 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytical Shaping Method for Low-Thrust Rendezvous Trajectory Using Cubic Spline Functions
Jan 01, 2022



Preliminary mission design requires an efficient and accurate approximation to the low-thrust rendezvous trajectories, which might be generally three-dimensional and involve multiple revolutions. In this paper, a new shaping method using cubic spline functions is developed for the analytical approximation, which shows advantages in the optimality and computational efficiency. The rendezvous constraints on the boundary states and transfer time are all satisfied analytically, under the assumption that the boundary conditions and segment numbers of cubic spline functions are designated in advance. Two specific shapes are then formulated according to whether they have free optimization parameters. The shape without free parameters provides an efficient and robust estimation, while the other one allows a subsequent optimization for the satisfaction of additional constraints such as the constraint on the thrust magnitude. Applications of the proposed method in combination with the particle swarm optimization algorithm are discussed through two typical interplanetary rendezvous missions, that is, an inclined multi-revolution trajectory from the Earth to asteroid Dionysus and a multi-rendezvous trajectory of sample return. Simulation examples show that the proposed method is superior to existing methods in terms of providing good estimation for the global search and generating suitable initial guess for the subsequent trajectory optimization.
Novel View Synthesis from only a 6-DoF Camera Pose by Two-stage Networks
Oct 22, 2020
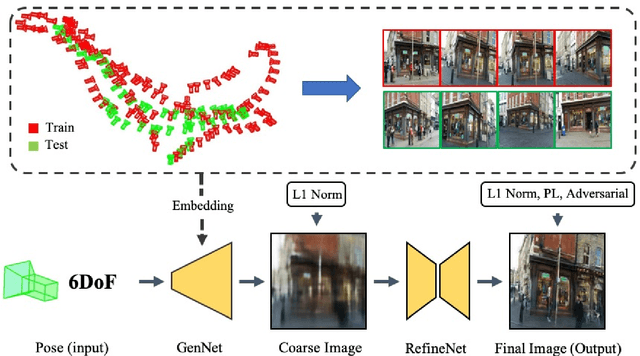


Novel view synthesis is a challenging problem in computer vision and robotics. Different from the existing works, which need the reference images or 3D models of the scene to generate images under novel views, we propose a novel paradigm to this problem. That is, we synthesize the novel view from only a 6-DoF camera pose directly. Although this setting is the most straightforward way, there are few works addressing it. While, our experiments demonstrate that, with a concise CNN, we could get a meaningful parametric model that could reconstruct the correct scenery images only from the 6-DoF pose. To this end, we propose a two-stage learning strategy, which consists of two consecutive CNNs: GenNet and RefineNet. GenNet generates a coarse image from a camera pose. RefineNet is a generative adversarial network that refines the coarse image. In this way, we decouple the geometric relationship between mapping and texture detail rendering. Extensive experiments conducted on the public datasets prove the effectiveness of our method. We believe this paradigm is of high research and application value and could be an important direction in novel view synthesis.