 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Aging Multiverse: Generating Condition-Aware Facial Aging Tree via Training-Free Diffusion
Jun 26, 2025We introduce the Aging Multiverse, a framework for generating multiple plausible facial aging trajectories from a single image, each conditioned on external factors such as environment, health, and lifestyle. Unlike prior methods that model aging as a single deterministic path, our approach creates an aging tree that visualizes diverse futures. To enable this, we propose a training-free diffusion-based method that balances identity preservation, age accuracy, and condition control. Our key contributions include attention mixing to modulate editing strength and a Simulated Aging Regularization strategy to stabilize edits. Extensive experiments and user studies demonstrate state-of-the-art performance across identity preservation, aging realism, and conditional alignment, outperforming existing editing and age-progression models, which often fail to account for one or more of the editing criteria. By transforming aging into a multi-dimensional, controllable, and interpretable process, our approach opens up new creative and practical avenues in digital storytelling, health education, and personalized visualization.
An Iterative Framework for Generative Backmapping of Coarse Grained Proteins
May 23, 2025



The techniques of data-driven backmapping from coarse-grained (CG) to fine-grained (FG) representation often struggle with accuracy, unstable training, and physical realism, especially when applied to complex systems such as proteins. In this work, we introduce a novel iterative framework by using conditional Variational Autoencoders and graph-based neural networks, specifically designed to tackle the challenges associated with such large-scale biomolecules. Our method enables stepwise refinement from CG beads to full atomistic details. We outline the theory of iterative generative backmapping and demonstrate via numerical experiments the advantages of multistep schemes by applying them to proteins of vastly different structures with very coarse representations. This multistep approach not only improves the accuracy of reconstructions but also makes the training process more computationally efficient for proteins with ultra-CG representations.
ExpoMamba: Exploiting Frequency SSM Blocks for Efficient and Effective Image Enhancement
Aug 19, 2024Low-light image enhancement remains a challenging task in computer vision, with existing state-of-the-art models often limited by hardware constraints and computational inefficiencies, particularly in handling high-resolution images. Recent foundation models, such as transformers and diffusion models, despite their efficacy in various domains, are limited in use on edge devices due to their computational complexity and slow inference times. We introduce ExpoMamba, a novel architecture that integrates components of the frequency state space within a modified U-Net, offering a blend of efficiency and effectiveness. This model is specifically optimized to address mixed exposure challenges, a common issue in low-light image enhancement, while ensuring computational efficiency. Our experiments demonstrate that ExpoMamba enhances low-light images up to 2-3x faster than traditional models with an inference time of 36.6 ms and achieves a PSNR improvement of approximately 15-20% over competing models, making it highly suitable for real-time image processing applications.
Unified-EGformer: Exposure Guided Lightweight Transformer for Mixed-Exposure Image Enhancement
Jul 18, 2024Despite recent strides made by AI in image processing, the issue of mixed exposure, pivotal in many real-world scenarios like surveillance and photography, remains inadequately addressed. Traditional image enhancement techniques and current transformer models are limited with primary focus on either overexposure or underexposure. To bridge this gap, we introduce the Unified-Exposure Guided Transformer (Unified-EGformer). Our proposed solution is built upon advanced transformer architectures, equipped with local pixel-level refinement and global refinement blocks for color correction and image-wide adjustments. We employ a guided attention mechanism to precisely identify exposure-compromised regions, ensuring its adaptability across various real-world conditions. U-EGformer, with a lightweight design featuring a memory footprint (peak memory) of only $\sim$1134 MB (0.1 Million parameters) and an inference time of 95 ms (9.61x faster than the average), is a viable choice for real-time applications such as surveillance and autonomous navigation. Additionally, our model is highly generalizable, requiring minimal fine-tuning to handle multiple tasks and datasets with a single architecture.
Robust Computer Vision in an Ever-Changing World: A Survey of Techniques for Tackling Distribution Shifts
Dec 03, 2023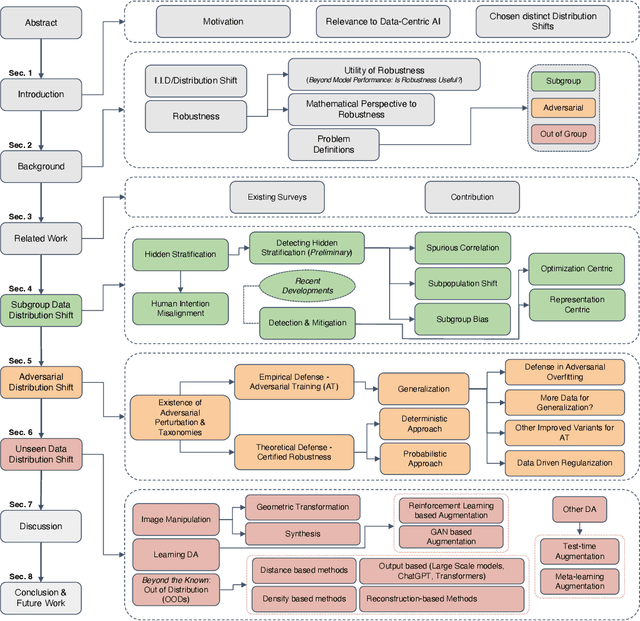

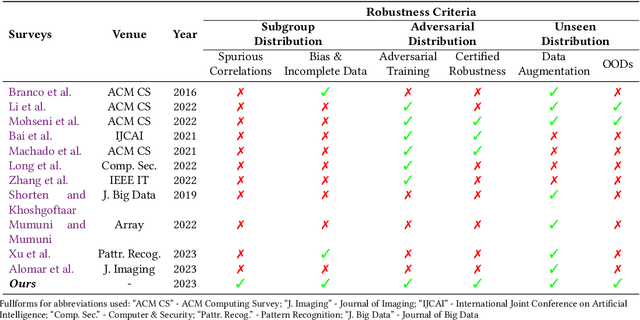
AI applications are becoming increasingly visible to the general public. There is a notable gap between the theoretical assumptions researchers make about computer vision models and the reality those models face when deployed in the real world. One of the critical reasons for this gap is a challenging problem known as distribution shift. Distribution shifts tend to vary with complexity of the data, dataset size, and application type. In our paper, we discuss the identification of such a prominent gap, exploring the concept of distribution shift and its critical significance. We provide an in-depth overview of various types of distribution shifts, elucidate their distinctions, and explore techniques within the realm of the data-centric domain employed to address them. Distribution shifts can occur during every phase of the machine learning pipeline, from the data collection stage to the stage of training a machine learning model to the stage of final model deployment. As a result, it raises concerns about the overall robustness of the machine learning techniques for computer vision applications that are deployed publicly for consumers. Different deep learning models each tailored for specific type of data and tasks, architectural pipelines; highlighting how variations in data preprocessing and feature extraction can impact robustness., data augmentation strategies (e.g. geometric, synthetic and learning-based); demonstrating their role in enhancing model generalization, and training mechanisms (e.g. transfer learning, zero-shot) fall under the umbrella of data-centric methods. Each of these components form an integral part of the neural-network we analyze contributing uniquely to strengthening model robustness against distribution shifts. We compare and contrast numerous AI models that are built for mitigating shifts in hidden stratification and spurious correlations, ...
A Kernel-Based Approach for Modelling Gaussian Processes with Functional Information
Jan 26, 2022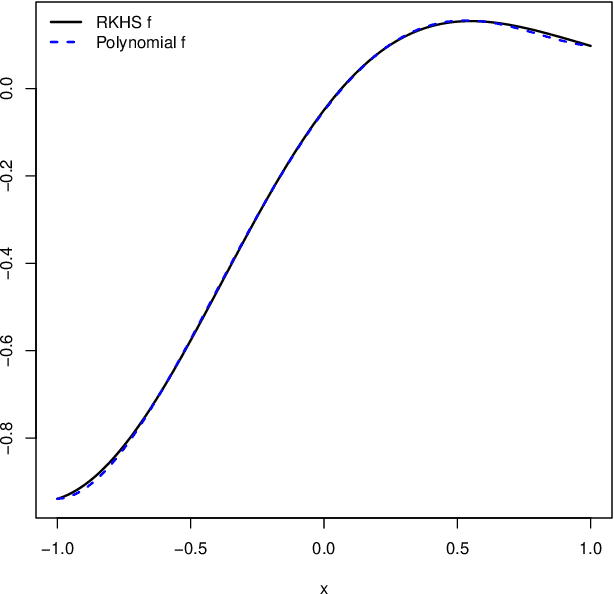



Gaussian processes are among the most useful tools in modeling continuous processes in machine learning and statistics. If the value of a process is known at a finite collection of points, one may use Gaussian processes to construct a surface which interpolates these values to be used for prediction and uncertainty quantification in other locations. However, it is not always the case that the available information is in the form of a finite collection of points. For example, boundary value problems contain information on the boundary of a domain, which is an uncountable collection of points that cannot be incorporated into typical Gaussian process techniques. In this paper we construct a Gaussian process model which utilizes reproducing kernel Hilbert spaces to unify the typical finite case with the case of having uncountable information by exploiting the equivalence of conditional expectation and orthogonal projections. We discuss this construction in statistical models, including numerical considerations and a proof of concept.