
PropSAM: A Propagation-Based Model for Segmenting Any 3D Objects in Multi-Modal Medical Images
Aug 25, 2024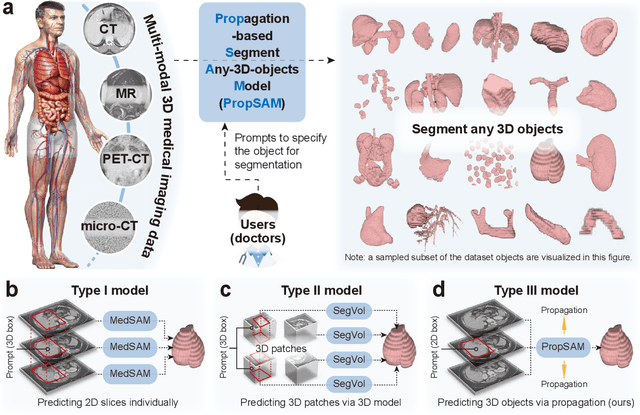
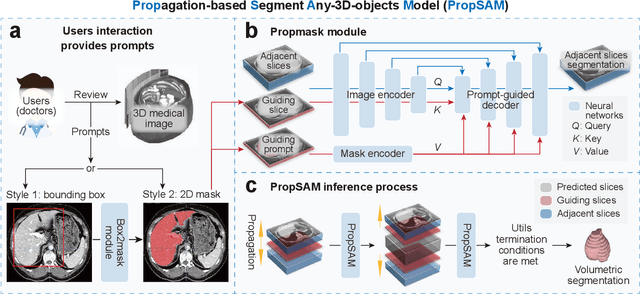
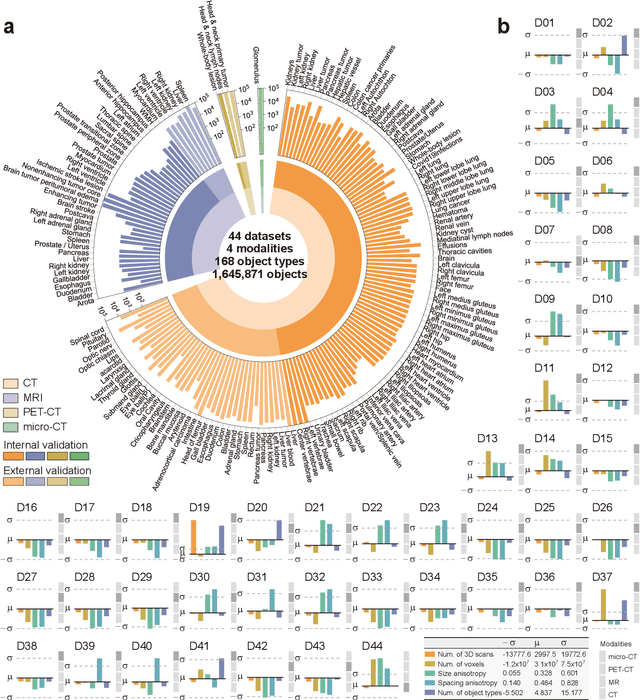
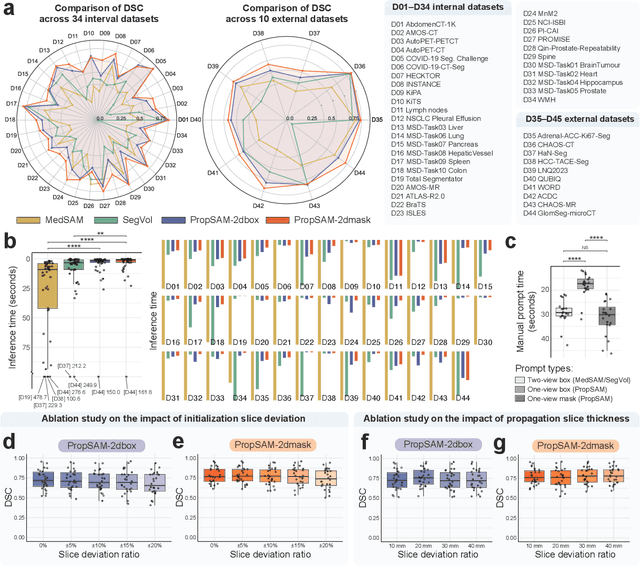
Volumetric segmentation is crucial for medical imaging but is often constrained by labor-intensive manual annotations and the need for scenario-specific model training. Furthermore, existing general segmentation models are inefficient due to their design and inferential approaches. Addressing this clinical demand, we introduce PropSAM, a propagation-based segmentation model that optimizes the use of 3D medical structure information. PropSAM integrates a CNN-based UNet for intra-slice processing with a Transformer-based module for inter-slice propagation, focusing on structural and semantic continuities to enhance segmentation across various modalities. Distinctively, PropSAM operates on a one-view prompt, such as a 2D bounding box or sketch mask, unlike conventional models that require two-view prompts. It has demonstrated superior performance, significantly improving the Dice Similarity Coefficient (DSC) across 44 medical datasets and various imaging modalities, outperforming models like MedSAM and SegVol with an average DSC improvement of 18.1%. PropSAM also maintains stable predictions despite prompt deviations and varying propagation configurations, confirmed by one-way ANOVA tests with P>0.5985 and P>0.6131, respectively. Moreover, PropSAM's efficient architecture enables faster inference speeds (Wilcoxon rank-sum test, P<0.001) and reduces user interaction time by 37.8% compared to two-view prompt models. Its ability to handle irregular and complex objects with robust performance further demonstrates its potential in clinical settings, facilitating more automated and reliable medical imaging analyses with minimal retraining.
Progressive Dual Priori Network for Generalized Breast Tumor Segmentation
Oct 20, 2023


To promote the generalization ability of breast tumor segmentation models, as well as to improve the segmentation performance for breast tumors with smaller size, low-contrast amd irregular shape, we propose a progressive dual priori network (PDPNet) to segment breast tumors from dynamic enhanced magnetic resonance images (DCE-MRI) acquired at different sites. The PDPNet first cropped tumor regions with a coarse-segmentation based localization module, then the breast tumor mask was progressively refined by using the weak semantic priori and cross-scale correlation prior knowledge. To validate the effectiveness of PDPNet, we compared it with several state-of-the-art methods on multi-center datasets. The results showed that, comparing against the suboptimal method, the DSC, SEN, KAPPA and HD95 of PDPNet were improved 3.63\%, 8.19\%, 5.52\%, and 3.66\% respectively. In addition, through ablations, we demonstrated that the proposed localization module can decrease the influence of normal tissues and therefore improve the generalization ability of the model. The weak semantic priors allow focusing on tumor regions to avoid missing small tumors and low-contrast tumors. The cross-scale correlation priors are beneficial for promoting the shape-aware ability for irregual tumors. Thus integrating them in a unified framework improved the multi-center breast tumor segmentation performance.
propnet: Propagating 2D Annotation to 3D Segmentation for Gastric Tumors on CT Scans
May 29, 2023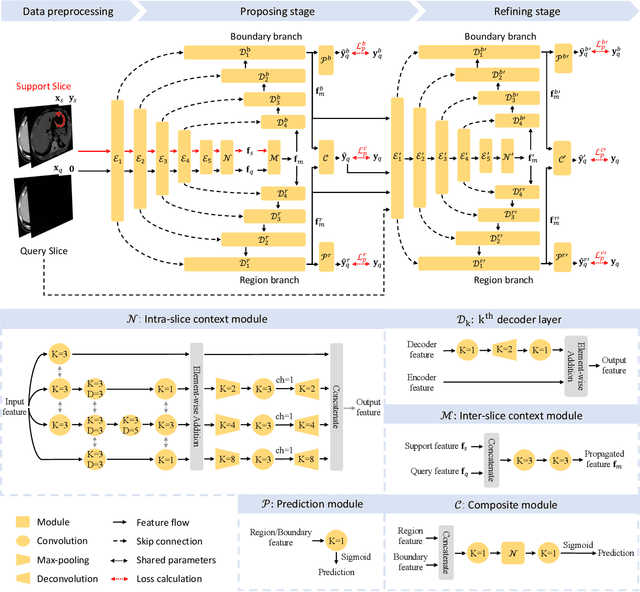
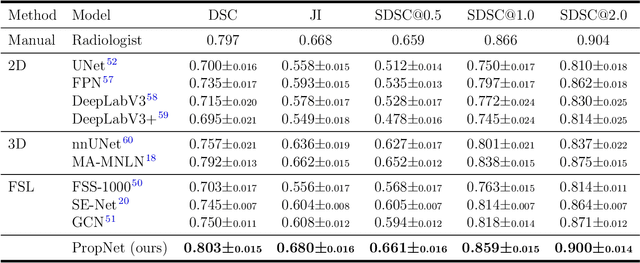
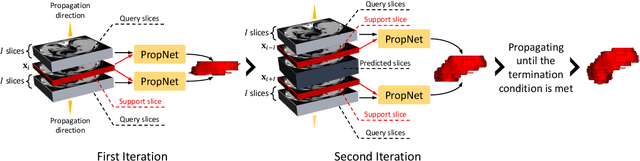

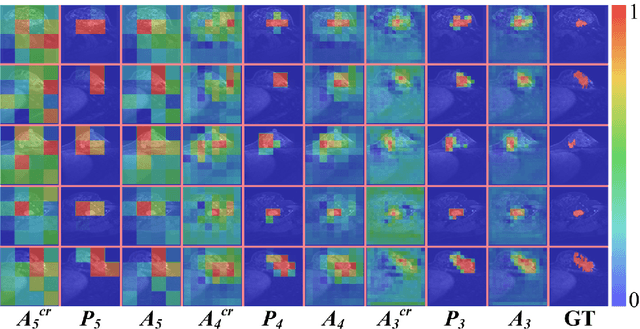
**Background:** Accurate 3D CT scan segmentation of gastric tumors is pivotal for diagnosis and treatment. The challenges lie in the irregular shapes, blurred boundaries of tumors, and the inefficiency of existing methods. **Purpose:** We conducted a study to introduce a model, utilizing human-guided knowledge and unique modules, to address the challenges of 3D tumor segmentation. **Methods:** We developed the PropNet framework, propagating radiologists' knowledge from 2D annotations to the entire 3D space. This model consists of a proposing stage for coarse segmentation and a refining stage for improved segmentation, using two-way branches for enhanced performance and an up-down strategy for efficiency. **Results:** With 98 patient scans for training and 30 for validation, our method achieves a significant agreement with manual annotation (Dice of 0.803) and improves efficiency. The performance is comparable in different scenarios and with various radiologists' annotations (Dice between 0.785 and 0.803). Moreover, the model shows improved prognostic prediction performance (C-index of 0.620 vs. 0.576) on an independent validation set of 42 patients with advanced gastric cancer. **Conclusions:** Our model generates accurate tumor segmentation efficiently and stably, improving prognostic performance and reducing high-throughput image reading workload. This model can accelerate the quantitative analysis of gastric tumors and enhance downstream task performance.
JDSR-GAN: Constructing A Joint and Collaborative Learning Network for Masked Face Super-Resolution
Mar 25, 2021



With the growing importance of preventing the COVID-19 virus, face images obtained in most video surveillance scenarios are low resolution with mask simultaneously. However, most of the previous face super-resolution solutions can not handle both tasks in one model. In this work, we treat the mask occlusion as image noise and construct a joint and collaborative learning network, called JDSR-GAN, for the masked face super-resolution task. Given a low-quality face image with the mask as input, the role of the generator composed of a denoising module and super-resolution module is to acquire a high-quality high-resolution face image. The discriminator utilizes some carefully designed loss functions to ensure the quality of the recovered face images. Moreover, we incorporate the identity information and attention mechanism into our network for feasible correlated feature expression and informative feature learning. By jointly performing denoising and face super-resolution, the two tasks can complement each other and attain promising performance. Extensive qualitative and quantitative results show the superiority of our proposed JDSR-GAN over some comparable methods which perform the previous two tasks separately.
ProductNet: a Collection of High-Quality Datasets for Product Representation Learning
Apr 18, 2019
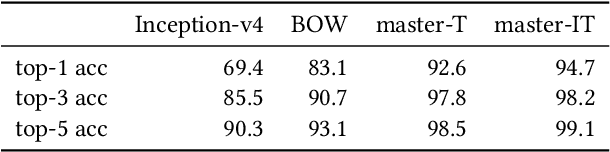
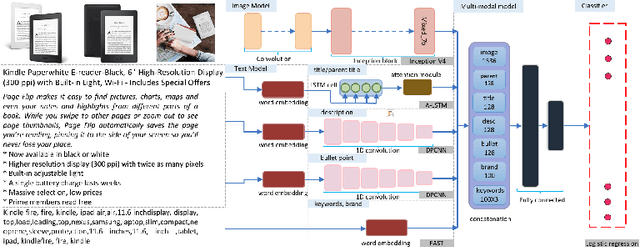

ProductNet is a collection of high-quality product datasets for better product understanding. Motivated by ImageNet, ProductNet aims at supporting product representation learning by curating product datasets of high quality with properly chosen taxonomy. In this paper, the two goals of building high-quality product datasets and learning product representation support each other in an iterative fashion: the product embedding is obtained via a multi-modal deep neural network (master model) designed to leverage product image and catalog information; and in return, the embedding is utilized via active learning (local model) to vastly accelerate the annotation process. For the labeled data, the proposed master model yields high categorization accuracy (94.7% top-1 accuracy for 1240 classes), which can be used as search indices, partition keys, and input features for machine learning models. The product embedding, as well as the fined-tuned master model for a specific business task, can also be used for various transfer learning tasks.
Reference Product Search
Apr 11, 2019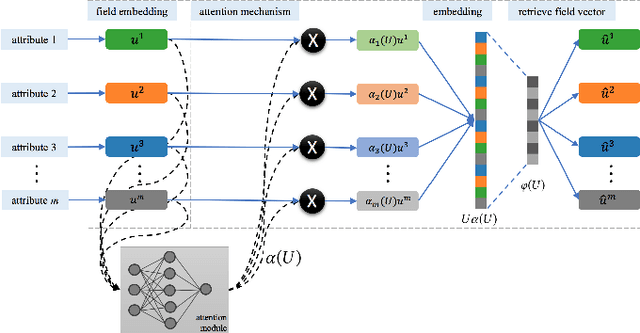

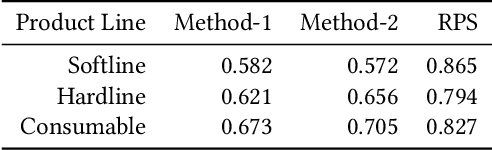
For a product of interest, we propose a search method to surface a set of reference products. The reference products can be used as candidates to support downstream modeling tasks and business applications. The search method consists of product representation learning and fingerprint-type vector searching. The product catalog information is transformed into a high-quality embedding of low dimensions via a novel attention auto-encoder neural network, and the embedding is further coupled with a binary encoding vector for fast retrieval. We conduct extensive experiments to evaluate the proposed method, and compare it with peer services to demonstrate its advantage in terms of search return rate and precision.
Thresholding for Top-k Recommendation with Temporal Dynamics
Nov 09, 2015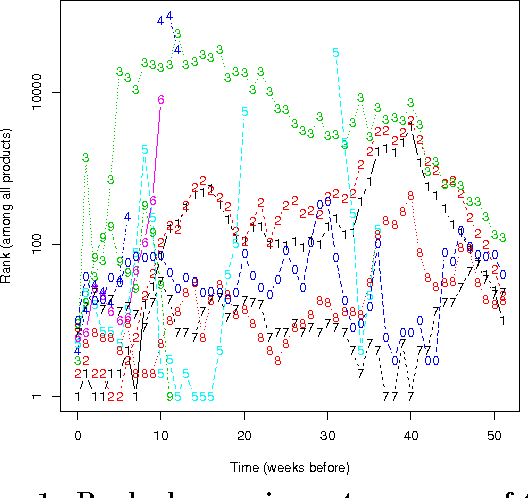


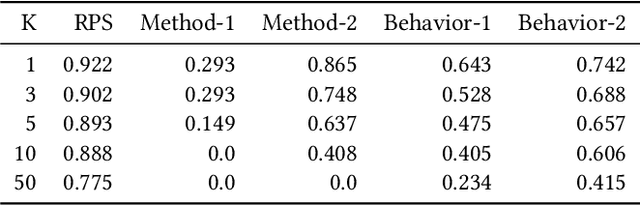
This work focuses on top-k recommendation in domains where underlying data distribution shifts overtime. We propose to learn a time-dependent bias for each item over whatever existing recommendation engine. Such a bias learning process alleviates data sparsity in constructing the engine, and at the same time captures recent trend shift observed in data. We present an alternating optimization framework to resolve the bias learning problem, and develop methods to handle a variety of commonly used recommendation evaluation criteria, as well as large number of items and users in practice. The proposed algorithm is examined, both offline and online, using real world data sets collected from the largest retailer worldwide. Empirical results demonstrate that the bias learning can almost always boost recommendation performance. We encourage other practitioners to adopt it as a standard component in recommender systems where temporal dynamics is a norm.