 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVASA-3D: Lifelike Audio-Driven Gaussian Head Avatars from a Single Image
Dec 16, 2025We propose VASA-3D, an audio-driven, single-shot 3D head avatar generator. This research tackles two major challenges: capturing the subtle expression details present in real human faces, and reconstructing an intricate 3D head avatar from a single portrait image. To accurately model expression details, VASA-3D leverages the motion latent of VASA-1, a method that yields exceptional realism and vividness in 2D talking heads. A critical element of our work is translating this motion latent to 3D, which is accomplished by devising a 3D head model that is conditioned on the motion latent. Customization of this model to a single image is achieved through an optimization framework that employs numerous video frames of the reference head synthesized from the input image. The optimization takes various training losses robust to artifacts and limited pose coverage in the generated training data. Our experiment shows that VASA-3D produces realistic 3D talking heads that cannot be achieved by prior art, and it supports the online generation of 512x512 free-viewpoint videos at up to 75 FPS, facilitating more immersive engagements with lifelike 3D avatars.
TimelyLLM: Segmented LLM Serving System for Time-sensitive Robotic Applications
Dec 24, 2024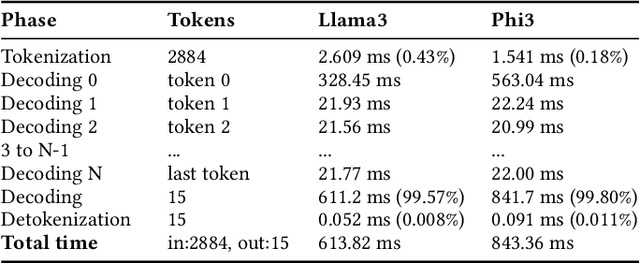
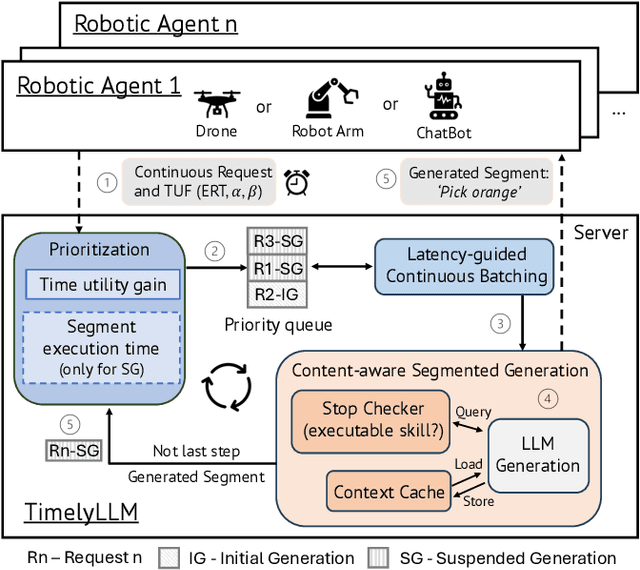
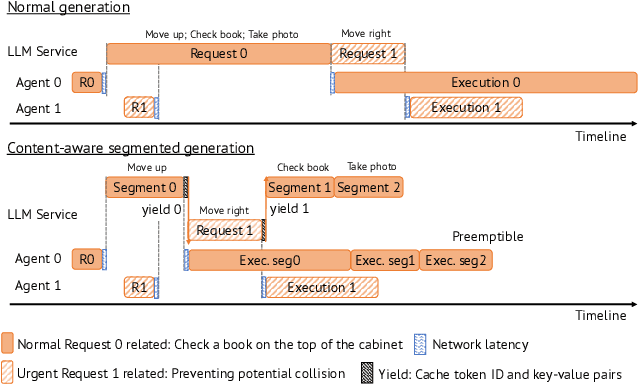
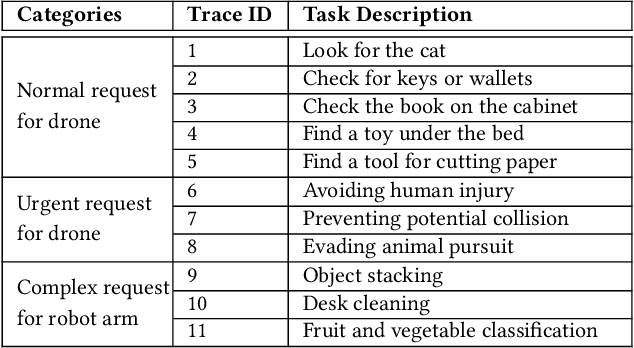
Large Language Models (LLMs) such as GPT-4 and Llama3 can already comprehend complex commands and process diverse tasks. This advancement facilitates their application in controlling drones and robots for various tasks. However, existing LLM serving systems typically employ a first-come, first-served (FCFS) batching mechanism, which fails to address the time-sensitive requirements of robotic applications. To address it, this paper proposes a new system named TimelyLLM serving multiple robotic agents with time-sensitive requests. TimelyLLM introduces novel mechanisms of segmented generation and scheduling that optimally leverage redundancy between robot plan generation and execution phases. We report an implementation of TimelyLLM on a widely-used LLM serving framework and evaluate it on a range of robotic applications. Our evaluation shows that TimelyLLM improves the time utility up to 1.97x, and reduces the overall waiting time by 84%.
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
Apr 16, 2024



We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos. Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method not only delivers high video quality with realistic facial and head dynamics but also supports the online generation of 512x512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
TypeFly: Flying Drones with Large Language Model
Dec 08, 2023Commanding a drone with a natural language is not only user-friendly but also opens the door for emerging language agents to control the drone. Emerging large language models (LLMs) provide a previously impossible opportunity to automatically translate a task description in a natural language to a program that can be executed by the drone. However, powerful LLMs and their vision counterparts are limited in three important ways. First, they are only available as cloud-based services. Sending images to the cloud raises privacy concerns. Second, they are expensive, costing proportionally to the request size. Finally, without expensive fine-tuning, existing LLMs are quite limited in their capability of writing a program for specialized systems like drones. In this paper, we present a system called TypeFly that tackles the above three problems using a combination of edge-based vision intelligence, novel programming language design, and prompt engineering. Instead of the familiar Python, TypeFly gets a cloud-based LLM service to write a program in a small, custom language called MiniSpec, based on task and scene descriptions in English. Such MiniSpec programs are not only succinct (and therefore efficient) but also able to consult the LLM during their execution using a special skill called query. Using a set of increasingly challenging drone tasks, we show that design choices made by TypeFly can reduce both the cost of LLM service and the task execution time by more than 2x. More importantly, query and prompt engineering techniques contributed by TypeFly significantly improve the chance of success of complex tasks.
Prompt Cache: Modular Attention Reuse for Low-Latency Inference
Nov 07, 2023



We present Prompt Cache, an approach for accelerating inference for large language models (LLM) by reusing attention states across different LLM prompts. Many input prompts have overlapping text segments, such as system messages, prompt templates, and documents provided for context. Our key insight is that by precomputing and storing the attention states of these frequently occurring text segments on the inference server, we can efficiently reuse them when these segments appear in user prompts. Prompt Cache employs a schema to explicitly define such reusable text segments, called prompt modules. The schema ensures positional accuracy during attention state reuse and provides users with an interface to access cached states in their prompt. Using a prototype implementation, we evaluate Prompt Cache across several LLMs. We show that Prompt Cache significantly reduce latency in time-to-first-token, especially for longer prompts such as document-based question answering and recommendations. The improvements range from 8x for GPU-based inference to 60x for CPU-based inference, all while maintaining output accuracy and without the need for model parameter modifications.
Relighting Neural Radiance Fields with Shadow and Highlight Hints
Aug 25, 2023



This paper presents a novel neural implicit radiance representation for free viewpoint relighting from a small set of unstructured photographs of an object lit by a moving point light source different from the view position. We express the shape as a signed distance function modeled by a multi layer perceptron. In contrast to prior relightable implicit neural representations, we do not disentangle the different reflectance components, but model both the local and global reflectance at each point by a second multi layer perceptron that, in addition, to density features, the current position, the normal (from the signed distace function), view direction, and light position, also takes shadow and highlight hints to aid the network in modeling the corresponding high frequency light transport effects. These hints are provided as a suggestion, and we leave it up to the network to decide how to incorporate these in the final relit result. We demonstrate and validate our neural implicit representation on synthetic and real scenes exhibiting a wide variety of shapes, material properties, and global illumination light transport.
* Accepted to SIGGRAPH 2023. Author's version. Project page: https://nrhints.github.io/
VirtualCube: An Immersive 3D Video Communication System
Dec 29, 2021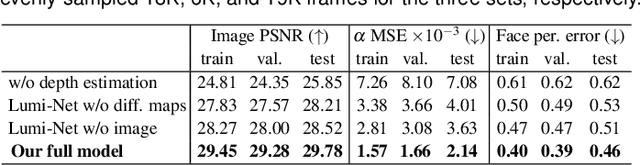
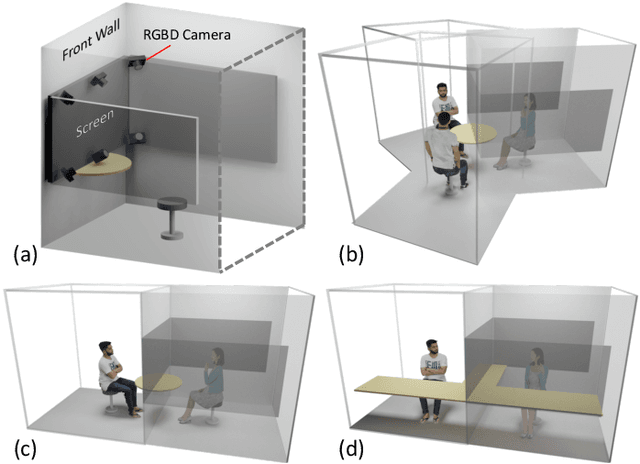

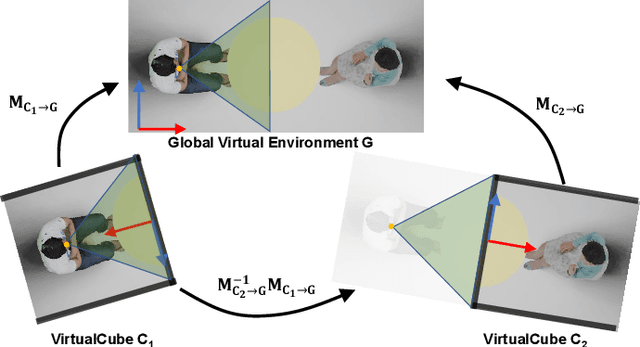
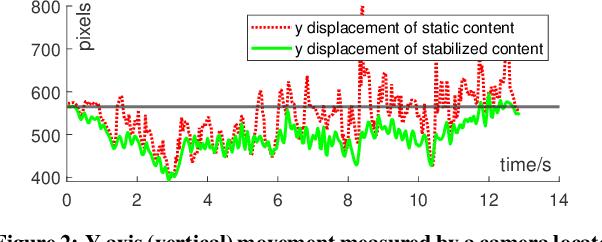
The VirtualCube system is a 3D video conference system that attempts to overcome some limitations of conventional technologies. The key ingredient is VirtualCube, an abstract representation of a real-world cubicle instrumented with RGBD cameras for capturing the 3D geometry and texture of a user. We design VirtualCube so that the task of data capturing is standardized and significantly simplified, and everything can be built using off-the-shelf hardware. We use VirtualCubes as the basic building blocks of a virtual conferencing environment, and we provide each VirtualCube user with a surrounding display showing life-size videos of remote participants. To achieve real-time rendering of remote participants, we develop the V-Cube View algorithm, which uses multi-view stereo for more accurate depth estimation and Lumi-Net rendering for better rendering quality. The VirtualCube system correctly preserves the mutual eye gaze between participants, allowing them to establish eye contact and be aware of who is visually paying attention to them. The system also allows a participant to have side discussions with remote participants as if they were in the same room. Finally, the system sheds lights on how to support the shared space of work items (e.g., documents and applications) and track the visual attention of participants to work items.
POD: A Smartphone That Flies
May 26, 2021

We present POD, a smartphone that flies, as a new way to achieve hands-free, eyes-up mobile computing. Unlike existing drone-carried user interfaces, POD features a smartphone-sized display and the computing and sensing power of a modern smartphone. We share our experience in building a prototype of POD, discuss the technical challenges facing it, and describe early results toward addressing them.
Object-based Illumination Estimation with Rendering-aware Neural Networks
Aug 06, 2020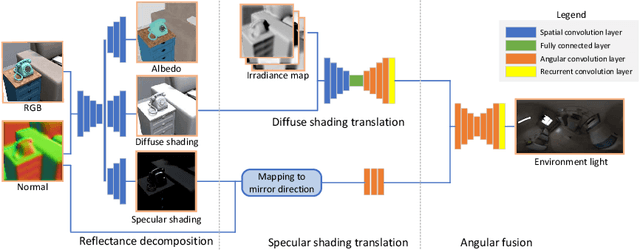
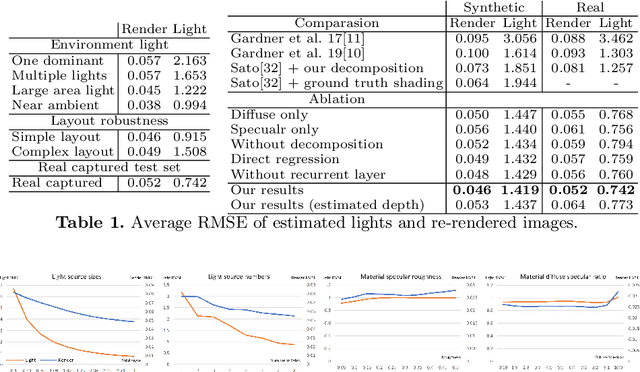


We present a scheme for fast environment light estimation from the RGBD appearance of individual objects and their local image areas. Conventional inverse rendering is too computationally demanding for real-time applications, and the performance of purely learning-based techniques may be limited by the meager input data available from individual objects. To address these issues, we propose an approach that takes advantage of physical principles from inverse rendering to constrain the solution, while also utilizing neural networks to expedite the more computationally expensive portions of its processing, to increase robustness to noisy input data as well as to improve temporal and spatial stability. This results in a rendering-aware system that estimates the local illumination distribution at an object with high accuracy and in real time. With the estimated lighting, virtual objects can be rendered in AR scenarios with shading that is consistent to the real scene, leading to improved realism.
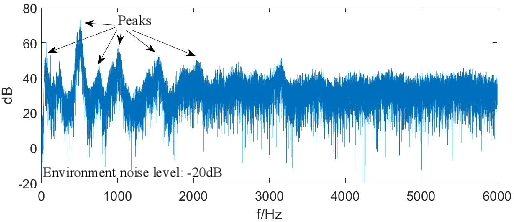
An online supervised learning algorithm based on triple spikes for spiking neural networks
Jan 06, 2019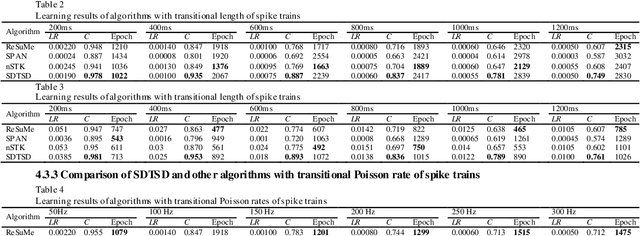
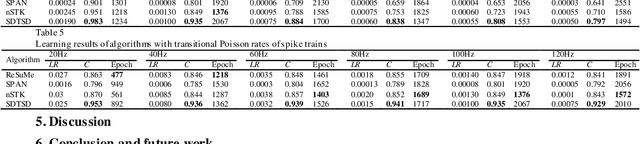
Using precise times of every spike, spiking supervised learning has more effects on complex spatial-temporal pattern than that only through neuronal firing rates. The purpose of spiking supervised learning after temporal encoding is to make neural networks emit desired spike trains with precise firing time. Existing algorithms of spiking supervised learning have excellent performances, but mechanisms of them are most in an offline pattern or still have some problems. Based on an online regulative mechanism of biological neuronal synapses, this paper proposes an online supervised learning algorithm of multiple spike trains for spiking neural networks. The proposed algorithm can make a regulation of weights as soon as firing time of an output spike is obtained. Relationship among desired output, actual output and input spike trains is firstly analyzed and synthesized to select spikes simply and correctly for a direct regulation, and then a computational method is constructed based on simple triple spikes using this direct regulation. Results of experiments show that this online supervised algorithm improves learning performance obviously compared with offline pattern and has higher learning accuracy and efficiency than other learning algorithms.