 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-preserving Image Translation for Depth Estimation in Colonoscopy Video
Aug 19, 2024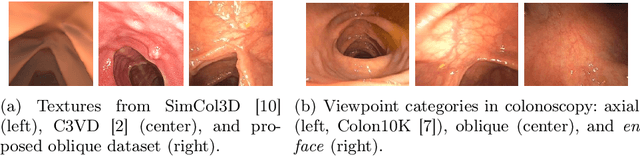


Monocular depth estimation in colonoscopy video aims to overcome the unusual lighting properties of the colonoscopic environment. One of the major challenges in this area is the domain gap between annotated but unrealistic synthetic data and unannotated but realistic clinical data. Previous attempts to bridge this domain gap directly target the depth estimation task itself. We propose a general pipeline of structure-preserving synthetic-to-real (sim2real) image translation (producing a modified version of the input image) to retain depth geometry through the translation process. This allows us to generate large quantities of realistic-looking synthetic images for supervised depth estimation with improved generalization to the clinical domain. We also propose a dataset of hand-picked sequences from clinical colonoscopies to improve the image translation process. We demonstrate the simultaneous realism of the translated images and preservation of depth maps via the performance of downstream depth estimation on various datasets.