 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Generation of Streamable Talking Portrait Video with Reference-Guided Deep Compression VAEs
Jun 01, 2026Video diffusion models have significantly advanced portrait video generation, yet their high computational demands limit their use in interactive applications. This work presents a framework for streamable talking portrait video generation conditioned on speech audio and reference images. Designed meticulously for streaming scenarios, it features a causal video VAE for deep latent compression and an autoregressive latent denoising model. Our causal VAE integrates a variable number of reference images as guidance, allowing the network to focus on dynamic information rather than static appearance, thereby enhancing compression efficacy and reconstruction quality. Additionally, we extend the residual auto-encoding paradigm to improve spatial-temporal causality handling in our VAE. The generator is based on a Rectified Flow Transformer architecture and produces video latents in a blockwise auto-regressive manner. Our method enables the real-time generation of high-quality talking portrait videos, achieving speeds significantly faster than baseline models. Furthermore, comprehensive experiments demonstrate that it is on par with or even outperforms these large models in realism, vividness, and video quality.
Beyond Voxel 3D Editing: Learning from 3D Masks and Self-Constructed Data
Apr 15, 20263D editing refers to the ability to apply local or global modifications to 3D assets. Effective 3D editing requires maintaining semantic consistency by performing localized changes according to prompts, while also preserving local invariance so that unchanged regions remain consistent with the original. However, existing approaches have significant limitations: multi-view editing methods incur losses when projecting back to 3D, while voxel-based editing is constrained in both the regions that can be modified and the scale of modifications. Moreover, the lack of sufficiently large editing datasets for training and evaluation remains a challenge. To address these challenges, we propose a Beyond Voxel 3D Editing (BVE) framework with a self-constructed large-scale dataset specifically tailored for 3D editing. Building upon this dataset, our model enhances a foundational image-to-3D generative architecture with lightweight, trainable modules, enabling efficient injection of textual semantics without the need for expensive full-model retraining. Furthermore, we introduce an annotation-free 3D masking strategy to preserve local invariance, maintaining the integrity of unchanged regions during editing. Extensive experiments demonstrate that BVE achieves superior performance in generating high-quality, text-aligned 3D assets, while faithfully retaining the visual characteristics of the original input.
ProgressVLA: Progress-Guided Diffusion Policy for Vision-Language Robotic Manipulation
Mar 29, 2026Most existing vision-language-action (VLA) models for robotic manipulation lack progress awareness, typically relying on hand-crafted heuristics for task termination. This limitation is particularly severe in long-horizon tasks involving cascaded sub-goals. In this work, we investigate the estimation and integration of task progress, proposing a novel model named {\textbf \vla}. Our technical contributions are twofold: (1) \emph{robust progress estimation}: We pre-train a progress estimator on large-scale, unsupervised video-text robotic datasets. This estimator achieves a low prediction residual (0.07 on a scale of $[0, 1]$) in simulation and demonstrates zero-shot generalization to unseen real-world samples, and (2) \emph{differentiable progress guidance}: We introduce an inverse dynamics world model that maps predicted action tokens into future latent visual states. These latents are then processed by the progress estimator; by applying a maximal progress regularization, we establish a differentiable pipeline that provides progress-piloted guidance to refine action tokens. Extensive experiments on the CALVIN and LIBERO benchmarks, alongside real-world robot deployment, consistently demonstrate substantial improvements in success rates and generalization over strong baselines.
HiSpatial: Taming Hierarchical 3D Spatial Understanding in Vision-Language Models
Mar 26, 2026Achieving human-like spatial intelligence for vision-language models (VLMs) requires inferring 3D structures from 2D observations, recognizing object properties and relations in 3D space, and performing high-level spatial reasoning. In this paper, we propose a principled hierarchical framework that decomposes the learning of 3D spatial understanding in VLMs into four progressively complex levels, from geometric perception to abstract spatial reasoning. Guided by this framework, we construct an automated pipeline that processes approximately 5M images with over 45M objects to generate 3D spatial VQA pairs across diverse tasks and scenes for VLM supervised fine-tuning. We also develop an RGB-D VLM incorporating metric-scale point maps as auxiliary inputs to further enhance spatial understanding. Extensive experiments demonstrate that our approach achieves state-of-the-art performance on multiple spatial understanding and reasoning benchmarks, surpassing specialized spatial models and large proprietary systems such as Gemini-2.5-pro and GPT-5. Moreover, our analysis reveals clear dependencies among hierarchical task levels, offering new insights into how multi-level task design facilitates the emergence of 3D spatial intelligence.
MobileManiBench: Simplifying Model Verification for Mobile Manipulation
Feb 05, 2026Vision-language-action models have advanced robotic manipulation but remain constrained by reliance on the large, teleoperation-collected datasets dominated by the static, tabletop scenes. We propose a simulation-first framework to verify VLA architectures before real-world deployment and introduce MobileManiBench, a large-scale benchmark for mobile-based robotic manipulation. Built on NVIDIA Isaac Sim and powered by reinforcement learning, our pipeline autonomously generates diverse manipulation trajectories with rich annotations (language instructions, multi-view RGB-depth-segmentation images, synchronized object/robot states and actions). MobileManiBench features 2 mobile platforms (parallel-gripper and dexterous-hand robots), 2 synchronized cameras (head and right wrist), 630 objects in 20 categories, 5 skills (open, close, pull, push, pick) with over 100 tasks performed in 100 realistic scenes, yielding 300K trajectories. This design enables controlled, scalable studies of robot embodiments, sensing modalities, and policy architectures, accelerating research on data efficiency and generalization. We benchmark representative VLA models and report insights into perception, reasoning, and control in complex simulated environments.
UniGeM: Unifying Data Mixing and Selection via Geometric Exploration and Mining
Feb 03, 2026The scaling of Large Language Models (LLMs) is increasingly limited by data quality. Most methods handle data mixing and sample selection separately, which can break the structure in code corpora. We introduce \textbf{UniGeM}, a framework that unifies mixing and selection by treating data curation as a \textit{manifold approximation} problem without training proxy models or relying on external reference datasets. UniGeM operates hierarchically: \textbf{Macro-Exploration} learns mixing weights with stability-based clustering; \textbf{Micro-Mining} filters high-quality instances by their geometric distribution to ensure logical consistency. Validated by training 8B and 16B MoE models on 100B tokens, UniGeM achieves \textbf{2.0$\times$ data efficiency} over a random baseline and further improves overall performance compared to SOTA methods in reasoning-heavy evaluations and multilingual generalization.
ESGaussianFace: Emotional and Stylized Audio-Driven Facial Animation via 3D Gaussian Splatting
Jan 05, 2026Most current audio-driven facial animation research primarily focuses on generating videos with neutral emotions. While some studies have addressed the generation of facial videos driven by emotional audio, efficiently generating high-quality talking head videos that integrate both emotional expressions and style features remains a significant challenge. In this paper, we propose ESGaussianFace, an innovative framework for emotional and stylized audio-driven facial animation. Our approach leverages 3D Gaussian Splatting to reconstruct 3D scenes and render videos, ensuring efficient generation of 3D consistent results. We propose an emotion-audio-guided spatial attention method that effectively integrates emotion features with audio content features. Through emotion-guided attention, the model is able to reconstruct facial details across different emotional states more accurately. To achieve emotional and stylized deformations of the 3D Gaussian points through emotion and style features, we introduce two 3D Gaussian deformation predictors. Futhermore, we propose a multi-stage training strategy, enabling the step-by-step learning of the character's lip movements, emotional variations, and style features. Our generated results exhibit high efficiency, high quality, and 3D consistency. Extensive experimental results demonstrate that our method outperforms existing state-of-the-art techniques in terms of lip movement accuracy, expression variation, and style feature expressiveness.
From Indoor to Open World: Revealing the Spatial Reasoning Gap in MLLMs
Dec 22, 2025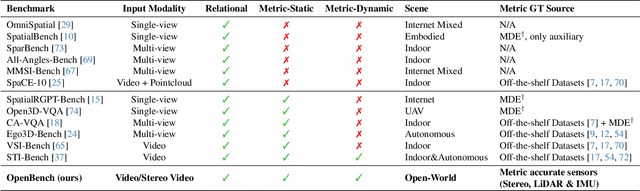

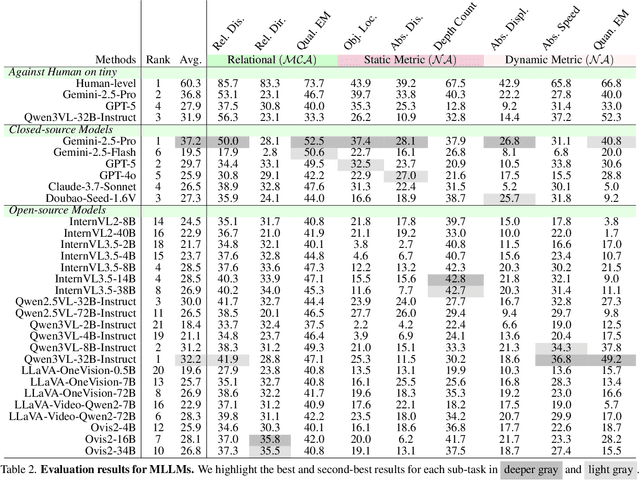
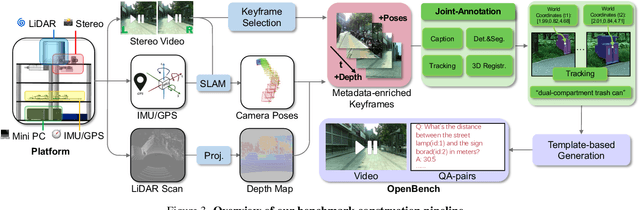
While Multimodal Large Language Models (MLLMs) have achieved impressive performance on semantic tasks, their spatial intelligence--crucial for robust and grounded AI systems--remains underdeveloped. Existing benchmarks fall short of diagnosing this limitation: they either focus on overly simplified qualitative reasoning or rely on domain-specific indoor data, constrained by the lack of outdoor datasets with verifiable metric ground truth. To bridge this gap, we introduce a large-scale benchmark built from pedestrian-perspective videos captured with synchronized stereo cameras, LiDAR, and IMU/GPS sensors. This dataset provides metrically precise 3D information, enabling the automatic generation of spatial reasoning questions that span a hierarchical spectrum--from qualitative relational reasoning to quantitative metric and kinematic understanding. Evaluations reveal that the performance gains observed in structured indoor benchmarks vanish in open-world settings. Further analysis using synthetic abnormal scenes and blinding tests confirms that current MLLMs depend heavily on linguistic priors instead of grounded visual reasoning. Our benchmark thus provides a principled platform for diagnosing these limitations and advancing physically grounded spatial intelligence.
VASA-3D: Lifelike Audio-Driven Gaussian Head Avatars from a Single Image
Dec 16, 2025We propose VASA-3D, an audio-driven, single-shot 3D head avatar generator. This research tackles two major challenges: capturing the subtle expression details present in real human faces, and reconstructing an intricate 3D head avatar from a single portrait image. To accurately model expression details, VASA-3D leverages the motion latent of VASA-1, a method that yields exceptional realism and vividness in 2D talking heads. A critical element of our work is translating this motion latent to 3D, which is accomplished by devising a 3D head model that is conditioned on the motion latent. Customization of this model to a single image is achieved through an optimization framework that employs numerous video frames of the reference head synthesized from the input image. The optimization takes various training losses robust to artifacts and limited pose coverage in the generated training data. Our experiment shows that VASA-3D produces realistic 3D talking heads that cannot be achieved by prior art, and it supports the online generation of 512x512 free-viewpoint videos at up to 75 FPS, facilitating more immersive engagements with lifelike 3D avatars.
Native and Compact Structured Latents for 3D Generation
Dec 16, 2025Recent advancements in 3D generative modeling have significantly improved the generation realism, yet the field is still hampered by existing representations, which struggle to capture assets with complex topologies and detailed appearance. This paper present an approach for learning a structured latent representation from native 3D data to address this challenge. At its core is a new sparse voxel structure called O-Voxel, an omni-voxel representation that encodes both geometry and appearance. O-Voxel can robustly model arbitrary topology, including open, non-manifold, and fully-enclosed surfaces, while capturing comprehensive surface attributes beyond texture color, such as physically-based rendering parameters. Based on O-Voxel, we design a Sparse Compression VAE which provides a high spatial compression rate and a compact latent space. We train large-scale flow-matching models comprising 4B parameters for 3D generation using diverse public 3D asset datasets. Despite their scale, inference remains highly efficient. Meanwhile, the geometry and material quality of our generated assets far exceed those of existing models. We believe our approach offers a significant advancement in 3D generative modeling.