 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswer First, Reason Later: Aligning Search Relevance via Mode-Balanced Reinforcement Learning
Feb 10, 2026Building a search relevance model that achieves both low latency and high performance is a long-standing challenge in the search industry. To satisfy the millisecond-level response requirements of online systems while retaining the interpretable reasoning traces of Large Language Models (LLMs), we propose a novel \textbf{Answer-First, Reason Later (AFRL)} paradigm. This paradigm requires the model to output the definitive relevance score in the very first token, followed by a structured logical explanation. Inspired by the success of reasoning models, we adopt a "Supervised Fine-Tuning (SFT) + Reinforcement Learning (RL)" pipeline to achieve AFRL. However, directly applying existing RL training often leads to \textbf{mode collapse} in the search relevance task, where the model forgets complex long-tail rules in pursuit of high rewards. From an information theory perspective: RL inherently minimizes the \textbf{Reverse KL divergence}, which tends to seek probability peaks (mode-seeking) and is prone to "reward hacking." On the other hand, SFT minimizes the \textbf{Forward KL divergence}, forcing the model to cover the data distribution (mode-covering) and effectively anchoring expert rules. Based on this insight, we propose a \textbf{Mode-Balanced Optimization} strategy, incorporating an SFT auxiliary loss into Stepwise-GRPO training to balance these two properties. Furthermore, we construct an automated instruction evolution system and a multi-stage curriculum to ensure expert-level data quality. Extensive experiments demonstrate that our 32B teacher model achieves state-of-the-art performance. Moreover, the AFRL architecture enables efficient knowledge distillation, successfully transferring expert-level logic to a 0.6B model, thereby reconciling reasoning depth with deployment latency.
ETR: Outcome-Guided Elastic Trust Regions for Policy Optimization
Jan 07, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an important paradigm for unlocking reasoning capabilities in large language models, exemplified by the success of OpenAI o1 and DeepSeek-R1. Currently, Group Relative Policy Optimization (GRPO) stands as the dominant algorithm in this domain due to its stable training and critic-free efficiency. However, we argue that GRPO suffers from a structural limitation: it imposes a uniform, static trust region constraint across all samples. This design implicitly assumes signal homogeneity, a premise misaligned with the heterogeneous nature of outcome-driven learning, where advantage magnitudes and variances fluctuate significantly. Consequently, static constraints fail to fully exploit high-quality signals while insufficiently suppressing noise, often precipitating rapid entropy collapse. To address this, we propose \textbf{E}lastic \textbf{T}rust \textbf{R}egions (\textbf{ETR}), a dynamic mechanism that aligns optimization constraints with signal quality. ETR constructs a signal-aware landscape through dual-level elasticity: at the micro level, it scales clipping boundaries based on advantage magnitude to accelerate learning from high-confidence paths; at the macro level, it leverages group variance to implicitly allocate larger update budgets to tasks in the optimal learning zone. Extensive experiments on AIME and MATH benchmarks demonstrate that ETR consistently outperforms GRPO, achieving superior accuracy while effectively mitigating policy entropy degradation to ensure sustained exploration.
Seal: Advancing Speech Language Models to be Few-Shot Learners
Jul 20, 2024


Existing auto-regressive language models have demonstrated a remarkable capability to perform a new task with just a few examples in prompt, without requiring any additional training. In order to extend this capability to a multi-modal setting (i.e. speech and language), this paper introduces the Seal model, an abbreviation for speech language model. It incorporates a novel alignment method, in which Kullback-Leibler divergence loss is performed to train a projector that bridges a frozen speech encoder with a frozen language model decoder. The resulting Seal model exhibits robust performance as a few-shot learner on two speech understanding tasks. Additionally, consistency experiments are conducted to validate its robustness on different pre-trained language models.
3D Geometry-aware Deformable Gaussian Splatting for Dynamic View Synthesis
Apr 14, 2024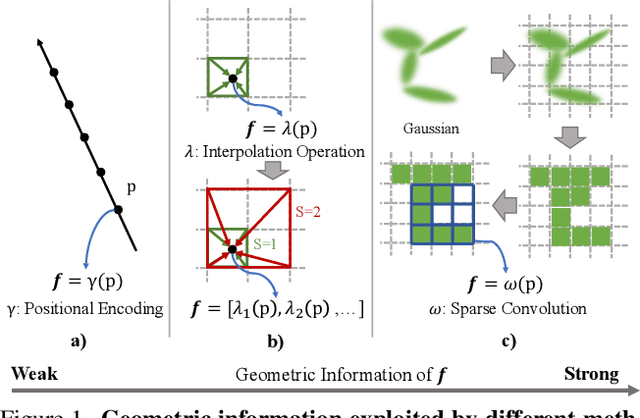
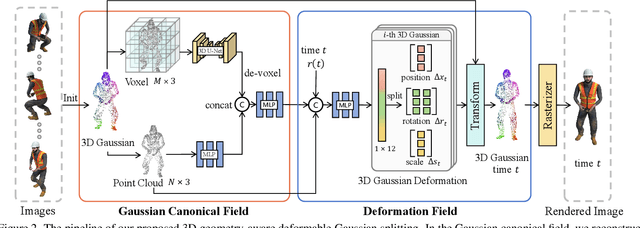
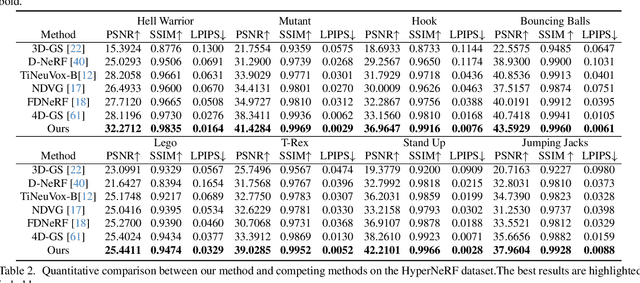
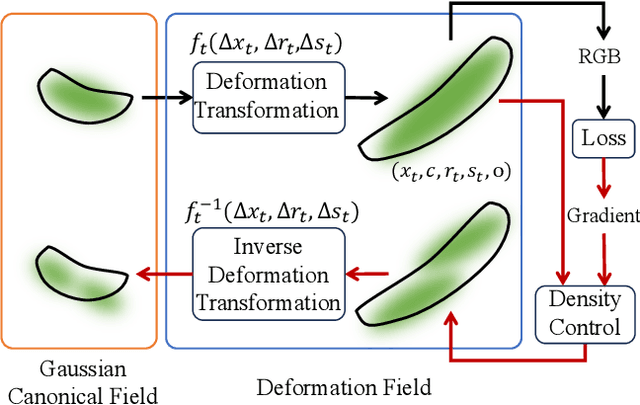
In this paper, we propose a 3D geometry-aware deformable Gaussian Splatting method for dynamic view synthesis. Existing neural radiance fields (NeRF) based solutions learn the deformation in an implicit manner, which cannot incorporate 3D scene geometry. Therefore, the learned deformation is not necessarily geometrically coherent, which results in unsatisfactory dynamic view synthesis and 3D dynamic reconstruction. Recently, 3D Gaussian Splatting provides a new representation of the 3D scene, building upon which the 3D geometry could be exploited in learning the complex 3D deformation. Specifically, the scenes are represented as a collection of 3D Gaussian, where each 3D Gaussian is optimized to move and rotate over time to model the deformation. To enforce the 3D scene geometry constraint during deformation, we explicitly extract 3D geometry features and integrate them in learning the 3D deformation. In this way, our solution achieves 3D geometry-aware deformation modeling, which enables improved dynamic view synthesis and 3D dynamic reconstruction. Extensive experimental results on both synthetic and real datasets prove the superiority of our solution, which achieves new state-of-the-art performance. The project is available at https://npucvr.github.io/GaGS/
Forward Flow for Novel View Synthesis of Dynamic Scenes
Sep 29, 2023



This paper proposes a neural radiance field (NeRF) approach for novel view synthesis of dynamic scenes using forward warping. Existing methods often adopt a static NeRF to represent the canonical space, and render dynamic images at other time steps by mapping the sampled 3D points back to the canonical space with the learned backward flow field. However, this backward flow field is non-smooth and discontinuous, which is difficult to be fitted by commonly used smooth motion models. To address this problem, we propose to estimate the forward flow field and directly warp the canonical radiance field to other time steps. Such forward flow field is smooth and continuous within the object region, which benefits the motion model learning. To achieve this goal, we represent the canonical radiance field with voxel grids to enable efficient forward warping, and propose a differentiable warping process, including an average splatting operation and an inpaint network, to resolve the many-to-one and one-to-many mapping issues. Thorough experiments show that our method outperforms existing methods in both novel view rendering and motion modeling, demonstrating the effectiveness of our forward flow motion modeling. Project page: https://npucvr.github.io/ForwardFlowDNeRF
* Accepted by ICCV2023 as oral. Project page: https://npucvr.github.io/ForwardFlowDNeRF
GRASS: Unified Generation Model for Speech-to-Semantic Tasks
Sep 11, 2023


This paper explores the instruction fine-tuning technique for speech-to-semantic tasks by introducing a unified end-to-end (E2E) framework that generates target text conditioned on a task-related prompt for audio data. We pre-train the model using large and diverse data, where instruction-speech pairs are constructed via a text-to-speech (TTS) system. Extensive experiments demonstrate that our proposed model achieves state-of-the-art (SOTA) results on many benchmarks covering speech named entity recognition, speech sentiment analysis, speech question answering, and more, after fine-tuning. Furthermore, the proposed model achieves competitive performance in zero-shot and few-shot scenarios. To facilitate future work on instruction fine-tuning for speech-to-semantic tasks, we release our instruction dataset and code.
Neural Deformable Voxel Grid for Fast Optimization of Dynamic View Synthesis
Jun 15, 2022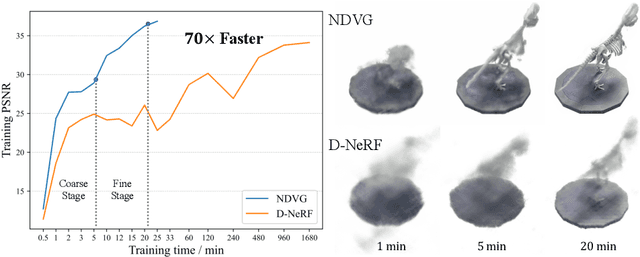

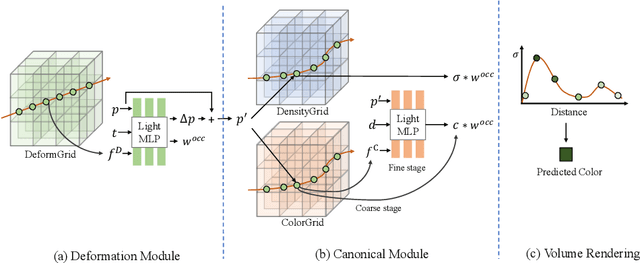

Recently, Neural Radiance Fields (NeRF) is revolutionizing the task of novel view synthesis (NVS) for its superior performance. However, NeRF and its variants generally require a lengthy per-scene training procedure, where a multi-layer perceptron (MLP) is fitted to the captured images. To remedy the challenge, the voxel-grid representation has been proposed to significantly speed up the training. However, these existing methods can only deal with static scenes. How to develop an efficient and accurate dynamic view synthesis method remains an open problem. Extending the methods for static scenes to dynamic scenes is not straightforward as both the scene geometry and appearance change over time. In this paper, built on top of the recent advances in voxel-grid optimization, we propose a fast deformable radiance field method to handle dynamic scenes. Our method consists of two modules. The first module adopts a deformation grid to store 3D dynamic features, and a light-weight MLP for decoding the deformation that maps a 3D point in observation space to the canonical space using the interpolated features. The second module contains a density and a color grid to model the geometry and density of the scene. The occlusion is explicitly modeled to further improve the rendering quality. Experimental results show that our method achieves comparable performance to D-NeRF using only 20 minutes for training, which is more than 70x faster than D-NeRF, clearly demonstrating the efficiency of our proposed method.
Novel View Synthesis from only a 6-DoF Camera Pose by Two-stage Networks
Oct 22, 2020
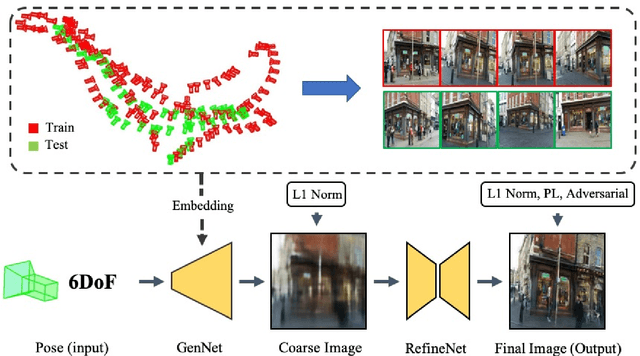


Novel view synthesis is a challenging problem in computer vision and robotics. Different from the existing works, which need the reference images or 3D models of the scene to generate images under novel views, we propose a novel paradigm to this problem. That is, we synthesize the novel view from only a 6-DoF camera pose directly. Although this setting is the most straightforward way, there are few works addressing it. While, our experiments demonstrate that, with a concise CNN, we could get a meaningful parametric model that could reconstruct the correct scenery images only from the 6-DoF pose. To this end, we propose a two-stage learning strategy, which consists of two consecutive CNNs: GenNet and RefineNet. GenNet generates a coarse image from a camera pose. RefineNet is a generative adversarial network that refines the coarse image. In this way, we decouple the geometric relationship between mapping and texture detail rendering. Extensive experiments conducted on the public datasets prove the effectiveness of our method. We believe this paradigm is of high research and application value and could be an important direction in novel view synthesis.
Occluded Joints Recovery in 3D Human Pose Estimation based on Distance Matrix
Jul 30, 2018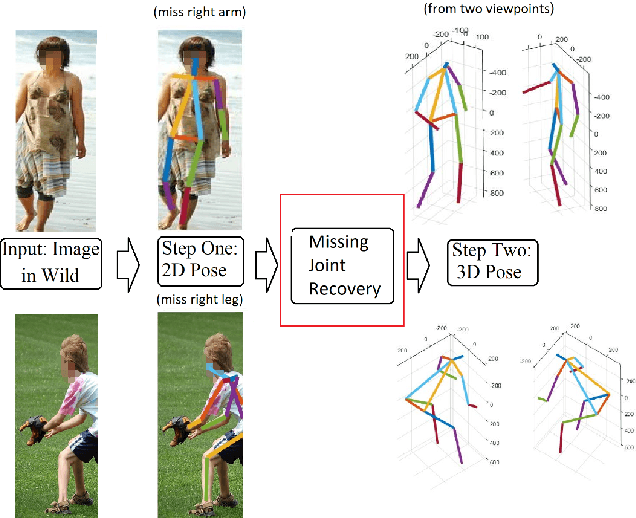
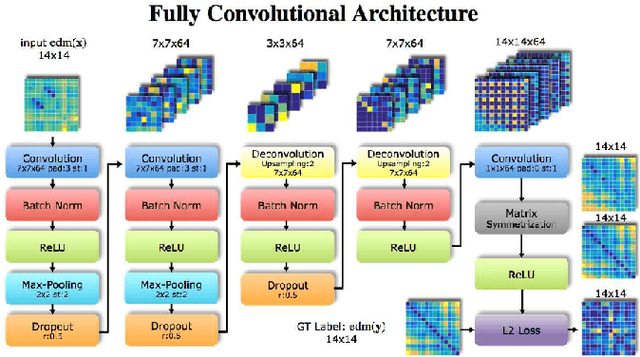
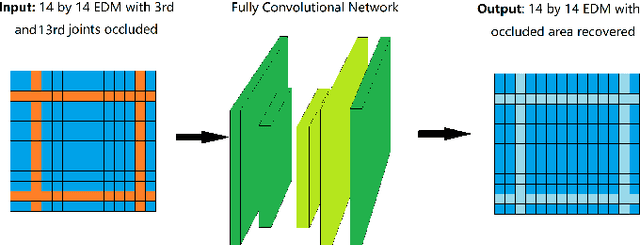
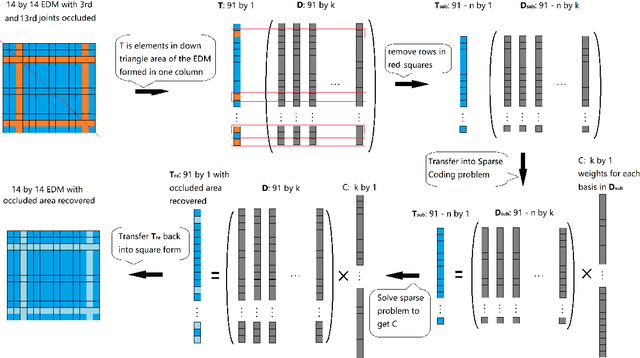
Albeit the recent progress in single image 3D human pose estimation due to the convolutional neural network, it is still challenging to handle real scenarios such as highly occluded scenes. In this paper, we propose to address the problem of single image 3D human pose estimation with occluded measurements by exploiting the Euclidean distance matrix (EDM). Specifically, we present two approaches based on EDM, which could effectively handle occluded joints in 2D images. The first approach is based on 2D-to-2D distance matrix regression achieved by a simple CNN architecture. The second approach is based on sparse coding along with a learned over-complete dictionary. Experiments on the Human3.6M dataset show the excellent performance of these two approaches in recovering occluded observations and demonstrate the improvements in accuracy for 3D human pose estimation with occluded joints.