 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLENVIZ: A High-Resolution Low-Exposure Night Vision Benchmark Dataset
Mar 25, 2025

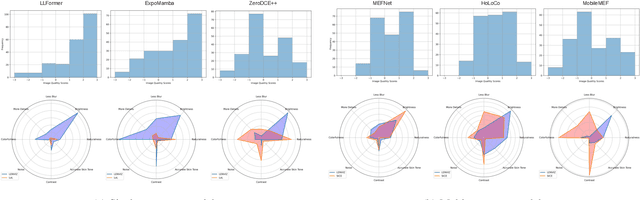
Low-light image enhancement is crucial for a myriad of applications, from night vision and surveillance, to autonomous driving. However, due to the inherent limitations that come in hand with capturing images in low-illumination environments, the task of enhancing such scenes still presents a formidable challenge. To advance research in this field, we introduce our Low Exposure Night Vision (LENVIZ) Dataset, a comprehensive multi-exposure benchmark dataset for low-light image enhancement comprising of over 230K frames showcasing 24K real-world indoor and outdoor, with-and without human, scenes. Captured using 3 different camera sensors, LENVIZ offers a wide range of lighting conditions, noise levels, and scene complexities, making it the largest publicly available up-to 4K resolution benchmark in the field. LENVIZ includes high quality human-generated ground truth, for which each multi-exposure low-light scene has been meticulously curated and edited by expert photographers to ensure optimal image quality. Furthermore, we also conduct a comprehensive analysis of current state-of-the-art low-light image enhancement techniques on our dataset and highlight potential areas of improvement.
Unified-EGformer: Exposure Guided Lightweight Transformer for Mixed-Exposure Image Enhancement
Jul 18, 2024Despite recent strides made by AI in image processing, the issue of mixed exposure, pivotal in many real-world scenarios like surveillance and photography, remains inadequately addressed. Traditional image enhancement techniques and current transformer models are limited with primary focus on either overexposure or underexposure. To bridge this gap, we introduce the Unified-Exposure Guided Transformer (Unified-EGformer). Our proposed solution is built upon advanced transformer architectures, equipped with local pixel-level refinement and global refinement blocks for color correction and image-wide adjustments. We employ a guided attention mechanism to precisely identify exposure-compromised regions, ensuring its adaptability across various real-world conditions. U-EGformer, with a lightweight design featuring a memory footprint (peak memory) of only $\sim$1134 MB (0.1 Million parameters) and an inference time of 95 ms (9.61x faster than the average), is a viable choice for real-time applications such as surveillance and autonomous navigation. Additionally, our model is highly generalizable, requiring minimal fine-tuning to handle multiple tasks and datasets with a single architecture.