 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemEdit: Efficient Diffusion Editing with Riemannian Geometry
Jan 25, 2026Controllable image generation is fundamental to the success of modern generative AI, yet it faces a critical trade-off between semantic fidelity and inference speed. The RemEdit diffusion-based framework addresses this trade-off with two synergistic innovations. First, for editing fidelity, we navigate the latent space as a Riemannian manifold. A mamba-based module efficiently learns the manifold's structure, enabling direct and accurate geodesic path computation for smooth semantic edits. This control is further refined by a dual-SLERP blending technique and a goal-aware prompt enrichment pass from a Vision-Language Model. Second, for additional acceleration, we introduce a novel task-specific attention pruning mechanism. A lightweight pruning head learns to retain tokens essential to the edit, enabling effective optimization without the semantic degradation common in content-agnostic approaches. RemEdit surpasses prior state-of-the-art editing frameworks while maintaining real-time performance under 50% pruning. Consequently, RemEdit establishes a new benchmark for practical and powerful image editing. Source code: https://www.github.com/eashanadhikarla/RemEdit.
LENVIZ: A High-Resolution Low-Exposure Night Vision Benchmark Dataset
Mar 25, 2025

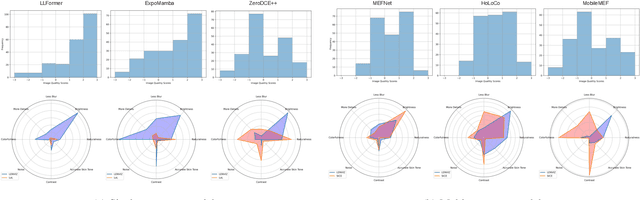
Low-light image enhancement is crucial for a myriad of applications, from night vision and surveillance, to autonomous driving. However, due to the inherent limitations that come in hand with capturing images in low-illumination environments, the task of enhancing such scenes still presents a formidable challenge. To advance research in this field, we introduce our Low Exposure Night Vision (LENVIZ) Dataset, a comprehensive multi-exposure benchmark dataset for low-light image enhancement comprising of over 230K frames showcasing 24K real-world indoor and outdoor, with-and without human, scenes. Captured using 3 different camera sensors, LENVIZ offers a wide range of lighting conditions, noise levels, and scene complexities, making it the largest publicly available up-to 4K resolution benchmark in the field. LENVIZ includes high quality human-generated ground truth, for which each multi-exposure low-light scene has been meticulously curated and edited by expert photographers to ensure optimal image quality. Furthermore, we also conduct a comprehensive analysis of current state-of-the-art low-light image enhancement techniques on our dataset and highlight potential areas of improvement.
ExpoMamba: Exploiting Frequency SSM Blocks for Efficient and Effective Image Enhancement
Aug 19, 2024Low-light image enhancement remains a challenging task in computer vision, with existing state-of-the-art models often limited by hardware constraints and computational inefficiencies, particularly in handling high-resolution images. Recent foundation models, such as transformers and diffusion models, despite their efficacy in various domains, are limited in use on edge devices due to their computational complexity and slow inference times. We introduce ExpoMamba, a novel architecture that integrates components of the frequency state space within a modified U-Net, offering a blend of efficiency and effectiveness. This model is specifically optimized to address mixed exposure challenges, a common issue in low-light image enhancement, while ensuring computational efficiency. Our experiments demonstrate that ExpoMamba enhances low-light images up to 2-3x faster than traditional models with an inference time of 36.6 ms and achieves a PSNR improvement of approximately 15-20% over competing models, making it highly suitable for real-time image processing applications.
Unified-EGformer: Exposure Guided Lightweight Transformer for Mixed-Exposure Image Enhancement
Jul 18, 2024Despite recent strides made by AI in image processing, the issue of mixed exposure, pivotal in many real-world scenarios like surveillance and photography, remains inadequately addressed. Traditional image enhancement techniques and current transformer models are limited with primary focus on either overexposure or underexposure. To bridge this gap, we introduce the Unified-Exposure Guided Transformer (Unified-EGformer). Our proposed solution is built upon advanced transformer architectures, equipped with local pixel-level refinement and global refinement blocks for color correction and image-wide adjustments. We employ a guided attention mechanism to precisely identify exposure-compromised regions, ensuring its adaptability across various real-world conditions. U-EGformer, with a lightweight design featuring a memory footprint (peak memory) of only $\sim$1134 MB (0.1 Million parameters) and an inference time of 95 ms (9.61x faster than the average), is a viable choice for real-time applications such as surveillance and autonomous navigation. Additionally, our model is highly generalizable, requiring minimal fine-tuning to handle multiple tasks and datasets with a single architecture.
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Apr 29, 2024



MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
Robust Computer Vision in an Ever-Changing World: A Survey of Techniques for Tackling Distribution Shifts
Dec 03, 2023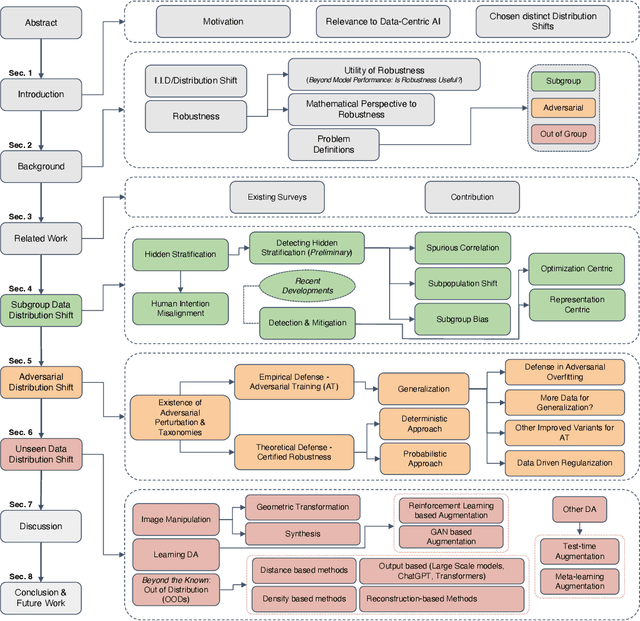

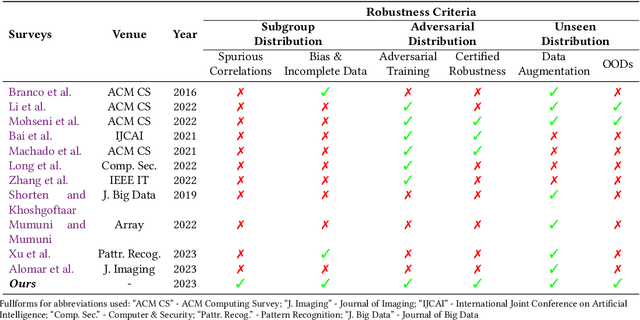
AI applications are becoming increasingly visible to the general public. There is a notable gap between the theoretical assumptions researchers make about computer vision models and the reality those models face when deployed in the real world. One of the critical reasons for this gap is a challenging problem known as distribution shift. Distribution shifts tend to vary with complexity of the data, dataset size, and application type. In our paper, we discuss the identification of such a prominent gap, exploring the concept of distribution shift and its critical significance. We provide an in-depth overview of various types of distribution shifts, elucidate their distinctions, and explore techniques within the realm of the data-centric domain employed to address them. Distribution shifts can occur during every phase of the machine learning pipeline, from the data collection stage to the stage of training a machine learning model to the stage of final model deployment. As a result, it raises concerns about the overall robustness of the machine learning techniques for computer vision applications that are deployed publicly for consumers. Different deep learning models each tailored for specific type of data and tasks, architectural pipelines; highlighting how variations in data preprocessing and feature extraction can impact robustness., data augmentation strategies (e.g. geometric, synthetic and learning-based); demonstrating their role in enhancing model generalization, and training mechanisms (e.g. transfer learning, zero-shot) fall under the umbrella of data-centric methods. Each of these components form an integral part of the neural-network we analyze contributing uniquely to strengthening model robustness against distribution shifts. We compare and contrast numerous AI models that are built for mitigating shifts in hidden stratification and spurious correlations, ...
BiomedGPT: A Unified and Generalist Biomedical Generative Pre-trained Transformer for Vision, Language, and Multimodal Tasks
May 26, 2023In this paper, we introduce a unified and generalist Biomedical Generative Pre-trained Transformer (BiomedGPT) model, which leverages self-supervision on large and diverse datasets to accept multi-modal inputs and perform a range of downstream tasks. Our experiments demonstrate that BiomedGPT delivers expansive and inclusive representations of biomedical data, outperforming the majority of preceding state-of-the-art models across five distinct tasks with 20 public datasets spanning over 15 unique biomedical modalities. Through the ablation study, we also showcase the efficacy of our multi-modal and multi-task pretraining approach in transferring knowledge to previously unseen data. Overall, our work presents a significant step forward in developing unified and generalist models for biomedicine, with far-reaching implications for improving healthcare outcomes.
Memory Defense: More Robust Classification via a Memory-Masking Autoencoder
Feb 05, 2022



Many deep neural networks are susceptible to minute perturbations of images that have been carefully crafted to cause misclassification. Ideally, a robust classifier would be immune to small variations in input images, and a number of defensive approaches have been created as a result. One method would be to discern a latent representation which could ignore small changes to the input. However, typical autoencoders easily mingle inter-class latent representations when there are strong similarities between classes, making it harder for a decoder to accurately project the image back to the original high-dimensional space. We propose a novel framework, Memory Defense, an augmented classifier with a memory-masking autoencoder to counter this challenge. By masking other classes, the autoencoder learns class-specific independent latent representations. We test the model's robustness against four widely used attacks. Experiments on the Fashion-MNIST & CIFAR-10 datasets demonstrate the superiority of our model. We make available our source code at GitHub repository: https://github.com/eashanadhikarla/MemDefense