 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Eleventh NTIRE 2026 Efficient Super-Resolution Challenge Report
Apr 03, 2026This paper reviews the NTIRE 2026 challenge on efficient single-image super-resolution with a focus on the proposed solutions and results. The aim of this challenge is to devise a network that reduces one or several aspects, such as runtime, parameters, and FLOPs, while maintaining PSNR of around 26.90 dB on the DIV2K_LSDIR_valid dataset, and 26.99 dB on the DIV2K_LSDIR_test dataset. The challenge had 95 registered participants, and 15 teams made valid submissions. They gauge the state-of-the-art results for efficient single-image super-resolution.
SSR: A Training-Free Approach for Streaming 3D Reconstruction
Mar 16, 2026Streaming 3D reconstruction demands long-horizon state updates under strict latency constraints, yet stateful recurrent models often suffer from geometric drift as errors accumulate over time. We revisit this problem from a Grassmannian manifold perspective: the latent persistent state can be viewed as a subspace representation, i.e., a point evolving on a Grassmannian manifold, where temporal coherence implies the state trajectory should remain on (or near) this manifold.Based on this view, we propose Self-expressive Sequence Regularization (SSR), a plug-and-play, training-free operator that enforces Grassmannian sequence regularity during inference.Given a window of historical states, SSR computes an analytical affinity matrix via the self-expressive property and uses it to regularize the current update, effectively pulling noisy predictions back toward the manifold-consistent trajectory with minimal overhead. Experiments on long-sequence benchmarks demonstrate that SSR consistently reduces drift and improves reconstruction quality across multiple streaming 3D reconstruction tasks.
Autoregressive Image Generation with Linear Complexity: A Spatial-Aware Decay Perspective
Jul 02, 2025Autoregressive (AR) models have garnered significant attention in image generation for their ability to effectively capture both local and global structures within visual data. However, prevalent AR models predominantly rely on the transformer architectures, which are beset by quadratic computational complexity concerning input sequence length and substantial memory overhead due to the necessity of maintaining key-value caches. Although linear attention mechanisms have successfully reduced this burden in language models, our initial experiments reveal that they significantly degrade image generation quality because of their inability to capture critical long-range dependencies in visual data. We propose Linear Attention with Spatial-Aware Decay (LASAD), a novel attention mechanism that explicitly preserves genuine 2D spatial relationships within the flattened image sequences by computing position-dependent decay factors based on true 2D spatial location rather than 1D sequence positions. Based on this mechanism, we present LASADGen, an autoregressive image generator that enables selective attention to relevant spatial contexts with linear complexity. Experiments on ImageNet show LASADGen achieves state-of-the-art image generation performance and computational efficiency, bridging the gap between linear attention's efficiency and spatial understanding needed for high-quality generation.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Evolutionary Morphology Towards Overconstrained Locomotion via Large-Scale, Multi-Terrain Deep Reinforcement Learning
Jul 01, 2024



While the animals' Fin-to-Limb evolution has been well-researched in biology, such morphological transformation remains under-adopted in the modern design of advanced robotic limbs. This paper investigates a novel class of overconstrained locomotion from a design and learning perspective inspired by evolutionary morphology, aiming to integrate the concept of `intelligent design under constraints' - hereafter referred to as constraint-driven design intelligence - in developing modern robotic limbs with superior energy efficiency. We propose a 3D-printable design of robotic limbs parametrically reconfigurable as a classical planar 4-bar linkage, an overconstrained Bennett linkage, and a spherical 4-bar linkage. These limbs adopt a co-axial actuation, identical to the modern legged robot platforms, with the added capability of upgrading into a wheel-legged system. Then, we implemented a large-scale, multi-terrain deep reinforcement learning framework to train these reconfigurable limbs for a comparative analysis of overconstrained locomotion in energy efficiency. Results show that the overconstrained limbs exhibit more efficient locomotion than planar limbs during forward and sideways walking over different terrains, including floors, slopes, and stairs, with or without random noises, by saving at least 22% mechanical energy in completing the traverse task, with the spherical limbs being the least efficient. It also achieves the highest average speed of 0.85 meters per second on flat terrain, which is 20% faster than the planar limbs. This study paves the path for an exciting direction for future research in overconstrained robotics leveraging evolutionary morphology and reconfigurable mechanism intelligence when combined with state-of-the-art methods in deep reinforcement learning.
Non-rigid Structure-from-Motion: Temporally-smooth Procrustean Alignment and Spatially-variant Deformation Modeling
May 07, 2024



Even though Non-rigid Structure-from-Motion (NRSfM) has been extensively studied and great progress has been made, there are still key challenges that hinder their broad real-world applications: 1) the inherent motion/rotation ambiguity requires either explicit camera motion recovery with extra constraint or complex Procrustean Alignment; 2) existing low-rank modeling of the global shape can over-penalize drastic deformations in the 3D shape sequence. This paper proposes to resolve the above issues from a spatial-temporal modeling perspective. First, we propose a novel Temporally-smooth Procrustean Alignment module that estimates 3D deforming shapes and adjusts the camera motion by aligning the 3D shape sequence consecutively. Our new alignment module remedies the requirement of complex reference 3D shape during alignment, which is more conductive to non-isotropic deformation modeling. Second, we propose a spatial-weighted approach to enforce the low-rank constraint adaptively at different locations to accommodate drastic spatially-variant deformation reconstruction better. Our modeling outperform existing low-rank based methods, and extensive experiments across different datasets validate the effectiveness of our method.
A Deep Learning-Driven Pipeline for Differentiating Hypertrophic Cardiomyopathy from Cardiac Amyloidosis Using 2D Multi-View Echocardiography
Apr 25, 2024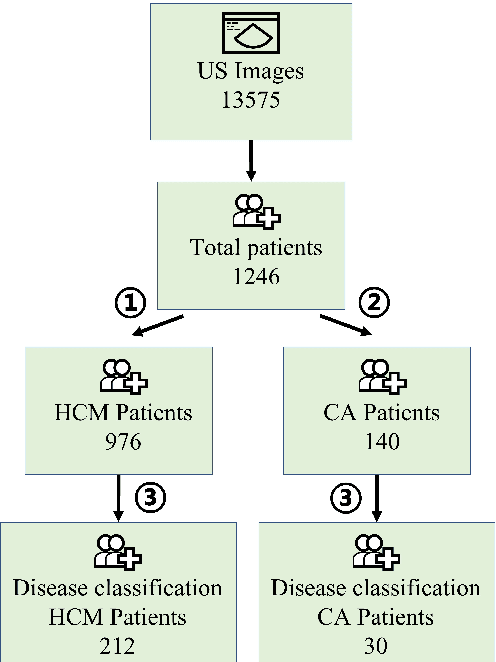

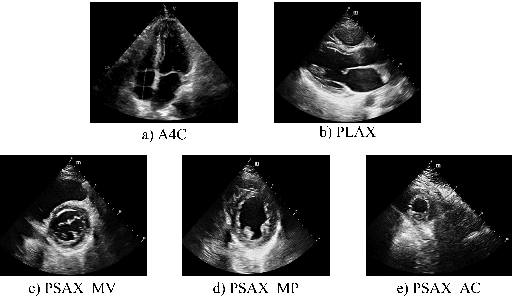

Hypertrophic cardiomyopathy (HCM) and cardiac amyloidosis (CA) are both heart conditions that can progress to heart failure if untreated. They exhibit similar echocardiographic characteristics, often leading to diagnostic challenges. This paper introduces a novel multi-view deep learning approach that utilizes 2D echocardiography for differentiating between HCM and CA. The method begins by classifying 2D echocardiography data into five distinct echocardiographic views: apical 4-chamber, parasternal long axis of left ventricle, parasternal short axis at levels of the mitral valve, papillary muscle, and apex. It then extracts features of each view separately and combines five features for disease classification. A total of 212 patients diagnosed with HCM, and 30 patients diagnosed with CA, along with 200 individuals with normal cardiac function(Normal), were enrolled in this study from 2018 to 2022. This approach achieved a precision, recall of 0.905, and micro-F1 score of 0.904, demonstrating its effectiveness in accurately identifying HCM and CA using a multi-view analysis.
Scientific Preparation for CSST: Classification of Galaxy and Nebula/Star Cluster Based on Deep Learning
Dec 08, 2023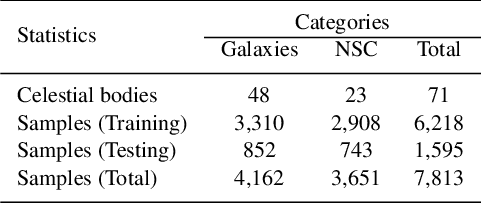


The Chinese Space Station Telescope (abbreviated as CSST) is a future advanced space telescope. Real-time identification of galaxy and nebula/star cluster (abbreviated as NSC) images is of great value during CSST survey. While recent research on celestial object recognition has progressed, the rapid and efficient identification of high-resolution local celestial images remains challenging. In this study, we conducted galaxy and NSC image classification research using deep learning methods based on data from the Hubble Space Telescope. We built a Local Celestial Image Dataset and designed a deep learning model named HR-CelestialNet for classifying images of the galaxy and NSC. HR-CelestialNet achieved an accuracy of 89.09% on the testing set, outperforming models such as AlexNet, VGGNet and ResNet, while demonstrating faster recognition speeds. Furthermore, we investigated the factors influencing CSST image quality and evaluated the generalization ability of HR-CelestialNet on the blurry image dataset, demonstrating its robustness to low image quality. The proposed method can enable real-time identification of celestial images during CSST survey mission.
Unsupervised 3D Pose Estimation with Non-Rigid Structure-from-Motion Modeling
Aug 18, 2023Most of the previous 3D human pose estimation work relied on the powerful memory capability of the network to obtain suitable 2D-3D mappings from the training data. Few works have studied the modeling of human posture deformation in motion. In this paper, we propose a new modeling method for human pose deformations and design an accompanying diffusion-based motion prior. Inspired by the field of non-rigid structure-from-motion, we divide the task of reconstructing 3D human skeletons in motion into the estimation of a 3D reference skeleton, and a frame-by-frame skeleton deformation. A mixed spatial-temporal NRSfMformer is used to simultaneously estimate the 3D reference skeleton and the skeleton deformation of each frame from 2D observations sequence, and then sum them to obtain the pose of each frame. Subsequently, a loss term based on the diffusion model is used to ensure that the pipeline learns the correct prior motion knowledge. Finally, we have evaluated our proposed method on mainstream datasets and obtained superior results outperforming the state-of-the-art.
Exploring Transformer Extrapolation
Jul 19, 2023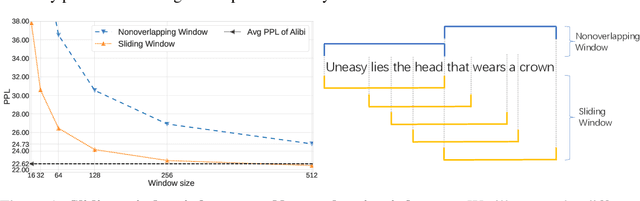

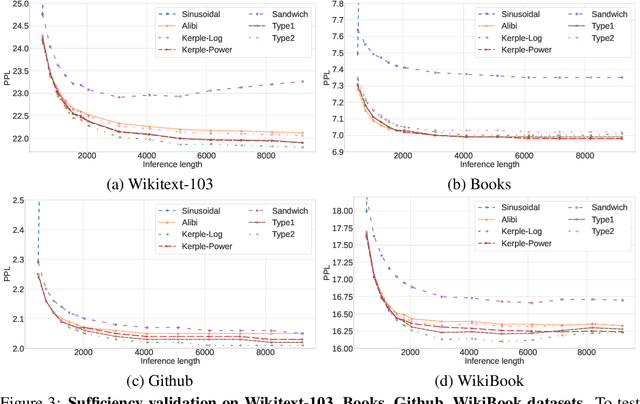
Length extrapolation has attracted considerable attention recently since it allows transformers to be tested on longer sequences than those used in training. Previous research has shown that this property can be attained by using carefully designed Relative Positional Encodings (RPEs). While these methods perform well on a variety of corpora, the conditions for length extrapolation have yet to be investigated. This paper attempts to determine what types of RPEs allow for length extrapolation through a thorough mathematical and empirical analysis. We discover that a transformer is certain to possess this property as long as the series that corresponds to the RPE's exponential converges. Two practices are derived from the conditions and examined in language modeling tasks on a variety of corpora. As a bonus from the conditions, we derive a new Theoretical Receptive Field (TRF) to measure the receptive field of RPEs without taking any training steps. Extensive experiments are conducted on the Wikitext-103, Books, Github, and WikiBook datasets to demonstrate the viability of our discovered conditions. We also compare TRF to Empirical Receptive Field (ERF) across different models, showing consistently matched trends on the aforementioned datasets. The code is available at https://github.com/OpenNLPLab/Rpe.