 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAINS: Gaussian-based Inverse Rendering from Sparse Multi-View Captures
Dec 10, 2025Recent advances in Gaussian Splatting-based inverse rendering extend Gaussian primitives with shading parameters and physically grounded light transport, enabling high-quality material recovery from dense multi-view captures. However, these methods degrade sharply under sparse-view settings, where limited observations lead to severe ambiguity between geometry, reflectance, and lighting. We introduce GAINS (Gaussian-based Inverse rendering from Sparse multi-view captures), a two-stage inverse rendering framework that leverages learning-based priors to stabilize geometry and material estimation. GAINS first refines geometry using monocular depth/normal and diffusion priors, then employs segmentation, intrinsic image decomposition (IID), and diffusion priors to regularize material recovery. Extensive experiments on synthetic and real-world datasets show that GAINS significantly improves material parameter accuracy, relighting quality, and novel-view synthesis compared to state-of-the-art Gaussian-based inverse rendering methods, especially under sparse-view settings. Project page: https://patrickbail.github.io/gains/
RenderFormer: Transformer-based Neural Rendering of Triangle Meshes with Global Illumination
May 28, 2025We present RenderFormer, a neural rendering pipeline that directly renders an image from a triangle-based representation of a scene with full global illumination effects and that does not require per-scene training or fine-tuning. Instead of taking a physics-centric approach to rendering, we formulate rendering as a sequence-to-sequence transformation where a sequence of tokens representing triangles with reflectance properties is converted to a sequence of output tokens representing small patches of pixels. RenderFormer follows a two stage pipeline: a view-independent stage that models triangle-to-triangle light transport, and a view-dependent stage that transforms a token representing a bundle of rays to the corresponding pixel values guided by the triangle-sequence from the view-independent stage. Both stages are based on the transformer architecture and are learned with minimal prior constraints. We demonstrate and evaluate RenderFormer on scenes with varying complexity in shape and light transport.
* Accepted to SIGGRAPH 2025. Project page: https://microsoft.github.io/renderformer
ScribbleLight: Single Image Indoor Relighting with Scribbles
Nov 26, 2024Image-based relighting of indoor rooms creates an immersive virtual understanding of the space, which is useful for interior design, virtual staging, and real estate. Relighting indoor rooms from a single image is especially challenging due to complex illumination interactions between multiple lights and cluttered objects featuring a large variety in geometrical and material complexity. Recently, generative models have been successfully applied to image-based relighting conditioned on a target image or a latent code, albeit without detailed local lighting control. In this paper, we introduce ScribbleLight, a generative model that supports local fine-grained control of lighting effects through scribbles that describe changes in lighting. Our key technical novelty is an Albedo-conditioned Stable Image Diffusion model that preserves the intrinsic color and texture of the original image after relighting and an encoder-decoder-based ControlNet architecture that enables geometry-preserving lighting effects with normal map and scribble annotations. We demonstrate ScribbleLight's ability to create different lighting effects (e.g., turning lights on/off, adding highlights, cast shadows, or indirect lighting from unseen lights) from sparse scribble annotations.
Content-aware Tile Generation using Exterior Boundary Inpainting
Sep 21, 2024


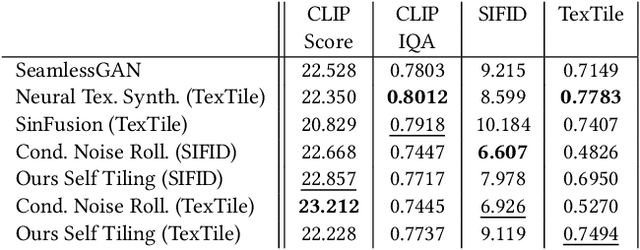
We present a novel and flexible learning-based method for generating tileable image sets. Our method goes beyond simple self-tiling, supporting sets of mutually tileable images that exhibit a high degree of diversity. To promote diversity we decouple structure from content by foregoing explicit copying of patches from an exemplar image. Instead we leverage the prior knowledge of natural images and textures embedded in large-scale pretrained diffusion models to guide tile generation constrained by exterior boundary conditions and a text prompt to specify the content. By carefully designing and selecting the exterior boundary conditions, we can reformulate the tile generation process as an inpainting problem, allowing us to directly employ existing diffusion-based inpainting models without the need to retrain a model on a custom training set. We demonstrate the flexibility and efficacy of our content-aware tile generation method on different tiling schemes, such as Wang tiles, from only a text prompt. Furthermore, we introduce a novel Dual Wang tiling scheme that provides greater texture continuity and diversity than existing Wang tile variants.
DiLightNet: Fine-grained Lighting Control for Diffusion-based Image Generation
Feb 19, 2024



This paper presents a novel method for exerting fine-grained lighting control during text-driven diffusion-based image generation. While existing diffusion models already have the ability to generate images under any lighting condition, without additional guidance these models tend to correlate image content and lighting. Moreover, text prompts lack the necessary expressional power to describe detailed lighting setups. To provide the content creator with fine-grained control over the lighting during image generation, we augment the text-prompt with detailed lighting information in the form of radiance hints, i.e., visualizations of the scene geometry with a homogeneous canonical material under the target lighting. However, the scene geometry needed to produce the radiance hints is unknown. Our key observation is that we only need to guide the diffusion process, hence exact radiance hints are not necessary; we only need to point the diffusion model in the right direction. Based on this observation, we introduce a three stage method for controlling the lighting during image generation. In the first stage, we leverage a standard pretrained diffusion model to generate a provisional image under uncontrolled lighting. Next, in the second stage, we resynthesize and refine the foreground object in the generated image by passing the target lighting to a refined diffusion model, named DiLightNet, using radiance hints computed on a coarse shape of the foreground object inferred from the provisional image. To retain the texture details, we multiply the radiance hints with a neural encoding of the provisional synthesized image before passing it to DiLightNet. Finally, in the third stage, we resynthesize the background to be consistent with the lighting on the foreground object. We demonstrate and validate our lighting controlled diffusion model on a variety of text prompts and lighting conditions.
In the Blink of an Eye: Event-based Emotion Recognition
Oct 06, 2023



We introduce a wearable single-eye emotion recognition device and a real-time approach to recognizing emotions from partial observations of an emotion that is robust to changes in lighting conditions. At the heart of our method is a bio-inspired event-based camera setup and a newly designed lightweight Spiking Eye Emotion Network (SEEN). Compared to conventional cameras, event-based cameras offer a higher dynamic range (up to 140 dB vs. 80 dB) and a higher temporal resolution. Thus, the captured events can encode rich temporal cues under challenging lighting conditions. However, these events lack texture information, posing problems in decoding temporal information effectively. SEEN tackles this issue from two different perspectives. First, we adopt convolutional spiking layers to take advantage of the spiking neural network's ability to decode pertinent temporal information. Second, SEEN learns to extract essential spatial cues from corresponding intensity frames and leverages a novel weight-copy scheme to convey spatial attention to the convolutional spiking layers during training and inference. We extensively validate and demonstrate the effectiveness of our approach on a specially collected Single-eye Event-based Emotion (SEE) dataset. To the best of our knowledge, our method is the first eye-based emotion recognition method that leverages event-based cameras and spiking neural network.
Relighting Neural Radiance Fields with Shadow and Highlight Hints
Aug 25, 2023



This paper presents a novel neural implicit radiance representation for free viewpoint relighting from a small set of unstructured photographs of an object lit by a moving point light source different from the view position. We express the shape as a signed distance function modeled by a multi layer perceptron. In contrast to prior relightable implicit neural representations, we do not disentangle the different reflectance components, but model both the local and global reflectance at each point by a second multi layer perceptron that, in addition, to density features, the current position, the normal (from the signed distace function), view direction, and light position, also takes shadow and highlight hints to aid the network in modeling the corresponding high frequency light transport effects. These hints are provided as a suggestion, and we leave it up to the network to decide how to incorporate these in the final relit result. We demonstrate and validate our neural implicit representation on synthetic and real scenes exhibiting a wide variety of shapes, material properties, and global illumination light transport.
* Accepted to SIGGRAPH 2023. Author's version. Project page: https://nrhints.github.io/
Synthesizing 3D Shapes from Silhouette Image Collections using Multi-projection Generative Adversarial Networks
Jun 10, 2019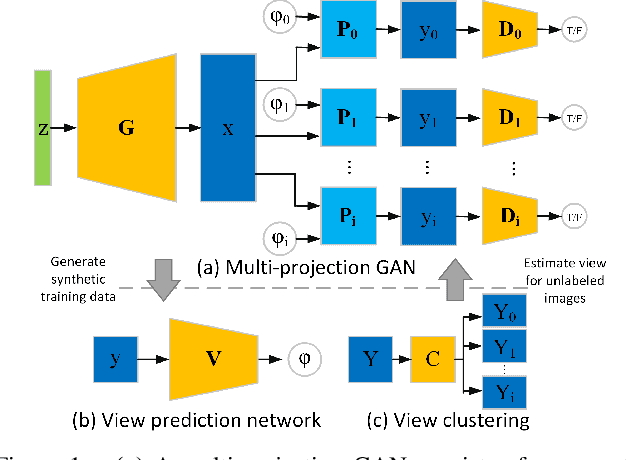

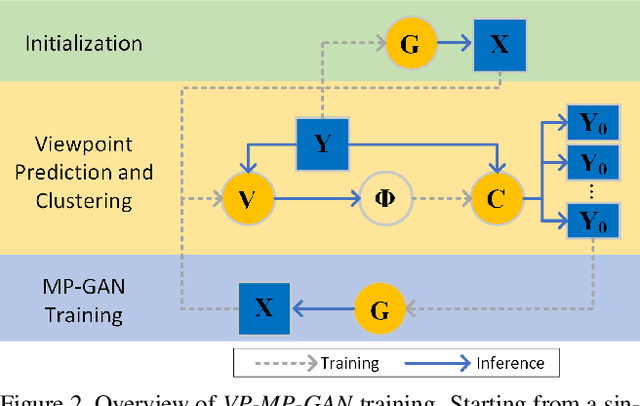

We present a new weakly supervised learning-based method for generating novel category-specific 3D shapes from unoccluded image collections. Our method is weakly supervised and only requires silhouette annotations from unoccluded, category-specific objects. Our method does not require access to the object's 3D shape, multiple observations per object from different views, intra-image pixel-correspondences, or any view annotations. Key to our method is a novel multi-projection generative adversarial network (MP-GAN) that trains a 3D shape generator to be consistent with multiple 2D projections of the 3D shapes, and without direct access to these 3D shapes. This is achieved through multiple discriminators that encode the distribution of 2D projections of the 3D shapes seen from a different views. Additionally, to determine the view information for each silhouette image, we also train a view prediction network on visualizations of 3D shapes synthesized by the generator. We iteratively alternate between training the generator and training the view prediction network. We validate our multi-projection GAN on both synthetic and real image datasets. Furthermore, we also show that multi-projection GANs can aid in learning other high-dimensional distributions from lower dimensional training datasets, such as material-class specific spatially varying reflectance properties from images.