 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDexGrasp: Universal Robotic Dexterous Grasping via Learning Diverse Proposal Generation and Goal-Conditioned Policy
Paper and Code
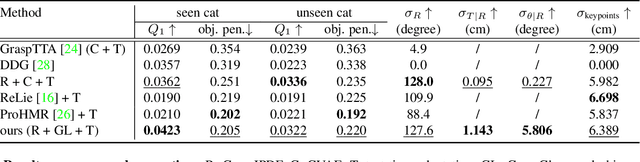
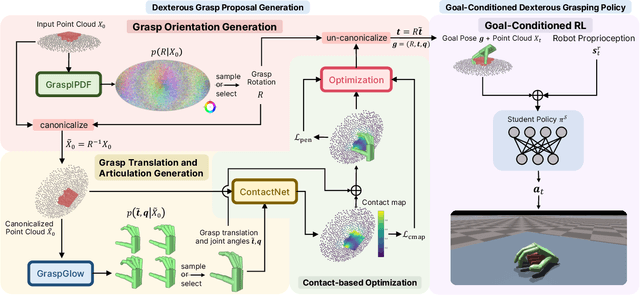
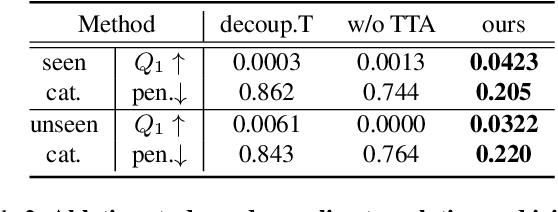
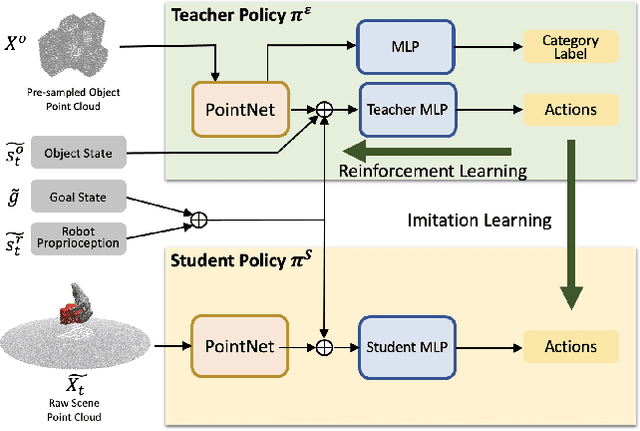
In this work, we tackle the problem of learning universal robotic dexterous grasping from a point cloud observation under a table-top setting. The goal is to grasp and lift up objects in high-quality and diverse ways and generalize across hundreds of categories and even the unseen. Inspired by successful pipelines used in parallel gripper grasping, we split the task into two stages: 1) grasp proposal (pose) generation and 2) goal-conditioned grasp execution. For the first stage, we propose a novel probabilistic model of grasp pose conditioned on the point cloud observation that factorizes rotation from translation and articulation. Trained on our synthesized large-scale dexterous grasp dataset, this model enables us to sample diverse and high-quality dexterous grasp poses for the object in the point cloud. For the second stage, we propose to replace the motion planning used in parallel gripper grasping with a goal-conditioned grasp policy, due to the complexity involved in dexterous grasping execution. Note that it is very challenging to learn this highly generalizable grasp policy that only takes realistic inputs without oracle states. We thus propose several important innovations, including state canonicalization, object curriculum, and teacher-student distillation. Integrating the two stages, our final pipeline becomes the first to achieve universal generalization for dexterous grasping, demonstrating an average success rate of more than 60% on thousands of object instances, which significantly out performs all baselines, meanwhile showing only a minimal generalization gap.