 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative and Compact Structured Latents for 3D Generation
Dec 16, 2025Recent advancements in 3D generative modeling have significantly improved the generation realism, yet the field is still hampered by existing representations, which struggle to capture assets with complex topologies and detailed appearance. This paper present an approach for learning a structured latent representation from native 3D data to address this challenge. At its core is a new sparse voxel structure called O-Voxel, an omni-voxel representation that encodes both geometry and appearance. O-Voxel can robustly model arbitrary topology, including open, non-manifold, and fully-enclosed surfaces, while capturing comprehensive surface attributes beyond texture color, such as physically-based rendering parameters. Based on O-Voxel, we design a Sparse Compression VAE which provides a high spatial compression rate and a compact latent space. We train large-scale flow-matching models comprising 4B parameters for 3D generation using diverse public 3D asset datasets. Despite their scale, inference remains highly efficient. Meanwhile, the geometry and material quality of our generated assets far exceed those of existing models. We believe our approach offers a significant advancement in 3D generative modeling.
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Jul 03, 2025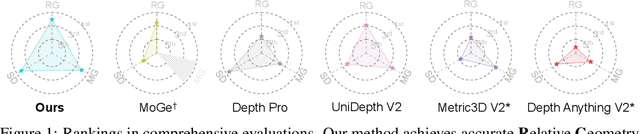
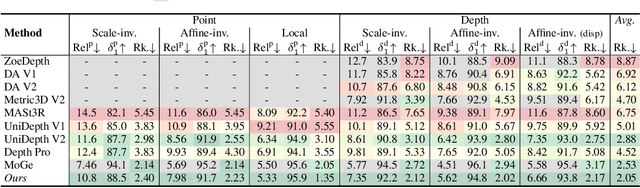
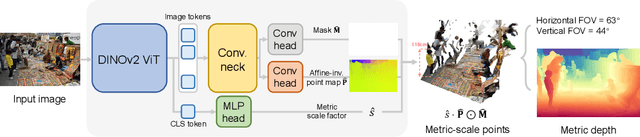
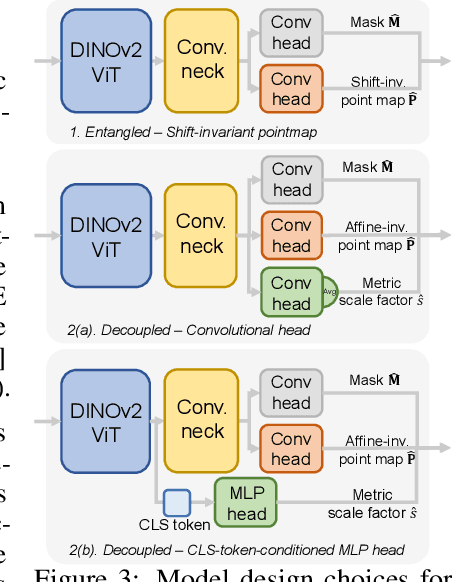
We propose MoGe-2, an advanced open-domain geometry estimation model that recovers a metric scale 3D point map of a scene from a single image. Our method builds upon the recent monocular geometry estimation approach, MoGe, which predicts affine-invariant point maps with unknown scales. We explore effective strategies to extend MoGe for metric geometry prediction without compromising the relative geometry accuracy provided by the affine-invariant point representation. Additionally, we discover that noise and errors in real data diminish fine-grained detail in the predicted geometry. We address this by developing a unified data refinement approach that filters and completes real data from different sources using sharp synthetic labels, significantly enhancing the granularity of the reconstructed geometry while maintaining the overall accuracy. We train our model on a large corpus of mixed datasets and conducted comprehensive evaluations, demonstrating its superior performance in achieving accurate relative geometry, precise metric scale, and fine-grained detail recovery -- capabilities that no previous methods have simultaneously achieved.
Populating cellular metamaterials on the extrema of attainable elasticity through neuroevolution
Dec 17, 2024



The trade-offs between different mechanical properties of materials pose fundamental challenges in engineering material design, such as balancing stiffness versus toughness, weight versus energy-absorbing capacity, and among the various elastic coefficients. Although gradient-based topology optimization approaches have been effective in finding specific designs and properties, they are not efficient tools for surveying the vast design space of metamaterials, and thus unable to reveal the attainable bound of interdependent material properties. Other common methods, such as parametric design or data-driven approaches, are limited by either the lack of diversity in geometry or the difficulty to extrapolate from known data, respectively. In this work, we formulate the simultaneous exploration of multiple competing material properties as a multi-objective optimization (MOO) problem and employ a neuroevolution algorithm to efficiently solve it. The Compositional Pattern-Producing Networks (CPPNs) is used as the generative model for unit cell designs, which provide very compact yet lossless encoding of geometry. A modified Neuroevolution of Augmenting Topologies (NEAT) algorithm is employed to evolve the CPPNs such that they create metamaterial designs on the Pareto front of the MOO problem, revealing empirical bounds of different combinations of elastic properties. Looking ahead, our method serves as a universal framework for the computational discovery of diverse metamaterials across a range of fields, including robotics, biomedicine, thermal engineering, and photonics.
Structured 3D Latents for Scalable and Versatile 3D Generation
Dec 02, 2024



We introduce a novel 3D generation method for versatile and high-quality 3D asset creation. The cornerstone is a unified Structured LATent (SLAT) representation which allows decoding to different output formats, such as Radiance Fields, 3D Gaussians, and meshes. This is achieved by integrating a sparsely-populated 3D grid with dense multiview visual features extracted from a powerful vision foundation model, comprehensively capturing both structural (geometry) and textural (appearance) information while maintaining flexibility during decoding. We employ rectified flow transformers tailored for SLAT as our 3D generation models and train models with up to 2 billion parameters on a large 3D asset dataset of 500K diverse objects. Our model generates high-quality results with text or image conditions, significantly surpassing existing methods, including recent ones at similar scales. We showcase flexible output format selection and local 3D editing capabilities which were not offered by previous models. Code, model, and data will be released.
MoGe: Unlocking Accurate Monocular Geometry Estimation for Open-Domain Images with Optimal Training Supervision
Oct 24, 2024



We present MoGe, a powerful model for recovering 3D geometry from monocular open-domain images. Given a single image, our model directly predicts a 3D point map of the captured scene with an affine-invariant representation, which is agnostic to true global scale and shift. This new representation precludes ambiguous supervision in training and facilitate effective geometry learning. Furthermore, we propose a set of novel global and local geometry supervisions that empower the model to learn high-quality geometry. These include a robust, optimal, and efficient point cloud alignment solver for accurate global shape learning, and a multi-scale local geometry loss promoting precise local geometry supervision. We train our model on a large, mixed dataset and demonstrate its strong generalizability and high accuracy. In our comprehensive evaluation on diverse unseen datasets, our model significantly outperforms state-of-the-art methods across all tasks, including monocular estimation of 3D point map, depth map, and camera field of view. Code and models will be released on our project page.
Diffusion Models are Geometry Critics: Single Image 3D Editing Using Pre-Trained Diffusion Priors
Mar 18, 2024We propose a novel image editing technique that enables 3D manipulations on single images, such as object rotation and translation. Existing 3D-aware image editing approaches typically rely on synthetic multi-view datasets for training specialized models, thus constraining their effectiveness on open-domain images featuring significantly more varied layouts and styles. In contrast, our method directly leverages powerful image diffusion models trained on a broad spectrum of text-image pairs and thus retain their exceptional generalization abilities. This objective is realized through the development of an iterative novel view synthesis and geometry alignment algorithm. The algorithm harnesses diffusion models for dual purposes: they provide appearance prior by predicting novel views of the selected object using estimated depth maps, and they act as a geometry critic by correcting misalignments in 3D shapes across the sampled views. Our method can generate high-quality 3D-aware image edits with large viewpoint transformations and high appearance and shape consistency with the input image, pushing the boundaries of what is possible with single-image 3D-aware editing.
UniDexGrasp: Universal Robotic Dexterous Grasping via Learning Diverse Proposal Generation and Goal-Conditioned Policy
Mar 02, 2023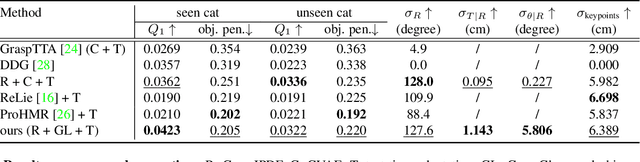
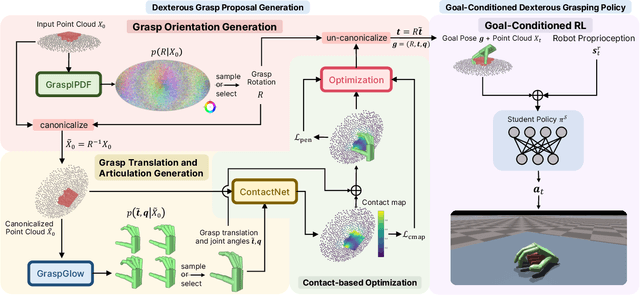
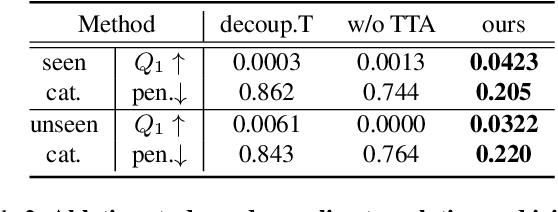
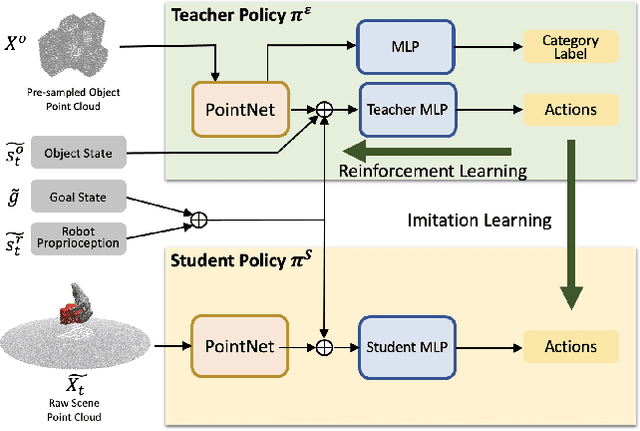
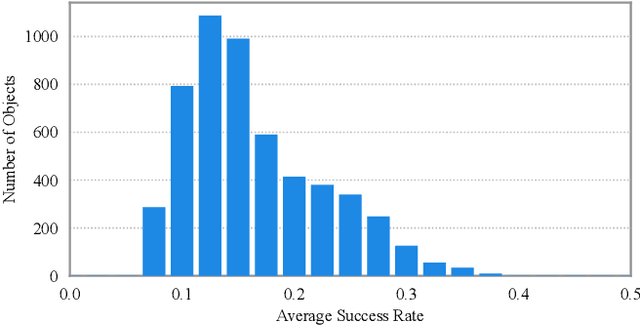
In this work, we tackle the problem of learning universal robotic dexterous grasping from a point cloud observation under a table-top setting. The goal is to grasp and lift up objects in high-quality and diverse ways and generalize across hundreds of categories and even the unseen. Inspired by successful pipelines used in parallel gripper grasping, we split the task into two stages: 1) grasp proposal (pose) generation and 2) goal-conditioned grasp execution. For the first stage, we propose a novel probabilistic model of grasp pose conditioned on the point cloud observation that factorizes rotation from translation and articulation. Trained on our synthesized large-scale dexterous grasp dataset, this model enables us to sample diverse and high-quality dexterous grasp poses for the object in the point cloud. For the second stage, we propose to replace the motion planning used in parallel gripper grasping with a goal-conditioned grasp policy, due to the complexity involved in dexterous grasping execution. Note that it is very challenging to learn this highly generalizable grasp policy that only takes realistic inputs without oracle states. We thus propose several important innovations, including state canonicalization, object curriculum, and teacher-student distillation. Integrating the two stages, our final pipeline becomes the first to achieve universal generalization for dexterous grasping, demonstrating an average success rate of more than 60% on thousands of object instances, which significantly out performs all baselines, meanwhile showing only a minimal generalization gap.
DexGraspNet: A Large-Scale Robotic Dexterous Grasp Dataset for General Objects Based on Simulation
Oct 06, 2022
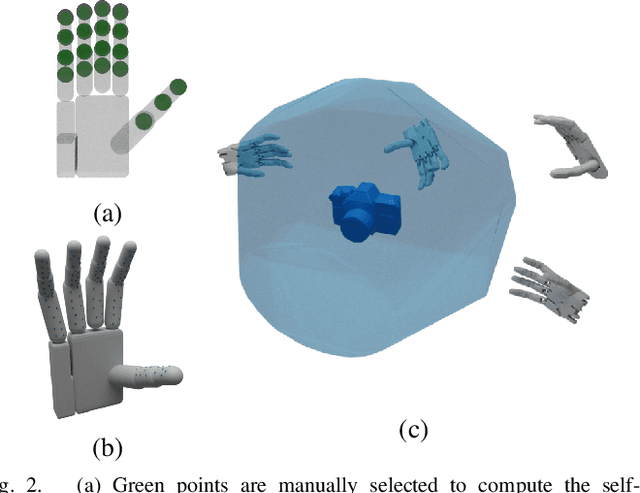

Object grasping using dexterous hands is a crucial yet challenging task for robotic dexterous manipulation. Compared with the field of object grasping with parallel grippers, dexterous grasping is very under-explored, partially owing to the lack of a large-scale dataset. In this work, we present a large-scale simulated dataset, DexGraspNet, for robotic dexterous grasping, along with a highly efficient synthesis method for diverse dexterous grasping synthesis. Leveraging a highly accelerated differentiable force closure estimator, we, for the first time, are able to synthesize stable and diverse grasps efficiently and robustly. We choose ShadowHand, a dexterous gripper commonly seen in robotics, and generated 1.32 million grasps for 5355 objects, covering more than 133 object categories and containing more than 200 diverse grasps for each object instance, with all grasps having been validated by the physics simulator. Compared to the previous dataset generated by GraspIt!, our dataset has not only more objects and grasps, but also higher diversity and quality. Via performing cross-dataset experiments, we show that training several algorithms of dexterous grasp synthesis on our datasets significantly outperforms training on the previous one, demonstrating the large scale and diversity of DexGraspNet. We will release the data and tools upon acceptance.
Single-View View Synthesis in the Wild with Learned Adaptive Multiplane Images
May 24, 2022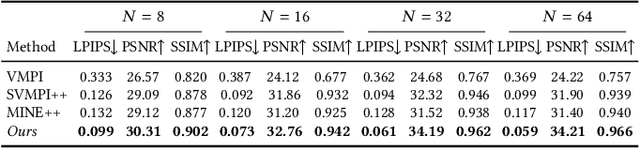
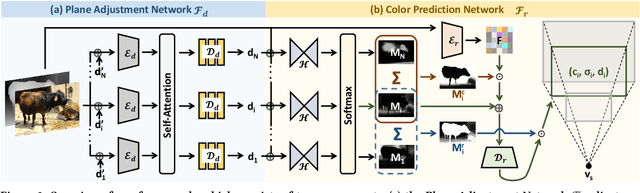

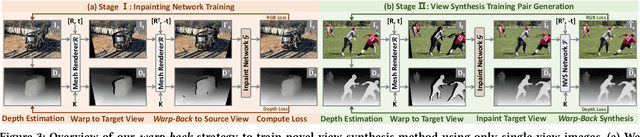
This paper deals with the challenging task of synthesizing novel views for in-the-wild photographs. Existing methods have shown promising results leveraging monocular depth estimation and color inpainting with layered depth representations. However, these methods still have limited capability to handle scenes with complex 3D geometry. We propose a new method based on the multiplane image (MPI) representation. To accommodate diverse scene layouts in the wild and tackle the difficulty in producing high-dimensional MPI contents, we design a network structure that consists of two novel modules, one for plane depth adjustment and another for depth-aware color prediction. The former adjusts the initial plane positions using the RGBD context feature and an attention mechanism. Given adjusted depth values, the latter predicts the color and density for each plane separately with proper inter-plane interactions achieved via a feature masking strategy. To train our method, we construct large-scale stereo training data using only unconstrained single-view image collections by a simple yet effective warp-back strategy. The experiments on both synthetic and real datasets demonstrate that our trained model works remarkably well and achieves state-of-the-art results.
VirtualCube: An Immersive 3D Video Communication System
Dec 29, 2021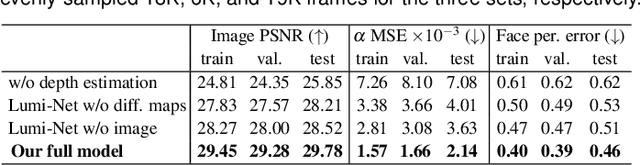
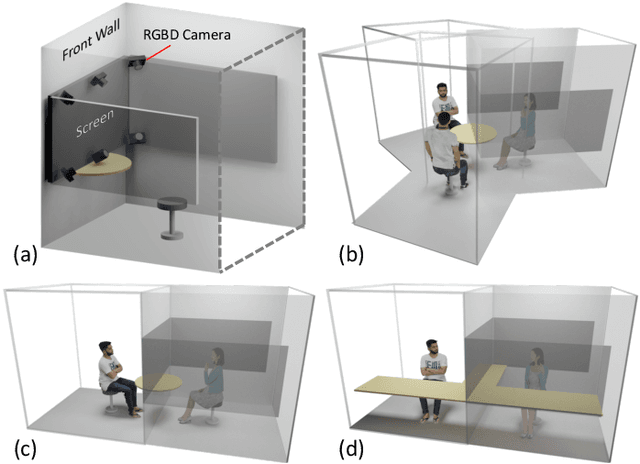

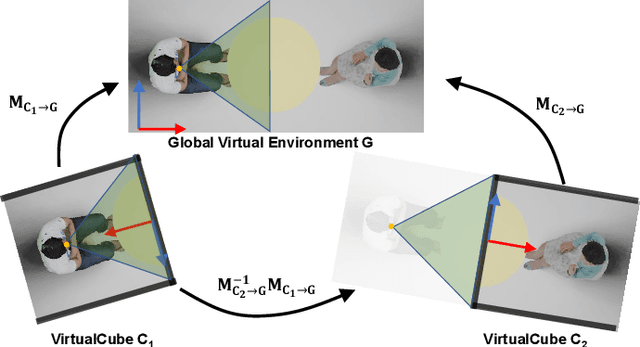
The VirtualCube system is a 3D video conference system that attempts to overcome some limitations of conventional technologies. The key ingredient is VirtualCube, an abstract representation of a real-world cubicle instrumented with RGBD cameras for capturing the 3D geometry and texture of a user. We design VirtualCube so that the task of data capturing is standardized and significantly simplified, and everything can be built using off-the-shelf hardware. We use VirtualCubes as the basic building blocks of a virtual conferencing environment, and we provide each VirtualCube user with a surrounding display showing life-size videos of remote participants. To achieve real-time rendering of remote participants, we develop the V-Cube View algorithm, which uses multi-view stereo for more accurate depth estimation and Lumi-Net rendering for better rendering quality. The VirtualCube system correctly preserves the mutual eye gaze between participants, allowing them to establish eye contact and be aware of who is visually paying attention to them. The system also allows a participant to have side discussions with remote participants as if they were in the same room. Finally, the system sheds lights on how to support the shared space of work items (e.g., documents and applications) and track the visual attention of participants to work items.