 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver++: Generative Video Compositing for Layer Interaction Effects
Dec 22, 2025In professional video compositing workflows, artists must manually create environmental interactions-such as shadows, reflections, dust, and splashes-between foreground subjects and background layers. Existing video generative models struggle to preserve the input video while adding such effects, and current video inpainting methods either require costly per-frame masks or yield implausible results. We introduce augmented compositing, a new task that synthesizes realistic, semi-transparent environmental effects conditioned on text prompts and input video layers, while preserving the original scene. To address this task, we present Over++, a video effect generation framework that makes no assumptions about camera pose, scene stationarity, or depth supervision. We construct a paired effect dataset tailored for this task and introduce an unpaired augmentation strategy that preserves text-driven editability. Our method also supports optional mask control and keyframe guidance without requiring dense annotations. Despite training on limited data, Over++ produces diverse and realistic environmental effects and outperforms existing baselines in both effect generation and scene preservation.
GAINS: Gaussian-based Inverse Rendering from Sparse Multi-View Captures
Dec 10, 2025Recent advances in Gaussian Splatting-based inverse rendering extend Gaussian primitives with shading parameters and physically grounded light transport, enabling high-quality material recovery from dense multi-view captures. However, these methods degrade sharply under sparse-view settings, where limited observations lead to severe ambiguity between geometry, reflectance, and lighting. We introduce GAINS (Gaussian-based Inverse rendering from Sparse multi-view captures), a two-stage inverse rendering framework that leverages learning-based priors to stabilize geometry and material estimation. GAINS first refines geometry using monocular depth/normal and diffusion priors, then employs segmentation, intrinsic image decomposition (IID), and diffusion priors to regularize material recovery. Extensive experiments on synthetic and real-world datasets show that GAINS significantly improves material parameter accuracy, relighting quality, and novel-view synthesis compared to state-of-the-art Gaussian-based inverse rendering methods, especially under sparse-view settings. Project page: https://patrickbail.github.io/gains/
The Aging Multiverse: Generating Condition-Aware Facial Aging Tree via Training-Free Diffusion
Jun 26, 2025We introduce the Aging Multiverse, a framework for generating multiple plausible facial aging trajectories from a single image, each conditioned on external factors such as environment, health, and lifestyle. Unlike prior methods that model aging as a single deterministic path, our approach creates an aging tree that visualizes diverse futures. To enable this, we propose a training-free diffusion-based method that balances identity preservation, age accuracy, and condition control. Our key contributions include attention mixing to modulate editing strength and a Simulated Aging Regularization strategy to stabilize edits. Extensive experiments and user studies demonstrate state-of-the-art performance across identity preservation, aging realism, and conditional alignment, outperforming existing editing and age-progression models, which often fail to account for one or more of the editing criteria. By transforming aging into a multi-dimensional, controllable, and interpretable process, our approach opens up new creative and practical avenues in digital storytelling, health education, and personalized visualization.
ProJo4D: Progressive Joint Optimization for Sparse-View Inverse Physics Estimation
Jun 05, 2025Neural rendering has made significant strides in 3D reconstruction and novel view synthesis. With the integration with physics, it opens up new applications. The inverse problem of estimating physics from visual data, however, still remains challenging, limiting its effectiveness for applications like physically accurate digital twin creation in robotics and XR. Existing methods that incorporate physics into neural rendering frameworks typically require dense multi-view videos as input, making them impractical for scalable, real-world use. When presented with sparse multi-view videos, the sequential optimization strategy used by existing approaches introduces significant error accumulation, e.g., poor initial 3D reconstruction leads to bad material parameter estimation in subsequent stages. Instead of sequential optimization, directly optimizing all parameters at the same time also fails due to the highly non-convex and often non-differentiable nature of the problem. We propose ProJo4D, a progressive joint optimization framework that gradually increases the set of jointly optimized parameters guided by their sensitivity, leading to fully joint optimization over geometry, appearance, physical state, and material property. Evaluations on PAC-NeRF and Spring-Gaus datasets show that ProJo4D outperforms prior work in 4D future state prediction, novel view rendering of future state, and material parameter estimation, demonstrating its effectiveness in physically grounded 4D scene understanding. For demos, please visit the project webpage: https://daniel03c1.github.io/ProJo4D/
TalkingHeadBench: A Multi-Modal Benchmark & Analysis of Talking-Head DeepFake Detection
May 30, 2025The rapid advancement of talking-head deepfake generation fueled by advanced generative models has elevated the realism of synthetic videos to a level that poses substantial risks in domains such as media, politics, and finance. However, current benchmarks for deepfake talking-head detection fail to reflect this progress, relying on outdated generators and offering limited insight into model robustness and generalization. We introduce TalkingHeadBench, a comprehensive multi-model multi-generator benchmark and curated dataset designed to evaluate the performance of state-of-the-art detectors on the most advanced generators. Our dataset includes deepfakes synthesized by leading academic and commercial models and features carefully constructed protocols to assess generalization under distribution shifts in identity and generator characteristics. We benchmark a diverse set of existing detection methods, including CNNs, vision transformers, and temporal models, and analyze their robustness and generalization capabilities. In addition, we provide error analysis using Grad-CAM visualizations to expose common failure modes and detector biases. TalkingHeadBench is hosted on https://huggingface.co/datasets/luchaoqi/TalkingHeadBench with open access to all data splits and protocols. Our benchmark aims to accelerate research towards more robust and generalizable detection models in the face of rapidly evolving generative techniques.
VIN-NBV: A View Introspection Network for Next-Best-View Selection for Resource-Efficient 3D Reconstruction
May 09, 2025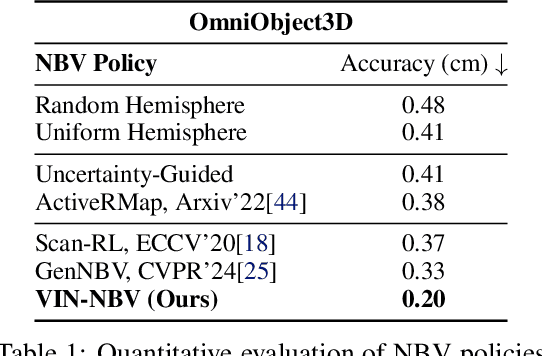
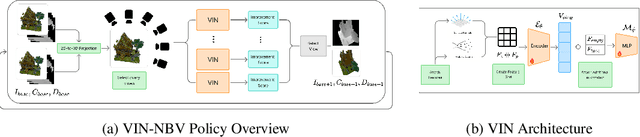
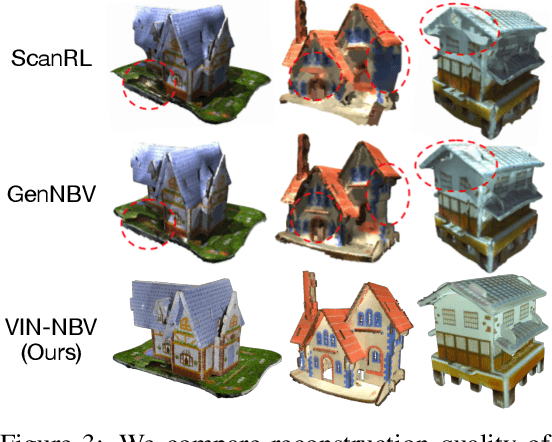
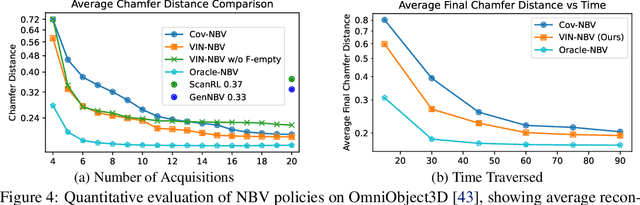
Next Best View (NBV) algorithms aim to acquire an optimal set of images using minimal resources, time, or number of captures to enable efficient 3D reconstruction of a scene. Existing approaches often rely on prior scene knowledge or additional image captures and often develop policies that maximize coverage. Yet, for many real scenes with complex geometry and self-occlusions, coverage maximization does not lead to better reconstruction quality directly. In this paper, we propose the View Introspection Network (VIN), which is trained to predict the reconstruction quality improvement of views directly, and the VIN-NBV policy. A greedy sequential sampling-based policy, where at each acquisition step, we sample multiple query views and choose the one with the highest VIN predicted improvement score. We design the VIN to perform 3D-aware featurization of the reconstruction built from prior acquisitions, and for each query view create a feature that can be decoded into an improvement score. We then train the VIN using imitation learning to predict the reconstruction improvement score. We show that VIN-NBV improves reconstruction quality by ~30% over a coverage maximization baseline when operating with constraints on the number of acquisitions or the time in motion.
PPS-Ctrl: Controllable Sim-to-Real Translation for Colonoscopy Depth Estimation
Apr 23, 2025Accurate depth estimation enhances endoscopy navigation and diagnostics, but obtaining ground-truth depth in clinical settings is challenging. Synthetic datasets are often used for training, yet the domain gap limits generalization to real data. We propose a novel image-to-image translation framework that preserves structure while generating realistic textures from clinical data. Our key innovation integrates Stable Diffusion with ControlNet, conditioned on a latent representation extracted from a Per-Pixel Shading (PPS) map. PPS captures surface lighting effects, providing a stronger structural constraint than depth maps. Experiments show our approach produces more realistic translations and improves depth estimation over GAN-based MI-CycleGAN. Our code is publicly accessible at https://github.com/anaxqx/PPS-Ctrl.
NFL-BA: Improving Endoscopic SLAM with Near-Field Light Bundle Adjustment
Dec 17, 2024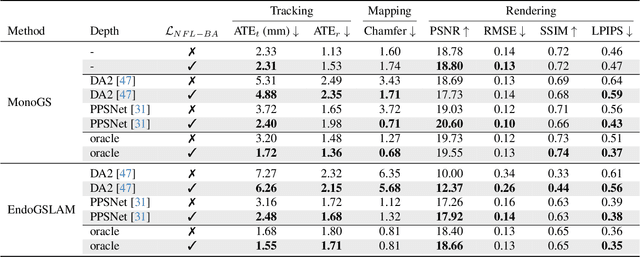
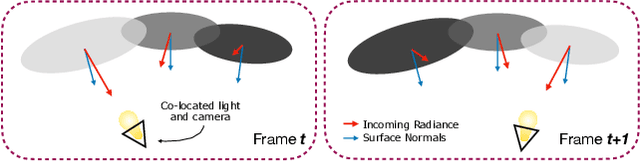
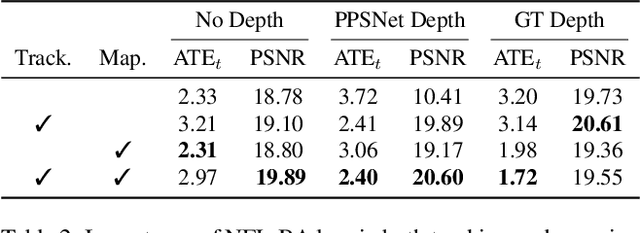
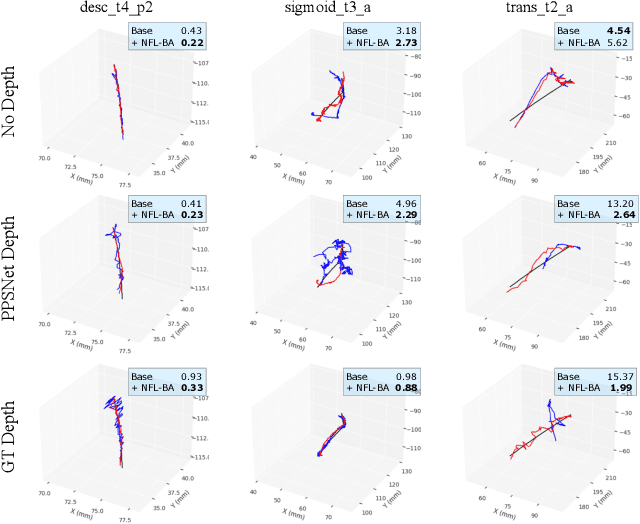
Simultaneous Localization And Mapping (SLAM) from a monocular endoscopy video can enable autonomous navigation, guidance to unsurveyed regions, and 3D visualizations, which can significantly improve endoscopy experience for surgeons and patient outcomes. Existing dense SLAM algorithms often assume distant and static lighting and textured surfaces, and alternate between optimizing scene geometry and camera parameters by minimizing a photometric rendering loss, often called Photometric Bundle Adjustment. However, endoscopic environments exhibit dynamic near-field lighting due to the co-located light and camera moving extremely close to the surface, textureless surfaces, and strong specular reflections due to mucus layers. When not considered, these near-field lighting effects can cause significant performance reductions for existing SLAM algorithms from indoor/outdoor scenes when applied to endoscopy videos. To mitigate this problem, we introduce a new Near-Field Lighting Bundle Adjustment Loss $(L_{NFL-BA})$ that can also be alternatingly optimized, along with the Photometric Bundle Adjustment loss, such that the captured images' intensity variations match the relative distance and orientation between the surface and the co-located light and camera. We derive a general NFL-BA loss function for 3D Gaussian surface representations and demonstrate that adding $L_{NFL-BA}$ can significantly improve the tracking and mapping performance of two state-of-the-art 3DGS-SLAM systems, MonoGS (35% improvement in tracking, 48% improvement in mapping with predicted depth maps) and EndoGSLAM (22% improvement in tracking, marginal improvement in mapping with predicted depths), on the C3VD endoscopy dataset for colons. The project page is available at https://asdunnbe.github.io/NFL-BA/
Continual Learning of Personalized Generative Face Models with Experience Replay
Dec 03, 2024



We introduce a novel continual learning problem: how to sequentially update the weights of a personalized 2D and 3D generative face model as new batches of photos in different appearances, styles, poses, and lighting are captured regularly. We observe that naive sequential fine-tuning of the model leads to catastrophic forgetting of past representations of the individual's face. We then demonstrate that a simple random sampling-based experience replay method is effective at mitigating catastrophic forgetting when a relatively large number of images can be stored and replayed. However, for long-term deployment of these models with relatively smaller storage, this simple random sampling-based replay technique also forgets past representations. Thus, we introduce a novel experience replay algorithm that combines random sampling with StyleGAN's latent space to represent the buffer as an optimal convex hull. We observe that our proposed convex hull-based experience replay is more effective in preventing forgetting than a random sampling baseline and the lower bound.
ScribbleLight: Single Image Indoor Relighting with Scribbles
Nov 26, 2024Image-based relighting of indoor rooms creates an immersive virtual understanding of the space, which is useful for interior design, virtual staging, and real estate. Relighting indoor rooms from a single image is especially challenging due to complex illumination interactions between multiple lights and cluttered objects featuring a large variety in geometrical and material complexity. Recently, generative models have been successfully applied to image-based relighting conditioned on a target image or a latent code, albeit without detailed local lighting control. In this paper, we introduce ScribbleLight, a generative model that supports local fine-grained control of lighting effects through scribbles that describe changes in lighting. Our key technical novelty is an Albedo-conditioned Stable Image Diffusion model that preserves the intrinsic color and texture of the original image after relighting and an encoder-decoder-based ControlNet architecture that enables geometry-preserving lighting effects with normal map and scribble annotations. We demonstrate ScribbleLight's ability to create different lighting effects (e.g., turning lights on/off, adding highlights, cast shadows, or indirect lighting from unseen lights) from sparse scribble annotations.