 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Generation of Streamable Talking Portrait Video with Reference-Guided Deep Compression VAEs
Jun 01, 2026Video diffusion models have significantly advanced portrait video generation, yet their high computational demands limit their use in interactive applications. This work presents a framework for streamable talking portrait video generation conditioned on speech audio and reference images. Designed meticulously for streaming scenarios, it features a causal video VAE for deep latent compression and an autoregressive latent denoising model. Our causal VAE integrates a variable number of reference images as guidance, allowing the network to focus on dynamic information rather than static appearance, thereby enhancing compression efficacy and reconstruction quality. Additionally, we extend the residual auto-encoding paradigm to improve spatial-temporal causality handling in our VAE. The generator is based on a Rectified Flow Transformer architecture and produces video latents in a blockwise auto-regressive manner. Our method enables the real-time generation of high-quality talking portrait videos, achieving speeds significantly faster than baseline models. Furthermore, comprehensive experiments demonstrate that it is on par with or even outperforms these large models in realism, vividness, and video quality.
VASA-3D: Lifelike Audio-Driven Gaussian Head Avatars from a Single Image
Dec 16, 2025We propose VASA-3D, an audio-driven, single-shot 3D head avatar generator. This research tackles two major challenges: capturing the subtle expression details present in real human faces, and reconstructing an intricate 3D head avatar from a single portrait image. To accurately model expression details, VASA-3D leverages the motion latent of VASA-1, a method that yields exceptional realism and vividness in 2D talking heads. A critical element of our work is translating this motion latent to 3D, which is accomplished by devising a 3D head model that is conditioned on the motion latent. Customization of this model to a single image is achieved through an optimization framework that employs numerous video frames of the reference head synthesized from the input image. The optimization takes various training losses robust to artifacts and limited pose coverage in the generated training data. Our experiment shows that VASA-3D produces realistic 3D talking heads that cannot be achieved by prior art, and it supports the online generation of 512x512 free-viewpoint videos at up to 75 FPS, facilitating more immersive engagements with lifelike 3D avatars.
ReLKD: Inter-Class Relation Learning with Knowledge Distillation for Generalized Category Discovery
Dec 08, 2025Generalized Category Discovery (GCD) faces the challenge of categorizing unlabeled data containing both known and novel classes, given only labels for known classes. Previous studies often treat each class independently, neglecting the inherent inter-class relations. Obtaining such inter-class relations directly presents a significant challenge in real-world scenarios. To address this issue, we propose ReLKD, an end-to-end framework that effectively exploits implicit inter-class relations and leverages this knowledge to enhance the classification of novel classes. ReLKD comprises three key modules: a target-grained module for learning discriminative representations, a coarse-grained module for capturing hierarchical class relations, and a distillation module for transferring knowledge from the coarse-grained module to refine the target-grained module's representation learning. Extensive experiments on four datasets demonstrate the effectiveness of ReLKD, particularly in scenarios with limited labeled data. The code for ReLKD is available at https://github.com/ZhouF-ECNU/ReLKD.
Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos
Oct 24, 2025



This paper presents a novel approach for pretraining robotic manipulation Vision-Language-Action (VLA) models using a large corpus of unscripted real-life video recordings of human hand activities. Treating human hand as dexterous robot end-effector, we show that "in-the-wild" egocentric human videos without any annotations can be transformed into data formats fully aligned with existing robotic V-L-A training data in terms of task granularity and labels. This is achieved by the development of a fully-automated holistic human activity analysis approach for arbitrary human hand videos. This approach can generate atomic-level hand activity segments and their language descriptions, each accompanied with framewise 3D hand motion and camera motion. We process a large volume of egocentric videos and create a hand-VLA training dataset containing 1M episodes and 26M frames. This training data covers a wide range of objects and concepts, dexterous manipulation tasks, and environment variations in real life, vastly exceeding the coverage of existing robot data. We design a dexterous hand VLA model architecture and pretrain the model on this dataset. The model exhibits strong zero-shot capabilities on completely unseen real-world observations. Additionally, fine-tuning it on a small amount of real robot action data significantly improves task success rates and generalization to novel objects in real robotic experiments. We also demonstrate the appealing scaling behavior of the model's task performance with respect to pretraining data scale. We believe this work lays a solid foundation for scalable VLA pretraining, advancing robots toward truly generalizable embodied intelligence.
Prompt Transfer for Dual-Aspect Cross Domain Cognitive Diagnosis
Dec 06, 2024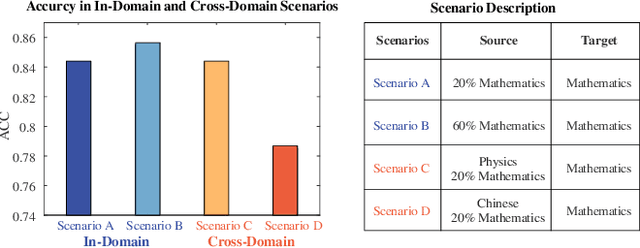
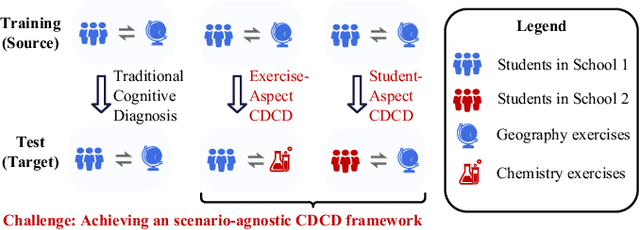
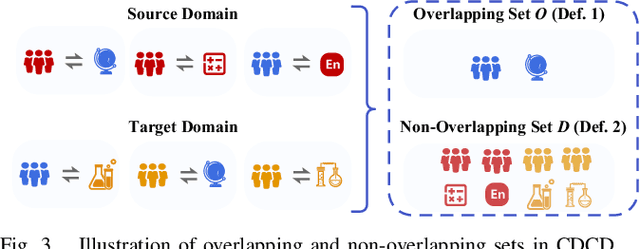
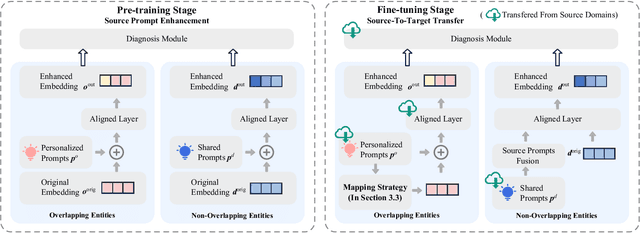
Cognitive Diagnosis (CD) aims to evaluate students' cognitive states based on their interaction data, enabling downstream applications such as exercise recommendation and personalized learning guidance. However, existing methods often struggle with accuracy drops in cross-domain cognitive diagnosis (CDCD), a practical yet challenging task. While some efforts have explored exercise-aspect CDCD, such as crosssubject scenarios, they fail to address the broader dual-aspect nature of CDCD, encompassing both student- and exerciseaspect variations. This diversity creates significant challenges in developing a scenario-agnostic framework. To address these gaps, we propose PromptCD, a simple yet effective framework that leverages soft prompt transfer for cognitive diagnosis. PromptCD is designed to adapt seamlessly across diverse CDCD scenarios, introducing PromptCD-S for student-aspect CDCD and PromptCD-E for exercise-aspect CDCD. Extensive experiments on real-world datasets demonstrate the robustness and effectiveness of PromptCD, consistently achieving superior performance across various CDCD scenarios. Our work offers a unified and generalizable approach to CDCD, advancing both theoretical and practical understanding in this critical domain. The implementation of our framework is publicly available at https://github.com/Publisher-PromptCD/PromptCD.
UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping
Dec 03, 2024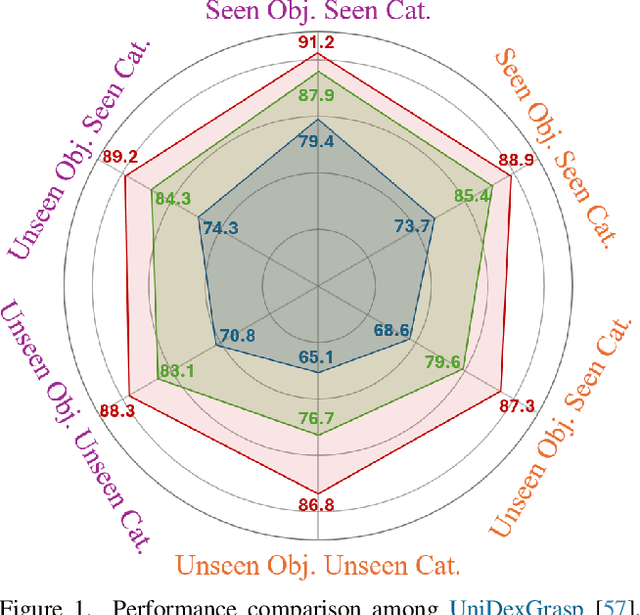

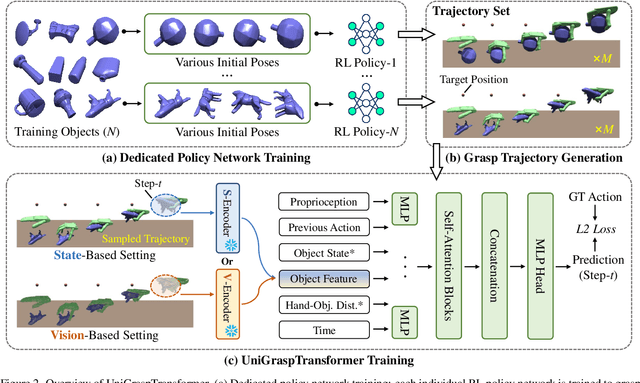

We introduce UniGraspTransformer, a universal Transformer-based network for dexterous robotic grasping that simplifies training while enhancing scalability and performance. Unlike prior methods such as UniDexGrasp++, which require complex, multi-step training pipelines, UniGraspTransformer follows a streamlined process: first, dedicated policy networks are trained for individual objects using reinforcement learning to generate successful grasp trajectories; then, these trajectories are distilled into a single, universal network. Our approach enables UniGraspTransformer to scale effectively, incorporating up to 12 self-attention blocks for handling thousands of objects with diverse poses. Additionally, it generalizes well to both idealized and real-world inputs, evaluated in state-based and vision-based settings. Notably, UniGraspTransformer generates a broader range of grasping poses for objects in various shapes and orientations, resulting in more diverse grasp strategies. Experimental results demonstrate significant improvements over state-of-the-art, UniDexGrasp++, across various object categories, achieving success rate gains of 3.5%, 7.7%, and 10.1% on seen objects, unseen objects within seen categories, and completely unseen objects, respectively, in the vision-based setting. Project page: https://dexhand.github.io/UniGraspTransformer.
CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation
Nov 29, 2024



The advancement of large Vision-Language-Action (VLA) models has significantly improved robotic manipulation in terms of language-guided task execution and generalization to unseen scenarios. While existing VLAs adapted from pretrained large Vision-Language-Models (VLM) have demonstrated promising generalizability, their task performance is still unsatisfactory as indicated by the low tasks success rates in different environments. In this paper, we present a new advanced VLA architecture derived from VLM. Unlike previous works that directly repurpose VLM for action prediction by simple action quantization, we propose a omponentized VLA architecture that has a specialized action module conditioned on VLM output. We systematically study the design of the action module and demonstrates the strong performance enhancement with diffusion action transformers for action sequence modeling, as well as their favorable scaling behaviors. We also conduct comprehensive experiments and ablation studies to evaluate the efficacy of our models with varied designs. The evaluation on 5 robot embodiments in simulation and real work shows that our model not only significantly surpasses existing VLAs in task performance and but also exhibits remarkable adaptation to new robots and generalization to unseen objects and backgrounds. It exceeds the average success rates of OpenVLA which has similar model size (7B) with ours by over 35% in simulated evaluation and 55% in real robot experiments. It also outperforms the large RT-2-X model (55B) by 18% absolute success rates in simulation. Code and models can be found on our project page (https://cogact.github.io/).
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
Apr 16, 2024



We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos. Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method not only delivers high video quality with realistic facial and head dynamics but also supports the online generation of 512x512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
RemoteTouch: Enhancing Immersive 3D Video Communication with Hand Touch
Feb 28, 2023



Recent research advance has significantly improved the visual realism of immersive 3D video communication. In this work we present a method to further enhance this immersive experience by adding the hand touch capability ("remote hand clapping"). In our system, each meeting participant sits in front of a large screen with haptic feedback. The local participant can reach his hand out to the screen and perform hand clapping with the remote participant as if the two participants were only separated by a virtual glass. A key challenge in emulating the remote hand touch is the realistic rendering of the participant's hand and arm as the hand touches the screen. When the hand is very close to the screen, the RGBD data required for realistic rendering is no longer available. To tackle this challenge, we present a dual representation of the user's hand. Our dual representation not only preserves the high-quality rendering usually found in recent image-based rendering systems but also allows the hand to reach the screen. This is possible because the dual representation includes both an image-based model and a 3D geometry-based model, with the latter driven by a hand skeleton tracked by a side view camera. In addition, the dual representation provides a distance-based fusion of the image-based and 3D geometry-based models as the hand moves closer to the screen. The result is that the image-based and 3D geometry-based models mutually enhance each other, leading to realistic and seamless rendering. Our experiments demonstrate that our method provides consistent hand contact experience between remote users and improves the immersive experience of 3D video communication.
VirtualCube: An Immersive 3D Video Communication System
Dec 29, 2021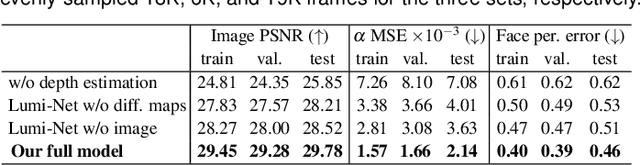
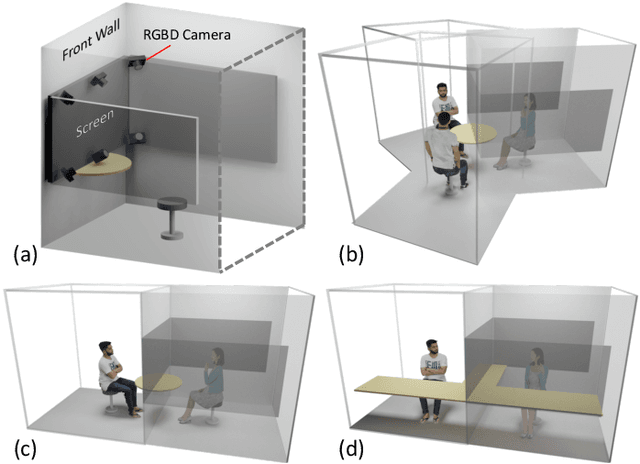

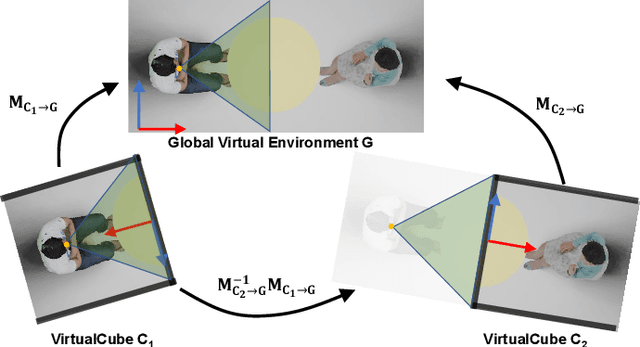
The VirtualCube system is a 3D video conference system that attempts to overcome some limitations of conventional technologies. The key ingredient is VirtualCube, an abstract representation of a real-world cubicle instrumented with RGBD cameras for capturing the 3D geometry and texture of a user. We design VirtualCube so that the task of data capturing is standardized and significantly simplified, and everything can be built using off-the-shelf hardware. We use VirtualCubes as the basic building blocks of a virtual conferencing environment, and we provide each VirtualCube user with a surrounding display showing life-size videos of remote participants. To achieve real-time rendering of remote participants, we develop the V-Cube View algorithm, which uses multi-view stereo for more accurate depth estimation and Lumi-Net rendering for better rendering quality. The VirtualCube system correctly preserves the mutual eye gaze between participants, allowing them to establish eye contact and be aware of who is visually paying attention to them. The system also allows a participant to have side discussions with remote participants as if they were in the same room. Finally, the system sheds lights on how to support the shared space of work items (e.g., documents and applications) and track the visual attention of participants to work items.