 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLENVIZ: A High-Resolution Low-Exposure Night Vision Benchmark Dataset
Mar 25, 2025

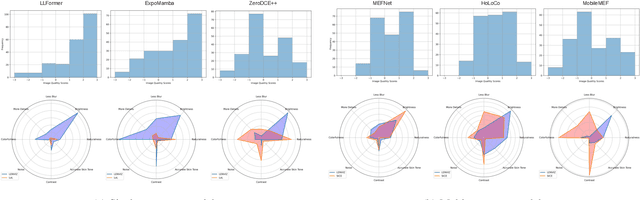
Low-light image enhancement is crucial for a myriad of applications, from night vision and surveillance, to autonomous driving. However, due to the inherent limitations that come in hand with capturing images in low-illumination environments, the task of enhancing such scenes still presents a formidable challenge. To advance research in this field, we introduce our Low Exposure Night Vision (LENVIZ) Dataset, a comprehensive multi-exposure benchmark dataset for low-light image enhancement comprising of over 230K frames showcasing 24K real-world indoor and outdoor, with-and without human, scenes. Captured using 3 different camera sensors, LENVIZ offers a wide range of lighting conditions, noise levels, and scene complexities, making it the largest publicly available up-to 4K resolution benchmark in the field. LENVIZ includes high quality human-generated ground truth, for which each multi-exposure low-light scene has been meticulously curated and edited by expert photographers to ensure optimal image quality. Furthermore, we also conduct a comprehensive analysis of current state-of-the-art low-light image enhancement techniques on our dataset and highlight potential areas of improvement.
Benchmark Evaluation of Image Fusion algorithms for Smartphone Camera Capture
Jun 29, 2024


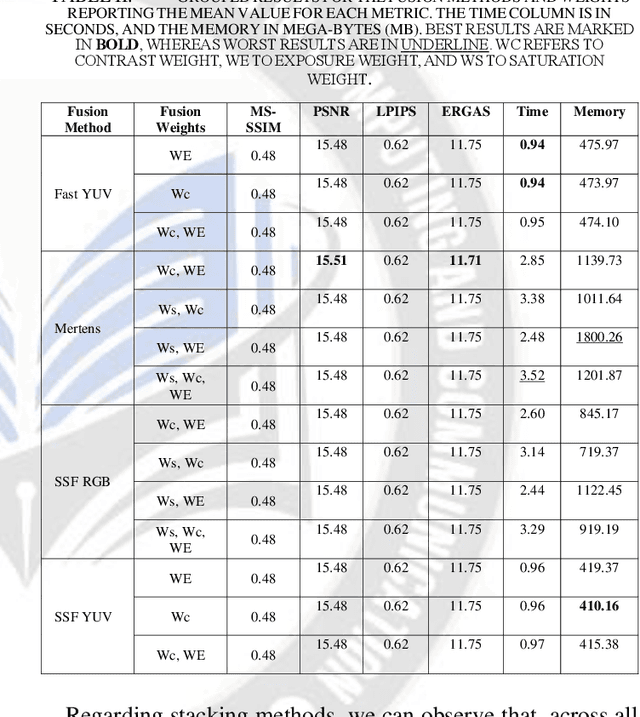
This paper investigates the trade-off between computational resource utilization and image quality in the context of image fusion techniques for smartphone camera capture. The study explores various combinations of fusion methods, fusion weights, number of frames, and stacking (a.k.a. merging) techniques using a proprietary dataset of images captured with Motorola smartphones. The objective was to identify optimal configurations that balance computational efficiency with image quality. Our results indicate that multi-scale methods and their single-scale fusion counterparts return similar image quality measures and runtime, but single-scale ones have lower memory usage. Furthermore, we identified that fusion methods operating in the YUV color space yield better performance in terms of image quality, resource utilization, and runtime. The study also shows that fusion weights have an overall small impact on image quality, runtime, and memory. Moreover, our results reveal that increasing the number of highly exposed input frames does not necessarily improve image quality and comes with a corresponding increase in computational resources usage and runtime; and that stacking methods, although reducing memory usage, may compromise image quality. Finally, our work underscores the importance of thoughtful configuration selection for image fusion techniques in constrained environments and offers insights for future image fusion method development, particularly in the realm of smartphone applications.
* Presented at the ICMLAI 2024, in Mendonza, Argentina
Cell Tracking-by-detection using Elliptical Bounding Boxes
Oct 11, 2023



Cell detection and tracking are paramount for bio-analysis. Recent approaches rely on the tracking-by-model evolution paradigm, which usually consists of training end-to-end deep learning models to detect and track the cells on the frames with promising results. However, such methods require extensive amounts of annotated data, which is time-consuming to obtain and often requires specialized annotators. This work proposes a new approach based on the classical tracking-by-detection paradigm that alleviates the requirement of annotated data. More precisely, it approximates the cell shapes as oriented ellipses and then uses generic-purpose oriented object detectors to identify the cells in each frame. We then rely on a global data association algorithm that explores temporal cell similarity using probability distance metrics, considering that the ellipses relate to two-dimensional Gaussian distributions. Our results show that our method can achieve detection and tracking results competitively with state-of-the-art techniques that require considerably more extensive data annotation. Our code is available at: https://github.com/LucasKirsten/Deep-Cell-Tracking-EBB.
Evaluating Deep Neural Networks for Image Document Enhancement
Jun 11, 2021



This work evaluates six state-of-the-art deep neural network (DNN) architectures applied to the problem of enhancing camera-captured document images. The results from each network were evaluated both qualitatively and quantitatively using Image Quality Assessment (IQA) metrics, and also compared with an existing approach based on traditional computer vision techniques. The best performing architectures generally produced good enhancement compared to the existing algorithm, showing that it is possible to use DNNs for document image enhancement. Furthermore, the best performing architectures could work as a baseline for future investigations on document enhancement using deep learning techniques. The main contributions of this paper are: a baseline of deep learning techniques that can be further improved to provide better results, and a evaluation methodology using IQA metrics for quantitatively comparing the produced images from the neural networks to a ground truth.