 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\textit{FedABC}: Attention-Based Client Selection for Federated Learning with Long-Term View
Jul 28, 2025Native AI support is a key objective in the evolution of 6G networks, with Federated Learning (FL) emerging as a promising paradigm. FL allows decentralized clients to collaboratively train an AI model without directly sharing their data, preserving privacy. Clients train local models on private data and share model updates, which a central server aggregates to refine the global model and redistribute it for the next iteration. However, client data heterogeneity slows convergence and reduces model accuracy, and frequent client participation imposes communication and computational burdens. To address these challenges, we propose \textit{FedABC}, an innovative client selection algorithm designed to take a long-term view in managing data heterogeneity and optimizing client participation. Inspired by attention mechanisms, \textit{FedABC} prioritizes informative clients by evaluating both model similarity and each model's unique contributions to the global model. Moreover, considering the evolving demands of the global model, we formulate an optimization problem to guide \textit{FedABC} throughout the training process. Following the ``later-is-better" principle, \textit{FedABC} adaptively adjusts the client selection threshold, encouraging greater participation in later training stages. Extensive simulations on CIFAR-10 demonstrate that \textit{FedABC} significantly outperforms existing approaches in model accuracy and client participation efficiency, achieving comparable performance with 32\% fewer clients than the classical FL algorithm \textit{FedAvg}, and 3.5\% higher accuracy with 2\% fewer clients than the state-of-the-art. This work marks a step toward deploying FL in heterogeneous, resource-constrained environments, thereby supporting native AI capabilities in 6G networks.
Adaptive Few-shot Prompting for Machine Translation with Pre-trained Language Models
Jan 03, 2025Recently, Large language models (LLMs) with in-context learning have demonstrated remarkable potential in handling neural machine translation. However, existing evidence shows that LLMs are prompt-sensitive and it is sub-optimal to apply the fixed prompt to any input for downstream machine translation tasks. To address this issue, we propose an adaptive few-shot prompting (AFSP) framework to automatically select suitable translation demonstrations for various source input sentences to further elicit the translation capability of an LLM for better machine translation. First, we build a translation demonstration retrieval module based on LLM's embedding to retrieve top-k semantic-similar translation demonstrations from aligned parallel translation corpus. Rather than using other embedding models for semantic demonstration retrieval, we build a hybrid demonstration retrieval module based on the embedding layer of the deployed LLM to build better input representation for retrieving more semantic-related translation demonstrations. Then, to ensure better semantic consistency between source inputs and target outputs, we force the deployed LLM itself to generate multiple output candidates in the target language with the help of translation demonstrations and rerank these candidates. Besides, to better evaluate the effectiveness of our AFSP framework on the latest language and extend the research boundary of neural machine translation, we construct a high-quality diplomatic Chinese-English parallel dataset that consists of 5,528 parallel Chinese-English sentences. Finally, extensive experiments on the proposed diplomatic Chinese-English parallel dataset and the United Nations Parallel Corpus (Chinese-English part) show the effectiveness and superiority of our proposed AFSP.
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Apr 29, 2024



MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
Advancing Federated Learning in 6G: A Trusted Architecture with Graph-based Analysis
Sep 27, 2023



Integrating native AI support into the network architecture is an essential objective of 6G. Federated Learning (FL) emerges as a potential paradigm, facilitating decentralized AI model training across a diverse range of devices under the coordination of a central server. However, several challenges hinder its wide application in the 6G context, such as malicious attacks and privacy snooping on local model updates, and centralization pitfalls. This work proposes a trusted architecture for supporting FL, which utilizes Distributed Ledger Technology (DLT) and Graph Neural Network (GNN), including three key features. First, a pre-processing layer employing homomorphic encryption is incorporated to securely aggregate local models, preserving the privacy of individual models. Second, given the distributed nature and graph structure between clients and nodes in the pre-processing layer, GNN is leveraged to identify abnormal local models, enhancing system security. Third, DLT is utilized to decentralize the system by selecting one of the candidates to perform the central server's functions. Additionally, DLT ensures reliable data management by recording data exchanges in an immutable and transparent ledger. The feasibility of the novel architecture is validated through simulations, demonstrating improved performance in anomalous model detection and global model accuracy compared to relevant baselines.
An Approach to Mispronunciation Detection and Diagnosis with Acoustic, Phonetic and Linguistic (APL) Embeddings
Oct 14, 2021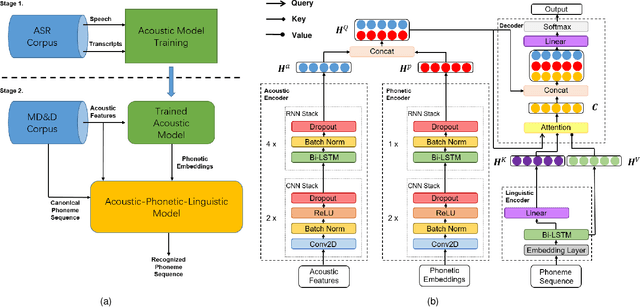
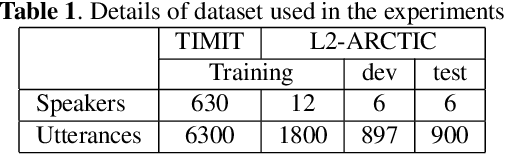
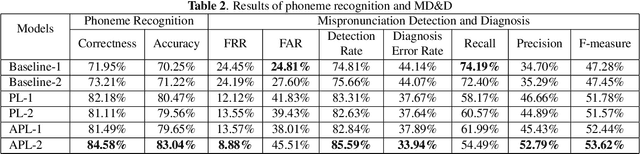
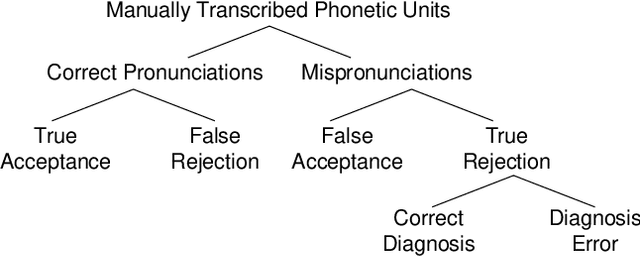
Many mispronunciation detection and diagnosis (MD&D) research approaches try to exploit both the acoustic and linguistic features as input. Yet the improvement of the performance is limited, partially due to the shortage of large amount annotated training data at the phoneme level. Phonetic embeddings, extracted from ASR models trained with huge amount of word level annotations, can serve as a good representation of the content of input speech, in a noise-robust and speaker-independent manner. These embeddings, when used as implicit phonetic supplementary information, can alleviate the data shortage of explicit phoneme annotations. We propose to utilize Acoustic, Phonetic and Linguistic (APL) embedding features jointly for building a more powerful MD\&D system. Experimental results obtained on the L2-ARCTIC database show the proposed approach outperforms the baseline by 9.93%, 10.13% and 6.17% on the detection accuracy, diagnosis error rate and the F-measure, respectively.